cnn的说明
概述
前面的练习中,解决了一些有关低分辨率图像的问题,比如:小块图像,手写数字小幅图像等。在这部分中,我们将把已知的方法扩展到实际应用中更加常见的大图像数据集。
全联通网络
在稀疏自编码章节中,我们介绍了把输入层和隐含层进行“全连接”的设计。从计算的角度来讲,在其他章节中曾经用过的相对较小的图像(如在稀疏自编码的作业中用到过的 8x8 的小块图像,在MNIST数据集中用到过的28x28 的小块图像),从整幅图像中计算特征是可行的。但是,如果是更大的图像(如 96x96 的图像),要通过这种全联通网络的这种方法来学习整幅图像上的特征,从计算角度而言,将变得非常耗时。你需要设计 10 的 4 次方(=10000)个输入单元,假设你要学习 100 个特征,那么就有 10 的 6 次方个参数需要去学习。与 28x28 的小块图像相比较, 96x96 的图像使用前向输送或者后向传导的计算方式,计算过程也会慢 10 的 2 次方(=100)倍。
部分联通网络
解决这类问题的一种简单方法是对隐含单元和输入单元间的连接加以限制:每个隐含单元仅仅只能连接输入单元的一部分。例如,每个隐含单元仅仅连接输入图像的一小片相邻区域。(对于不同于图像输入的输入形式,也会有一些特别的连接到单隐含层的输入信号“连接区域”选择方式。如音频作为一种信号输入方式,一个隐含单元所需要连接的输入单元的子集,可能仅仅是一段音频输入所对应的某个时间段上的信号。)
网络部分连通的思想,也是受启发于生物学里面的视觉系统结构。视觉皮层的神经元就是局部接受信息的(即这些神经元只响应某些特定区域的刺激)。
卷积
自然图像有其固有特性,也就是说,图像的一部分的统计特性与其他部分是一样的。这也意味着我们在这一部分学习的特征也能用在另一部分上,所以对于这个图像上的所有位置,我们都能使用同样的学习特征。
更恰当的解释是,当从一个大尺寸图像中随机选取一小块,比如说 8x8 作为样本,并且从这个小块样本中学习到了一些特征,这时我们可以把从这个 8x8 样本中学习到的特征作为探测器,应用到这个图像的任意地方中去。特别是,我们可以用从 8x8 样本中所学习到的特征跟原本的大尺寸图像作卷积,从而对这个大尺寸图像上的任一位置获得一个不同特征的激活值。
下面给出一个具体的例子:假设你已经从一个 96x96 的图像中学习到了它的一个 8x8 的样本所具有的特征,假设这是由有 100 个隐含单元的自编码完成的。为了得到卷积特征,需要对 96x96 的图像的每个 8x8 的小块图像区域都进行卷积运算。也就是说,抽取 8x8 的小块区域,并且从起始坐标开始依次标记为(1,1),(1,2),...,一直到(89,89),然后对抽取的区域逐个运行训练过的稀疏自编码来得到特征的激活值。在这个例子里,显然可以得到 100 个集合,每个集合含有 89x89 个卷积特征。

