centos 6.5 搭建zookeeper集群
为什么使用Zookeeper?
大部分分布式应用需要一个主控、协调器或控制器来管理物理分布的子进程(如资源、任务分配等)
目前,大部分应用需要开发私有的协调程序,缺乏一个通用的机制
协调程序的反复编写浪费,且难以形成通用、伸缩性好的协调器
ZooKeeper:提供通用的分布式锁服务,用以协调分布式应用
Zookeeper能帮我们做什么?
Hadoop2.0,使用Zookeeper的事件处理确保整个集群只有一个活跃的NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等.
Zookeeper的特性
Zookeeper是简单的
Zookeeper是富有表现力的
Zookeeper具有高可用性
Zookeeper采用松耦合交互方式
Zookeeper是一个资源库
我们使用三台机器搭建Zookeeper集群
设置ip地址与机器名分别为:
192.168.100.104 hadoop4
192.168.100.105 hadoop5
192.168.100.106 hadoop6
1、 修改机器IP 可以在网络连接中直接使用鼠标操作
2、 修改机器名vim /etc/sysconfig/network 修改如下配置:HOSTNAME=机器名称,HOSTNAME=为你的机器名称,三台机器分别设置为:hadoop4、hadoop5、hadoop6
3、 修改机器名称与IP地址对应关系:vim /etc/hosts
添加如下配置:
192.168.100.104 hadoop4
192.168.100.105 hadoop5
192.168.100.106 hadoop6
4、 上传并解压zookeeper-3.4.5.tar.gz进入zookeeper-3.4.5目录创建zoo.cfg文件使用命令(mv zoo_sample.cfg zoo.cfg)
修改zoo.cfg文件
dataDir=/usr/zookeeper-3.4.5/data
在文件底部添加如下配置:
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
保存退出
zook.cfg文件内容如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/zookeeper/data
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
1.tickTime:CS通信心跳时间
Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。
tickTime=2000
2.initLimit:LF初始通信时限
集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量)。
initLimit=5
3.syncLimit:LF同步通信时限
集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)。
syncLimit=2
4.dataDir:数据文件目录
Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。
dataDir=/usr/zookeeper/data
5.clientPort:客户端连接端口
客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。
clientPort=2181
6.服务器名称与地址:集群信息(服务器编号,服务器地址,LF通信端口,选举端口)
这个配置项的书写格式比较特殊,规则如下:
server.N=YYY:A:B
server.4=hadoop4:2888:3888
server.5=hadoop5:2888:3888
server.6=hadoop6:2888:3888
5、 创建myid文件:在zoo.cfg中设置的dataDir对应的目录中(/usr/zookeeper-3.4.5/data)创建myid文件
并添加如下内容:echo “N” > myid (N为唯一id(最方便可以写机器名称最后一位数字))
添加内容以后:touch myid
注意三台机器都要设置
6、 启动zookeeper进入zookeeper-3.4.5的bin目录:./zkServer.sh start 注意三台机器都要启动
使用 ./zkServer.sh status 可以查看状态,三台机器中有一台会是leader状态其它是follower状态
7、 测试zookeeper
进入zookeeper-3.4.5的bin目录:./zkCli.sh

创建一个文件 create /hadoop123 “123test”
使用另外一台机器登录zookeeper: ./zkCli.sh
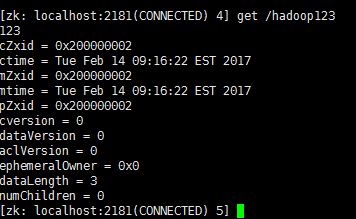
获取hadoop123文件内容:get hadoop123
centos 6.5 搭建zookeeper集群的更多相关文章
- 如何搭建Zookeeper集群
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的 ...
- CentOS 7 环境搭建kafka集群
Kafka是一个MQ服务,流行的MQ服务器有三个,分别是ActiveMQ,RabbbitMQ和Kafka 目录说明:/home/fuqinqin/packages : 安装包存放目录/home/fuq ...
