Hadoop日记Day11---主从节点接口分析
一、NameNode 的接口分析
1. NameNode本质
经过前面的学习,可以知道NameNode 本身就是一个java 进程。观察RPC.getServer()方法的第一个参数,发现是this,说明NameNode 本身就是一个位于服务端的被调用对象,即NameNode 中的方法是可以被客户端代码调用的。根据RPC 运行原理可知,NameNode暴露给客户端的方法是位于接口中的。
我们查看NameNode 的源码,如图1.1所示。
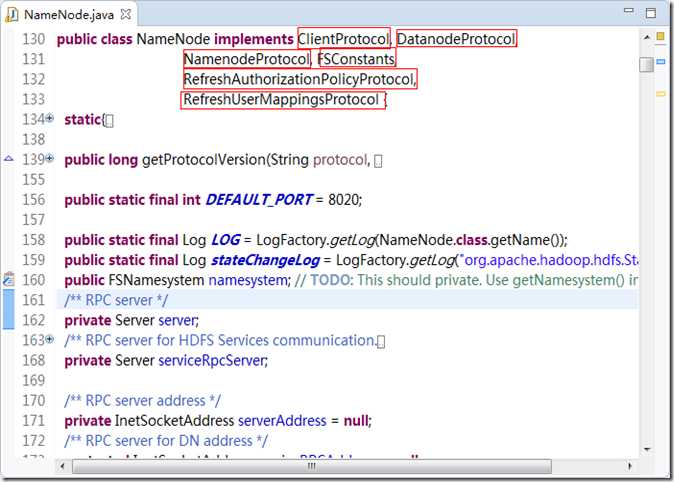
图 1.1
可以看到NameNode 实现了ClientProtocal、DatanodeProtocal、NamenodeProtocal 等接口。
2. NameNode的接口
2.1 DFSClient 调用ClientProtocal
<1> 这个接口是供客户端调用的。这里的客户端不是指的我们自己写的代码,而是hadoop 的一个类叫做DFSClient。在DFSClient 中会调用ClientProtocal 中的方法,完成一些操作。
<2>该接口中的方法大部分是对HDFS 的操作,如create、delete、mkdirs、rename 等。
2.2 DataNode 调用DatanodeProtocal
这个接口是供DataNode 调用的。DataNode 调用该接口中的方法向NameNode 报告本节点的状态和block 信息。NameNode 不能向DataNode 发送消息, 只能通过该接口中方法的返回值向DataNode 传递消息。
2.3 SecondaryNameNode 调用NamenodeProtocal
这个接口是供SecondaryNameNode 调用的。SecondaryNameNode 是专门做NameNode 中edits 文件向fsimage 合并数据的。