假设给定了 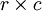 的大尺寸图像,将其定义为 xlarge。首先通过从大尺寸图像中抽取的
的大尺寸图像,将其定义为 xlarge。首先通过从大尺寸图像中抽取的 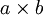 的小尺寸图像样本 xsmall 训练稀疏自编码,计算 f = σ(W(1)xsmall + b(1))(σ 是一个 sigmoid 型函数)得到了 k 个特征, 其中 W(1) 和 b(1) 是可视层单元和隐含单元之间的权重和偏差值。对于每一个 大小的小图像 xs,计算出对应的值 fs = σ(W(1)xs + b(1)),对这些 fconvolved 值做卷积,就可以得到
的小尺寸图像样本 xsmall 训练稀疏自编码,计算 f = σ(W(1)xsmall + b(1))(σ 是一个 sigmoid 型函数)得到了 k 个特征, 其中 W(1) 和 b(1) 是可视层单元和隐含单元之间的权重和偏差值。对于每一个 大小的小图像 xs,计算出对应的值 fs = σ(W(1)xs + b(1)),对这些 fconvolved 值做卷积,就可以得到 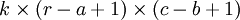 个卷积后的特征的矩阵。
个卷积后的特征的矩阵。
在接下来的章节里,我们会更进一步描述如何把这些特征汇总到一起以得到一些更利于分类的特征。
中英文对照
- 全联通网络 Full Connected Networks
- 稀疏编码 Sparse Autoencoder
- 前向输送 Feedforward
- 反向传播 Backpropagation
- 部分联通网络 Locally Connected Networks
- 连接区域 Contiguous Groups
- 视觉皮层 Visual Cortex
- 卷积 Convolution
- 固有特征 Stationary
- 池化 Pool
池化: 概述
在通过卷积获得了特征 (features) 之后,下一步我们希望利用这些特征去做分类。理论上讲,人们可以用所有提取得到的特征去训练分类器,例如 softmax 分类器,但这样做面临计算量的挑战。例如:对于一个 96X96 像素的图像,假设我们已经学习得到了400个定义在8X8输入上的特征,每一个特征和图像卷积都会得到一个 (96 − 8 + 1) * (96 − 8 + 1) = 7921 维的卷积特征,由于有 400 个特征,所以每个样例 (example) 都会得到一个 892 * 400 = 3,168,400 维的卷积特征向量。学习一个拥有超过 3 百万特征输入的分类器十分不便,并且容易出现过拟合 (over-fitting)。
