elasticSearch6源码分析(8)RepositoriesModule模块
1.RepositoriesModule概述
Sets up classes for Snapshot/Restore
1.1 snapshot概述
A snapshot is a backup taken from a running Elasticsearch cluster. You can take a snapshot of individual indices or of the entire cluster and store it in a repository on a shared filesystem, and there are plugins that support remote repositories on S3, HDFS, Azure, Google Cloud Storage and more. Snapshots are taken incrementally. This means that when creating a snapshot of an index Elasticsearch will avoid copying any data that is already stored in the repository as part of an earlier snapshot of the same index. Therefore it can be efficient to take snapshots of your cluster quite frequently. Snapshots can be restored into a running cluster via the restore API. When restoring an index it is possible to alter the name of the restored index as well as some of its settings, allowing a great deal of flexibility in how the snapshot and restore functionality can be used.
1.2 repository
You must register a snapshot repository before you can perform snapshot and restore operations. We recommend creating a new snapshot repository for each major version. The valid repository settings depend on the repository type. If you register same snapshot repository with multiple clusters, only one cluster should have write access to the repository. All other clusters connected to that repository should set the repository to readonly mode.
实例:备份
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "my_backup_location"
}
}
恢复
POST /_snapshot/my_backup/snapshot_1/_restore
删除
DELETE /_snapshot/my_backup/snapshot_1
监控
GET /_snapshot/my_backup/snapshot_1/_status
2.配置类BlobStoreRepository
protected BlobStoreRepository(RepositoryMetaData metadata, Settings globalSettings, NamedXContentRegistry namedXContentRegistry) {
super(globalSettings);
this.metadata = metadata;
this.namedXContentRegistry = namedXContentRegistry;
snapshotRateLimiter = getRateLimiter(metadata.settings(), "max_snapshot_bytes_per_sec", new ByteSizeValue(40, ByteSizeUnit.MB));
restoreRateLimiter = getRateLimiter(metadata.settings(), "max_restore_bytes_per_sec", new ByteSizeValue(40, ByteSizeUnit.MB));
readOnly = metadata.settings().getAsBoolean("readonly", false);
indexShardSnapshotFormat = new ChecksumBlobStoreFormat<>(SNAPSHOT_CODEC, SNAPSHOT_NAME_FORMAT,
BlobStoreIndexShardSnapshot::fromXContent, namedXContentRegistry, isCompress());
indexShardSnapshotsFormat = new ChecksumBlobStoreFormat<>(SNAPSHOT_INDEX_CODEC, SNAPSHOT_INDEX_NAME_FORMAT,
BlobStoreIndexShardSnapshots::fromXContent, namedXContentRegistry, isCompress());
ByteSizeValue chunkSize = chunkSize();
if (chunkSize != null && chunkSize.getBytes() <= 0) {
throw new IllegalArgumentException("the chunk size cannot be negative: [" + chunkSize + "]");
}
}
配置类的实现
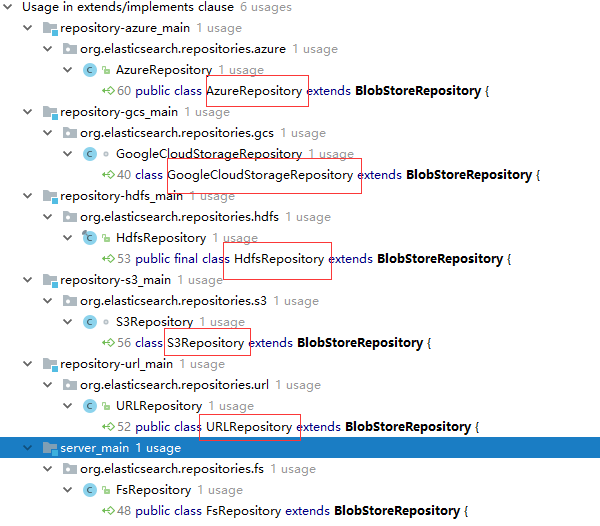
3.重点类
3.1 SnapshotsService
创建snapshot
/**
* Service responsible for creating snapshots
* <p>
* A typical snapshot creating process looks like this:
* <ul>
* <li>On the master node the {@link #createSnapshot(SnapshotRequest, CreateSnapshotListener)} is called and makes sure that no snapshots is currently running
* and registers the new snapshot in cluster state</li>
* <li>When cluster state is updated the {@link #beginSnapshot(ClusterState, SnapshotsInProgress.Entry, boolean, CreateSnapshotListener)} method
* kicks in and initializes the snapshot in the repository and then populates list of shards that needs to be snapshotted in cluster state</li>
* <li>Each data node is watching for these shards and when new shards scheduled for snapshotting appear in the cluster state, data nodes
* start processing them through {@link SnapshotShardsService#processIndexShardSnapshots(ClusterChangedEvent)} method</li>
* <li>Once shard snapshot is created data node updates state of the shard in the cluster state using the {@link SnapshotShardsService#sendSnapshotShardUpdate(Snapshot, ShardId, ShardSnapshotStatus)} method</li>
* <li>When last shard is completed master node in {@link SnapshotShardsService#innerUpdateSnapshotState} method marks the snapshot as completed</li>
* <li>After cluster state is updated, the {@link #endSnapshot(SnapshotsInProgress.Entry)} finalizes snapshot in the repository,
* notifies all {@link #snapshotCompletionListeners} that snapshot is completed, and finally calls {@link #removeSnapshotFromClusterState(Snapshot, SnapshotInfo, Exception)} to remove snapshot from cluster state</li>
* </ul>
*/
3.2 RestoreService
/**
* Service responsible for restoring snapshots
* <p>
* Restore operation is performed in several stages.