二、DataNode 的接口分析
按照分析NameNode 的思路,看一下DataNode 的源码接口,如图2.1 所示。
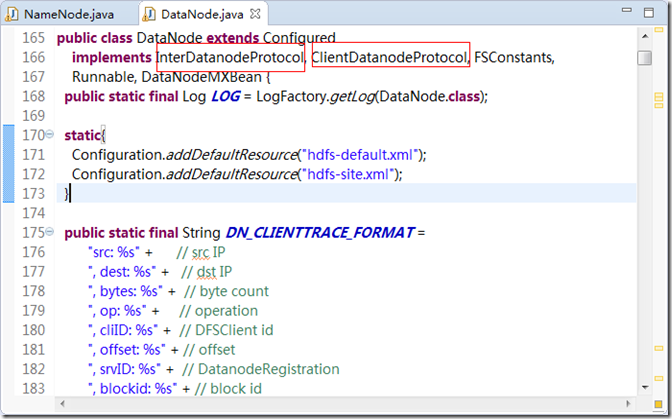
图2.1
这里有两个接口,分别是InterDatanodeProtocal、ClientDatanodeProtocal。这里就不展开分析了。读者可以根据上面的思路独立分析。
三、HDFS的数据处理过程分析
1. HDFS 的写数据过程分析
1.1 通过FileSystem 类可以操控HDFS
那我们就从这里开始分析写数据到HDFS 的过程。在我们向HDFS 写文件的时候,调用的是FileSystem.create(Path path)方法,我们查看这个方法的源码,通过跟踪内部的重载方法,可以找到如图3.1所示的调用。
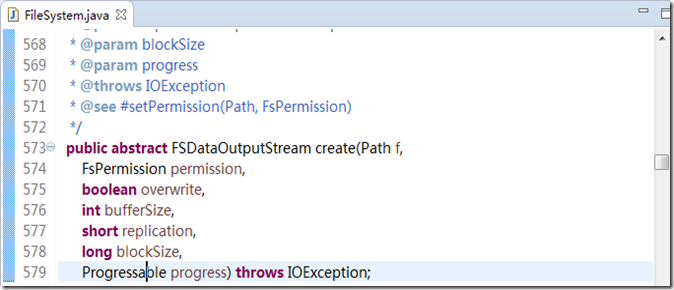
图3.1
这个方法是抽象类,没有实现。那么我们只能向他的子类寻找实现。
1.2 查看DistributedFileSystem类的源码
FileSystem 有个子类是DistributedFileSystem,在我们的伪分布环境下使用的就是这个类。我们可以看到DistributedFileSystem 的这个方法的实现,如图3.2示。
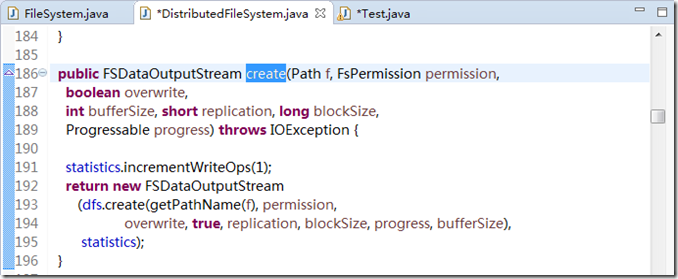
图3.2
在图3.2中,注意第186 行的返回值FSDataOutputStream。这个返回值对象调用了自己的构造方法,构造方法的第一个参数是dfs.create()方法。
1.3 关注一下这里的dfs 对象是谁,create 方法做了什么事情。
现在进入这个方法的实现,如图3.3 所示。
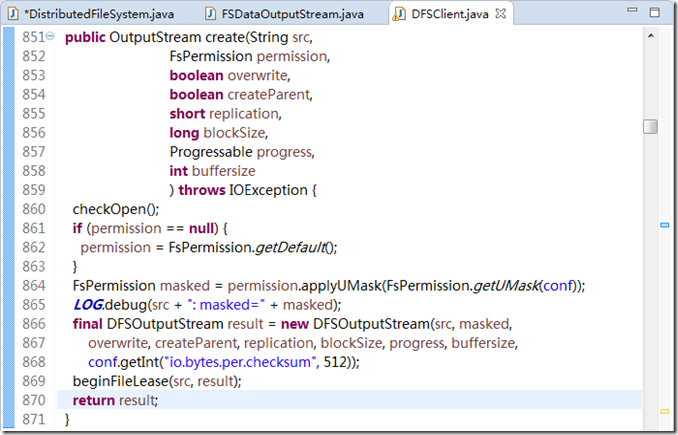
图3.3
在图3.3 中,返回值正是第866行创建的对象。
1.4 查看这个类的源码
如图3.4 所示。