为了解决这个问题,首先回忆一下,我们之所以决定使用卷积后的特征是因为图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。因此,为了描述大的图像,一个很自然的想法就是对不同位置的特征进行聚合统计,例如,人们可以计算图像一个区域上的某个特定特征的平均值 (或最大值)。这些概要统计特征不仅具有低得多的维度 (相比使用所有提取得到的特征),同时还会改善结果(不容易过拟合)。这种聚合的操作就叫做池化 (pooling),有时也称为平均池化或者最大池化 (取决于计算池化的方法)。
下图显示池化如何应用于一个图像的四块不重合区域。
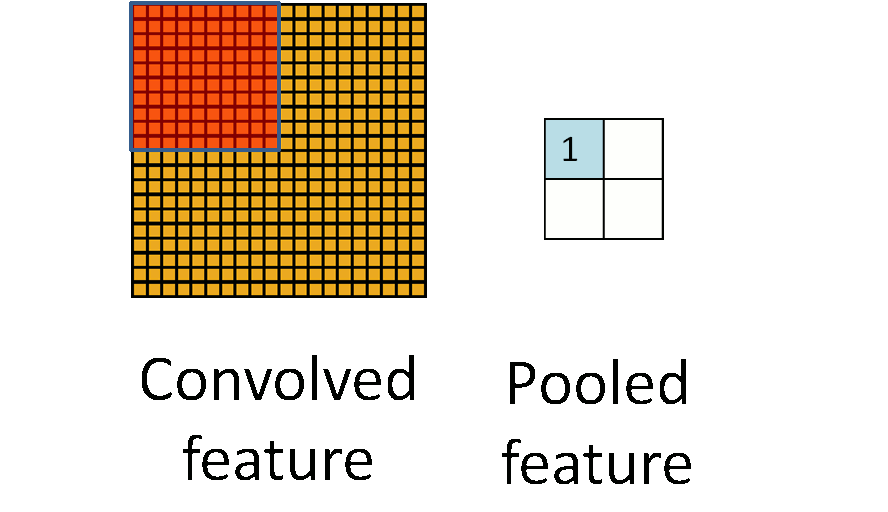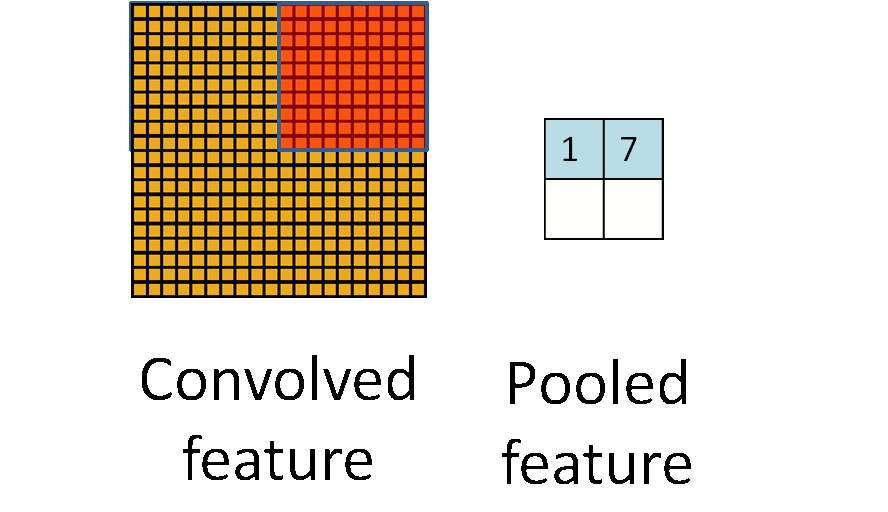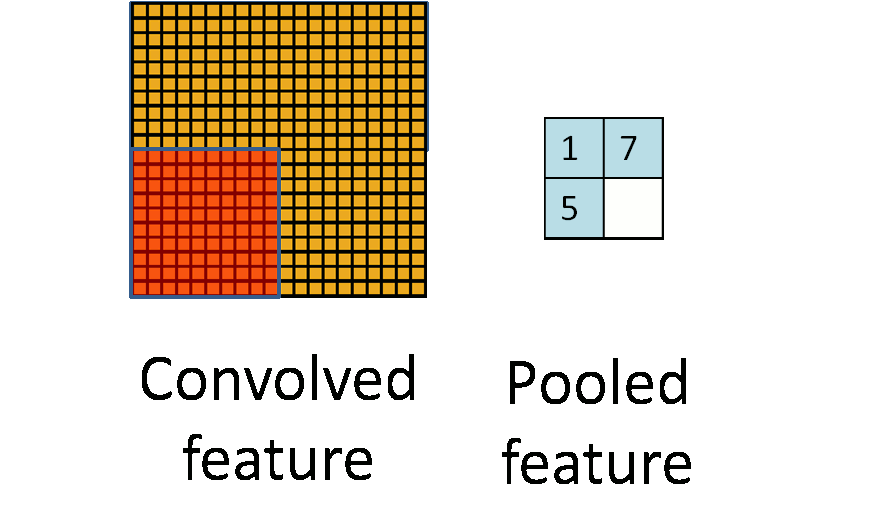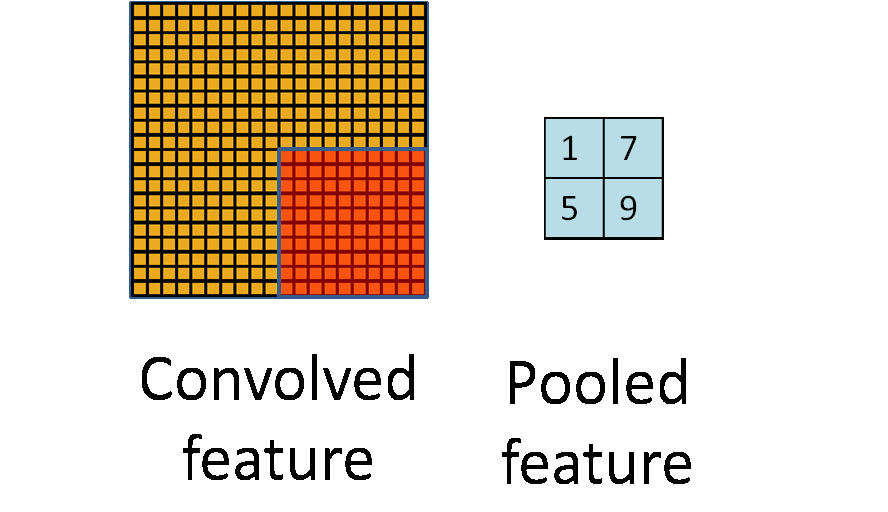
池化的不变性
如果人们选择图像中的连续范围作为池化区域,并且只是池化相同(重复)的隐藏单元产生的特征,那么,这些池化单元就具有平移不变性 (translation invariant)。这就意味着即使图像经历了一个小的平移之后,依然会产生相同的 (池化的) 特征。在很多任务中 (例如物体检测、声音识别),我们都更希望得到具有平移不变性的特征,因为即使图像经过了平移,样例(图像)的标记仍然保持不变。例如,如果你处理一个MNIST数据集的数字,把它向左侧或右侧平移,那么不论最终的位置在哪里,你都会期望你的分类器仍然能够精确地将其分类为相同的数字。
(*MNIST 是一个手写数字库识别库: http://yann.lecun.com/exdb/mnist/)
形式化描述
形式上,在获取到我们前面讨论过的卷积特征后,我们要确定池化区域的大小(假定为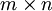 ),来池化我们的卷积特征。那么,我们把卷积特征划分到数个大小为 的不相交区域上,然后用这些区域的平均(或最大)特征来获取池化后的卷积特征。这些池化后的特征便可以用来做分类。
),来池化我们的卷积特征。那么,我们把卷积特征划分到数个大小为 的不相交区域上,然后用这些区域的平均(或最大)特征来获取池化后的卷积特征。这些池化后的特征便可以用来做分类。
中英文对照
- 特征 features
- 样例 example
- 过拟合 over-fitting
- 平移不变性 translation invariant
- 池化 pooling
- 提取 extract
- 物体检测 object detection
cnn的说明的更多相关文章
- Deep learning:五十一(CNN的反向求导及练习)
前言: CNN作为DL中最成功的模型之一,有必要对其更进一步研究它.虽然在前面的博文Stacked CNN简单介绍中有大概介绍过CNN的使用,不过那是有个前提的:CNN中的参数必须已提前学习好.而本文 ...