- docker-compose搭建zookeeper集群
搭建zookeeper集群 创建docker-compose.yml文件 ``` version: '3.1' services: zoo1: image: zookeeper restart: al ...
- docker-compose搭建zookeeper集群环境 CodingCode
docker-compose搭建zookeeper集群环境 使用docker-compose搭建zookeeper集群环境 zookeeper是一个集群环境,用来管理微服务架构下面的配置管理功能. 这 ...
- 使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇
使用Cloudera Manager搭建zookeeper集群及HDFS HA实战篇 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.使用Cloudera Manager搭建zo ...
- docker 搭建zookeeper集群和kafka集群
docker 搭建zookeeper集群 安装docker-compose容器编排工具 Compose介绍 Docker Compose 是 Docker 官方编排(Orchestration)项目之 ...
- 搭建zookeeper集群_其中一个报Mode: standalone,另外两个分别是leader和follower
用3个zookeeper搭建一个zookeeper集群,首先配置好一个zookeeper1,其余两个都是按照zookeeper1复制过来,然后稍微修改 运行集群成功,查看zookeeper状态 可以看 ...
- Zookeeper介绍 Zookeeper搭建 Zookeeper集群搭建
关键字:分布式 背景 随着互联网技术的高速发展,企业对计算机系统的技术.存储能力要求越来越高,最简单的证明就是出现了一些诸如:高并发.海量存储这样的词汇.在这样的背景 下,单纯依靠少量 ...
- 大数据平台搭建-zookeeper集群的搭建
本系列文章主要阐述大数据计算平台相关框架的搭建,包括如下内容: 基础环境安装 zookeeper集群的搭建 kafka集群的搭建 hadoop/hbase集群的搭建 spark集群的搭建 flink集 ...
随机推荐
- mongodb 副本集部署
1.安装三节点linux环境:196.168.1.111,196.168.1.112,192.168.1.113(三节点可彼此ping通) 2.三节点安装mongodb,参考https://blog. ...
- Navicat的外键设置
“名”:可以不填,你一会保存成功系统会自动生成. “栏位”:这个子表哪个键设置为外键. “参考数据库”:外键关联的数据库. “参考表”:关联的父表 “参考栏位”:父表关联的的字段,一般是id “删除时 ...
- cxf怎样提高webservice性能,及访问速度调优
性能: 1. 启用FastInfoset(快速信息集)webservice的性能实在是不敢恭维.曾经因为webservice吞吐量上不去,对webservice进行了一些性能方面的优化,采用了Fast ...
- LeetCode解题思路
刷完题后,看一下其他人的solution,受益匪浅. 可以按不同的topic刷题,比如数组.字符串.集合.链表等等.先做十道数组的题,接着再做十道链表的题. 刷题,最主要的是,学习思路. 多刷几遍.挑 ...
- Session和Cookie的理解
原文地址:https://juejin.im/post/5aede266f265da0ba266e0ef
- spring boot 启动错误:Could not resolve placeholder
在启动整个spring boot项目时,出现错误: Could not resolve placeholder 原因:没有指定好配置文件,因为src/main/resources下有多个配置文件,例如 ...
- Django路由配置系统,视图函数
一.路由配置系统(URLconf) URL配置(URLconf)就像Django 所支撑网站的目录.它的本质是URL与要为该URL调用的视图函数之间的映射表:你就是以这种方式告诉Django,对于这个 ...
- 牛客网练习赛43-C(图论)
题目链接:https://ac.nowcoder.com/acm/contest/548/C 题意:有n个知识点,学会每个知识点花T[i],已经学会了其中k个知识点,有m组关系,t1,t2,t3,表示 ...
- 164. Maximum Gap (Array; sort)
Given an unsorted array, find the maximum difference between the successive elements in its sorted f ...
- 如何彻底卸载mysql(xp)
如何彻底卸载mysql 完整的卸载MySQL 5.x 的方法: 1.控制面板里的增加删除程序内进行删除 2.删除MySQL的安装文件夹C:\Program Files\MySQL,如果备份好,可以直接 ...