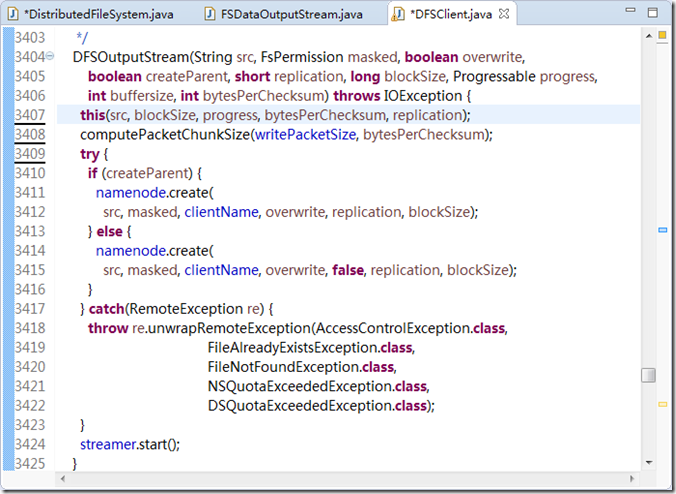
图3.4
在图3.4 中, 可以看到, 这个类是DFSClient 的内部类。在类内部通过调用namenode.create()方法创建了一个输出流。
1.5 我们再看一下namenode 对象是什么类型
如图3.5所示。
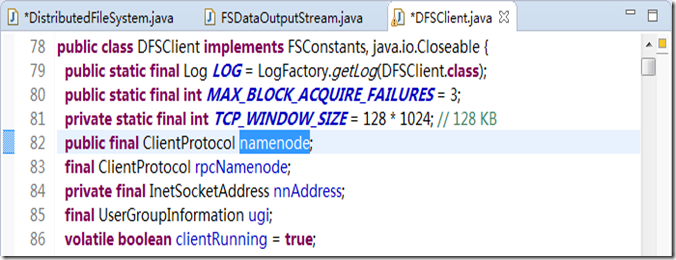
图3.5
在图3.5 中,可以看到namenode 其实是ClientProtocal 接口。
1.6 那么,这个对象是什么时候创建的那?
查看该对象,如图3.6 所示。
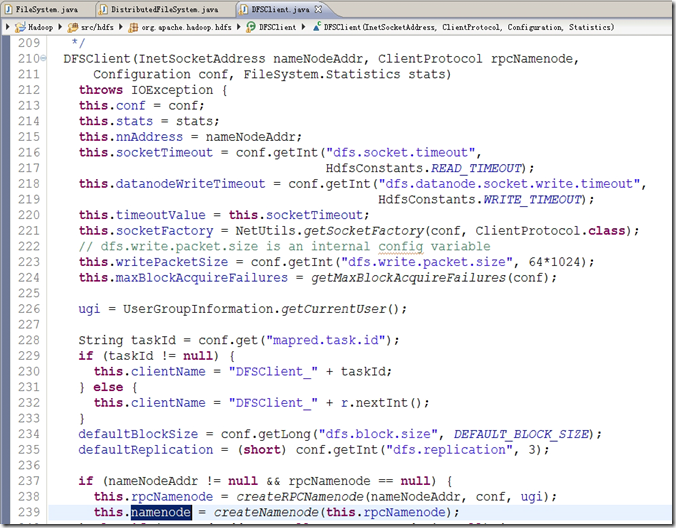
图3.6
可以看出,namenode 对象是在DFSClient 的构造函数调用时创建的,即当DFSClient 对象存在的时候,namenode 对象已经存在了。
1.7 整个调用过程
至此,我们可以看到,使用FileSystem 对象的api 操纵HDFS,其实是通过DFSClient 对象访问NameNode 中的方法操纵HDFS 的。这里的DFSClient 是RPC 机制的客户端,NameNode是RPC 机制的服务端的调用对象,整个调用过程如图3.7所示。
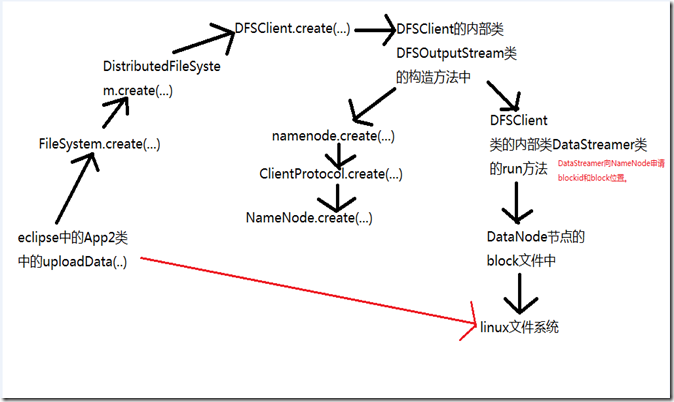
图 3.7
在整个过程中,DFSClient 是个很重要的类,从名称就可以看出,他表示HDFS 的Client,是整个HDFS 的RPC 机制的客户端部分。我们对HDFS 的操作,是通过FileSsytem 调用的DFSClient 里面的方法。FileSystem 是封装了对DFSClient 的操作,提供给用户使用的。
2. HDFS 的读数据过程分析
2.1 对FileSystem 类分析
我们继续对FileSystem 类分析,读数据使用的是open(…)方法,我们可以看到源码,如图3.8 所示。