* <p>
* First {@link #restoreSnapshot(RestoreRequest, org.elasticsearch.action.ActionListener)}
* method reads information about snapshot and metadata from repository. In update cluster state task it checks restore
* preconditions, restores global state if needed, creates {@link RestoreInProgress} record with list of shards that needs
* to be restored and adds this shard to the routing table using {@link RoutingTable.Builder#addAsRestore(IndexMetaData, SnapshotRecoverySource)}
* method.
* <p>
* Individual shards are getting restored as part of normal recovery process in
* {@link IndexShard#restoreFromRepository(Repository)} )}
* method, which detects that shard should be restored from snapshot rather than recovered from gateway by looking
* at the {@link ShardRouting#recoverySource()} property.
* <p>
* At the end of the successful restore process {@code RestoreService} calls {@link #cleanupRestoreState(ClusterChangedEvent)},
* which removes {@link RestoreInProgress} when all shards are completed. In case of
* restore failure a normal recovery fail-over process kicks in.
*/
elasticSearch6源码分析(8)RepositoriesModule模块的更多相关文章
- elasticSearch6源码分析(5)gateway模块
1.gateway概述 The local gateway module stores the cluster state and shard data across full cluster res ...
- elasticSearch6源码分析(4)indices模块
1.indices概述 The indices module controls index-related settings that are globally managed for all ind ...
- elasticSearch6源码分析(3)cluster模块
1. cluser概述 One of the main roles of the master is to decide which shards to allocate to which nodes ...
- 【转】Spark源码分析之-deploy模块
原文地址:http://jerryshao.me/architecture/2013/04/30/Spark%E6%BA%90%E7%A0%81%E5%88%86%E6%9E%90%E4%B9%8B- ...
- ADB 源码分析(一) ——ADB模块简述【转】
ADB源码分析(一)——ADB模块简述 1.Adb 源码路径(system/core/adb). 2.要想很快的了解一个模块的基本情况,最直接的就是查看该模块的Android.mk文件,下面就来看看a ...
- 使用react全家桶制作博客后台管理系统 网站PWA升级 移动端常见问题处理 循序渐进学.Net Core Web Api开发系列【4】:前端访问WebApi [Abp 源码分析]四、模块配置 [Abp 源码分析]三、依赖注入
使用react全家桶制作博客后台管理系统 前面的话 笔者在做一个完整的博客上线项目,包括前台.后台.后端接口和服务器配置.本文将详细介绍使用react全家桶制作的博客后台管理系统 概述 该项目是基 ...
- elasticsearch源码分析之search模块(server端)
elasticsearch源码分析之search模块(server端) 继续接着上一篇的来说啊,当client端将search的请求发送到某一个node之后,剩下的事情就是server端来处理了,具体 ...
- elasticsearch源码分析之search模块(client端)
elasticsearch源码分析之search模块(client端) 注意,我这里所说的都是通过rest api来做的搜索,所以对于接收到请求的节点,我姑且将之称之为client端,其主要的功能我们 ...
- (一) Mybatis源码分析-解析器模块
Mybatis源码分析-解析器模块 原创-转载请说明出处 1. 解析器模块的作用 对XPath进行封装,为mybatis-config.xml配置文件以及映射文件提供支持 为处理动态 SQL 语句中的 ...
随机推荐
- C/C++ 打开串口和关闭串口
通常使用下列函数来通过Win系统来对外围设备进行通信处理: 0. 前言 做串口方面的程序,使用CreateFile打开串口通信端口.在对串口操作之前,需要首先打开串口.使用C++进行串口编程,如果采用 ...
- hdu 4925 黑白格
http://acm.hdu.edu.cn/showproblem.php?pid=4925 给定一个N*M的网格,对于每个格子可以选择种树和施肥,默认一个苹果树收获1个苹果,在一个位置施肥的话,周围 ...
- Dinic算法——重述
赛前赛后算是第三次接触Dinic算法了,每一次接触都能有种很好的感觉,直男的我没法描述~~ 已经比较懂得DInic的基本算法思想了 首先是bfs进行进行分层处理,然后dfs寻找分层后的最大流, ...
- bootstrap1相关学习文档
<em>Bootstrap 框架</em> //倾斜 4.对齐 //设置文 ...
- 二分图匹配-HK算法
先把代码贴上,其他南京回来再补了.. #include <cstdio> #include <cstdlib> #include <cstring> #includ ...
- 安装json插件
谷歌浏览器中安装JsonView扩展程序 实际开发工作中经常用到json数据,那么就会有这样一个需求:在谷歌浏览器中访问URL地址返回的json数据能否按照json格式展现出来. 比如,在谷歌浏览器中 ...
- postgresql 主从 patroni
1 安装基础包 1.1 postgres yum install https://download.postgresql.org/pub/repos/yum/10/redhat/rhel-7-x86_ ...
- 一个简单的用python 实现系统登录的http接口服务实例
用python 开发一个登录的http接口: 用户登录数据存在缓存redis里,登录时根据session判断用户是否已登录,session有效,则直接返回用户已登录,否则进mysql查询用户名及密码, ...
- Winform DataGridView控件在业务逻辑上的简单使用
需要对文字列表进行处理,然后用到DataGridView控件来处理,记录一下.效果如下: 主要是想通过禁用和取消单元格选择来使图标单元格呈现出鼠标点击的效果.因为有个单元格选择的问题困扰着我. 是这样 ...
- 关于Winform下DataGridView中实现checkbox全选反选、同步列表项的处理
近期接手一个winform 项目,虽然之前有.net 的经验,但是对一些控件的用法还不是很熟悉. 这段时间将会记录一些在工作中遇到的坎坷以及对应的解决办法,写出来与大家分享并希望大神提出更好解决方法来 ...