- 卷积神经网络(CNN)学习算法之----基于LeNet网络的中文验证码识别
由于公司需要进行了中文验证码的图片识别开发,最近一段时间刚忙完上线,好不容易闲下来就继上篇<基于Windows10 x64+visual Studio2013+Python2.7.12环境下的C ...
- 如何用卷积神经网络CNN识别手写数字集?
前几天用CNN识别手写数字集,后来看到kaggle上有一个比赛是识别手写数字集的,已经进行了一年多了,目前有1179个有效提交,最高的是100%,我做了一下,用keras做的,一开始用最简单的MLP, ...
- CNN车型分类总结
最近在做一个CNN车型分类的任务,首先先简要介绍一下这个任务. 总共30个类,训练集图片为车型图片,类似监控拍摄的车型图片,训练集测试集安6:4分,训练集有22302份数据,测试集有14893份数据. ...
- CNN初步-2
Pooling 为了解决convolved之后输出维度太大的问题 在convolved的特征基础上采用的不是相交的区域处理 http://www.wildml.com/2015/11/unde ...
- 基于孪生卷积网络(Siamese CNN)和短时约束度量联合学习的tracklet association方法
基于孪生卷积网络(Siamese CNN)和短时约束度量联合学习的tracklet association方法 Siamese CNN Temporally Constrained Metrics T ...
- [Keras] mnist with cnn
典型的卷积神经网络. Keras傻瓜式读取数据:自动下载,自动解压,自动加载. # X_train: array([[[[ 0., 0., 0., ..., 0., 0., 0.], [ 0., 0. ...
- tensorflow学习笔记五:mnist实例--卷积神经网络(CNN)
mnist的卷积神经网络例子和上一篇博文中的神经网络例子大部分是相同的.但是CNN层数要多一些,网络模型需要自己来构建. 程序比较复杂,我就分成几个部分来叙述. 首先,下载并加载数据: import ...
- 使用caffe训练自己的CNN
现在有这样的一个场景:给一张行人的小矩形框图片, 根据该行人的特征识别出性别. 分析: (1),行人的姿态各异,变化多端.很难提取图像的特定特征 (2),正常人肉眼判别行人的根据是身材比例,头发长度等 ...
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
随机推荐
- UI设计初学者教程:色彩基础知识
编辑:千锋UI设计 初学设计都会先认识三原色,通常我们说的三原色指的是颜料三原色:红.黄.蓝:其实三原色还有色光三原色:红.绿.蓝.我们通常说的红黄蓝就是减色法三原色,而红绿蓝是加色法三原色.可能这么 ...
- Ubuntu安装R及R包
安装R $sudo apt-get update $sudo apt-get install r-base $sudo apt-get install r-base-dev 安装一些可能的依赖包 $s ...
- mcu 通信数据解析
串口发送一帧数据时,两个字节的间隔时间是多少? 波特率:发送二进制数据位的速率,习惯上用 baud 表示,即我们发送一位二进制数据的持续时间=1/baud. 如果波特率为9600,发送一个位需要的时间 ...
- wepy中页面的跳转
1.在pages中创建好页面之后,需要在app.wpy中的config中配置好页面路由:2.如果跳转的按钮在page页面中 this.$navigate({url:"content" ...
- 安装ubuntu16.04的时候出现的detecting file system
解决问题方法是,进入主界面执行,如下操作即可: sudo umount -l /isodevice
- 【Erlang】源码安装
Erlang介绍 Erlang(['ə:læŋ])是一种通用的面向并发的编程语言,它由瑞典电信设备制造商爱立信所辖的CS-Lab开发,目的是创造一种可以应对大规模并发活动的编程语言和运行环境. Erl ...
- 【Linux】 Ncures库的介绍与安装
Ncures库的介绍 ncurses(new curses)是一套编程库,它提供了一系列的函数以便使用者调用它们去生成基于文本的用户界面. ncurses名字中的n意味着“new”,因为它是curse ...
- 【Java】使用IDE开发工具远程调试Java代码
概述 服务端程序运行在一台远程服务器上,我们可以在本地服务端的代码(前提是本地的代码必须和远程服务器运行的代码一致)中设置断点,每当有请求到远程服务器时时能够在本地知道远程服务端的此时的内部状态 测试 ...
- Alpha 冲刺 (2/10)
队名 火箭少男100 组长博客 林燊大哥 作业博客 Alpha 冲鸭鸭! 成员冲刺阶段情况 林燊(组长) 过去两天完成了哪些任务 协调各成员之间的工作 协助前端界面的开发 搭建测试用服务器的环境 完成 ...
- MyBatis 实现新增
MyBatis实现新增 1.概念学习:(角度不同) 1.1 功能:从应用程序角度出发,软件具有哪些功能 1.2 业务:完成功能时的逻辑,对应Service中一个方法 1.3 事务:从数据库角度出发,完 ...