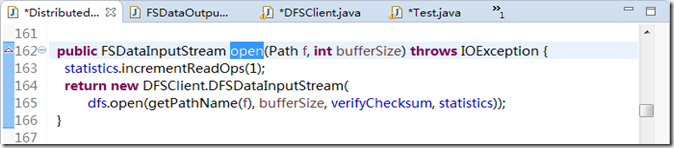
图3.8
在图3.8 中,返回的是DFSClient 类中DFSDataInputStream 类.显而易见,这是一个内部类。
2.2 查看这个内部类的构造方法的源码
这个内部类的构造函数,有两个形参,第一个参数是dfs.open(…)创建的对象。我们看一下方法的源码,如图3.9所示。
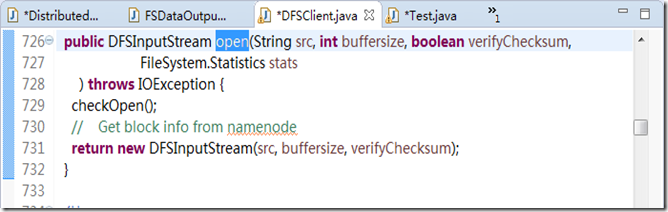
图3.9
在图3.9的实现中,返回的是一个DFSInputStream 对象。
2.3 查看DFSInputStream这个类的构造方法源码
该对象中含有NameNode 中的数据块信息。我们看一下这个类的构造方法源码,如图3.10 所示。
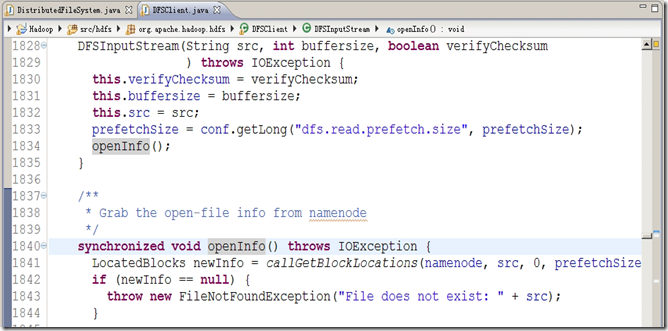
图3.10
2.4 查看获取数据块的信息方法源码
在图3.10中,这个构造方法中最重要的语句是第1836 行,打开信息,从第1842 行开始是openInfo()的源代码,截图显示不全。注意第1841 行,是获取数据块的信息的。我们查看这一行的源代码,如图3.11所示。
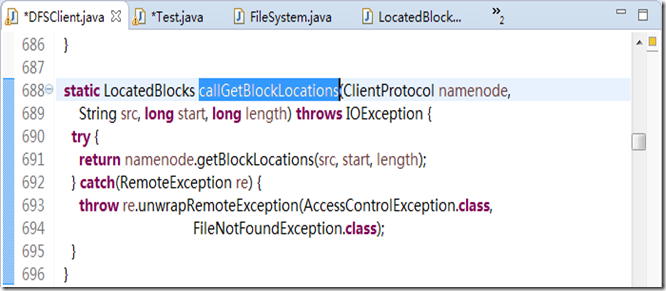
图3.11
从图3.11 中可以看到,获取数据块信息的方法也是通过调用namenode 取得的。这里的namenode 属性还是位于DFSClient 中的。通过前面的分析,我们已经知道,在DFSClient类中的namenode 属性是ClientProtocal。
Hadoop日记Day11---主从节点接口分析的更多相关文章
- Hadoop日记系列目录
下面是Hadoop日记系列的目录,由于目前时间不是很充裕,以后的更新的速度会变慢,会按照一星期发布一期的原则进行,希望能和大家相互学习.交流. 目录安排 1> Hadoop日记Day1---H ...
- Hadoop日记Day1---Hadoop介绍
一.Hadoop项目简介 1. Hadoop是什么 Hadoop是一个适合大数据的分布式存储与计算平台. 作者:Doug Cutting:Lucene,Nutch. 受Google三篇论文的启发 2. ...
- Hadoop 添加删除数据节点(datanode)
前提条件: 添加机器安装jdk等,最好把环境都搞成一样,示例可做相应改动 实现目的: 在hadoop集群中添加一个新增数据节点. 1. 创建目录和用户 mkdir -p /app/hadoop gr ...
- Hadoop记录-Hadoop集群添加节点和删除节点
1.添加节点 A:新节点中添加账户,设置无密码登陆 B:Name节点中设置到新节点的无密码登陆 C:在Name节点slaves文件中添加新节点 D:在所有节点/etc/hosts文件中增加新节点(所有 ...
- 他将Yahoo!Hadoop从20个节点扩展为42000个节点
他将Yahoo!Hadoop从20个节点扩展为42000个节点 http://www.csdn.net/article/2012-11-08/2811629-Interview-Hortonworks ...
- Hadoop新增和删除节点
#新增节点 1.安装lunix,和以前一样的版本 2.初始化系统环境 2.1.设置静态ip vi /etc/sysconfig/network-scripts/ifcfg-eth0 //增加 #Adv ...
- Sentinel系统监控Redis主从节点
author:JevonWei 版权声明:原创作品 blog:http://119.23.52.191/ --- 构建Sentinel监控Redis的主节点架构 拓扑结构结构 拓扑环境 master ...
- Hadoop 分布式环境slave节点重启忽然不好使了
Hadoop 分布式环境slaves节点重启: 忽然无法启动DataNode和NodeManager处理: 在master节点: vim /etc/hosts: 修改slave 节点的IP (这个时候 ...
- redis学习五,redis集群搭建及添加主从节点
redis集群 java架构师项目实战,高并发集群分布式,大数据高可用,视频教程 在redis3.0之前,出现了sentinel工具来监控各个Master的状态(可以看上一篇博客).如果Master异 ...
随机推荐
- VirtualBox安装Mac OS 10.11——虚拟机安装黑苹果
由于需要安装mac环境跑IOS应用,所以在虚拟机装个黑苹果. 一.下载虚拟机安装包,VirtualBox是官网下的最新版: 5.0.6 for Windows hosts x86/amd64 官网 ...
- springcloud 入门 1 (浅谈版本关系)
SpringCloud: 参考官网:https://projects.spring.io/spring-cloud/ 中文版 https://springclou ...
- python SMTP 发送邮件
#!/usr/bin/env/python # -*- coding: utf-8 -*- # @Time : 2018/11/19 9:56 # @Author : ChenAdong # @Ema ...
- Android aapt 工具介绍(转)
目录 AAPT 工具介绍 AAPT 的帮助信息 查看AAPT的版本 使用AAPT列出资源包apk文件列表 使用AAPT打包资源文件 使用AAPT解压资源包apk 来自:http://mmmyddd ...
- h5页面调用摄像头(简易版)
<input type="button" value="OpenVideo" id="btnOpenVideo" /> < ...
- C# socket 发送图片和文件
先说服务端:界面:如图: 界面设计源码 namespace SocketJPGToTxt { partial class Form1 { /// <summary> /// 必需的设计器变 ...
- Linux之JDK1.8的安装
这个最基础的,但是老是查了一次又查,干脆记起来吧. 一.下载jdk8 地址:http://www.oracle.com/technetwork/java/javase/downloads/index. ...
- ansible 增加本机/etc/hosts 下hostsname 与IP
--- - hosts: all vars: IP: "{{ ansible_eth0['ipv4']['address'] }}" tasks: - name: 将原有的host ...
- Python接口自动化--Json数据处理 5
1.Json模块简介,全名JavaScript Object Notation,轻量级的数据交换格式,常用于http请求中. Encoding basic Python object hierarch ...
- HTML DOM item() 方法
一直不知道javascript还有类似jQ里面eq()的函数,原来原生javascript的item()有类似功能: 由于是原生javascript,先补习下children和childNodes的区 ...