AD阶段分类论文阅读笔记
A Deep Learning Pipeline for Classifying Different Stages of Alzheimer’s Disease from fMRI Data
-- Yosra Kazemi
阿尔茨海默氏病(AD)是一种不可逆转的渐进性神经障碍,会导致记忆和思维能力的丧失
该论文使用深度学习的方法成功地对AD病的五个阶段进行了分类:非病态健康控制(NC)、显著性记忆关注(SMC)、早期轻度认知损害 (EMCI)、晚期轻度认知损害(LMCI)和阿尔茨海默病(AD)
在进行分类之前,fMRI的数据经过严格的预处理以避免任何噪音;然后,利用AlexNet模型提取从低到高水平的特征并学习
阿尔茨海默病以不同的速率发展,每个个体可能在不同的时间经历不同的症状,在不同阶段的阿尔茨海默氏症中,类别间的差异很低。
阿尔茨海默病是痴呆的主要病因,不同类型的痴呆症包括:老年痴呆(AD)、路易体痴呆、额颞叶紊乱症和血管性痴呆
在阿尔茨海默病中,大脑细胞中某些蛋白质水平的变化会影响神经元在海马体区域的交流能力,因此阿尔茨海默氏症的早期症状是失忆
病人的大脑中有一些不正常的团块和缠结在一起的纤维束,它们分别被称为淀粉样斑块和神经纤维缠结。这些现在被认为是老年痴呆症的一些主要症状
研究人员认为AD病人在出现症状之前的20年或更多年以前,大脑就发生了变化
目前,对于AD的阶段没有很好的定义,一些专家为更好地理解疾病的进展使用了七阶段的模型
- 没有损伤
- 非常轻微的下降
- 轻微下降
- 温和的下降
- 中度严重下降
- 严重下降
- 非常严重下降
阿尔茨海默病协会将七个阶段概括为三个主要阶段:轻度、中度和重读
大多数机器学习特征提取方法的目标是最大化类间方差或最小化类内方差
在这项研究中,使用静息状态fMRI成像来区分阿尔茨海默病不同阶段之间的差异,关注的是大脑在疾病的不同阶段是如何变化的,而不是在活动中是如何变化的
该研究详细介绍:
数据集
使用ADNI数据库中的一个子集来训练和验证CNN分类器
需注意ADNI数据差异:
ADNI的扫描是在两种不同的特斯拉扫描仪上进行的,分别为飞利浦医疗系统和西门子:
飞利浦医疗系统:静息状态fMRI扫描序列(EPI)144卷,场强度=3.0特斯拉,翻转角度=80.0度,TE=30.0 ms,TR=3000.0 ms, 64 × 65矩阵,3.31 mm厚度的6720.0片,延长静息状态fMRI的EPI序列为200卷,场强度=3.0特斯拉,翻转角度=90.0度,TE=30.0 ms, TR=3000.0, 64 × 65矩阵,3.31 mm厚9600.0片
西门子:EPI序列为197卷,场强度=3.0 tesla,翻转角度=80.0度,TE=30.0 ms, TR=2999.99, 448 × 448矩阵,197片3.4 mm厚度
数据集类别信息:

数据预处理
预处理提高了分析的灵敏度,验证了统计模型的有效性
首先将DICOM格式的数据转换为NII格式的数据,使用dcm2nii toolbox
然后从fMRI数据中移除非大脑区域,使用FSL-BET toolbox
抖动修正,使用FSL-MCFLIRT toolbox
切片时序校正,使用Hanning- windowed Sinc插值 -- 证明体素时间序列对所有体素具有参考时序
空间平滑,使用Gaussian kernel of 5mm FWHM -- 保护底层信号的同时降低噪声水平
高通滤波,使用时域高通滤波器,截止频率为0.01 HZ -- 去除低电平无用信号,如呼吸、心跳
空间标准化,FSL‘s调情、注册MNI152标准空间 -- 为了分析数据需要相同的图片标准
MNI152标准空间: 152幅结构图像经过高维非线性注册后的均值
图像变换
为建立合适的数据集,最终将图片转换为PNG格式
方法
基于作者的实验测试,AlexNet与GoogleNet有近似的精确度,但是AlexNet需要的时间要少,因而选择了ALexNet作为CNN分类器
过拟合的原因是:参数和权重数量很大,但是样本量不足
防止过拟合的方法有:
- 增大数据集,降低模型复杂性
- 使用数据增强
- 使用正规化
AlexNet架构
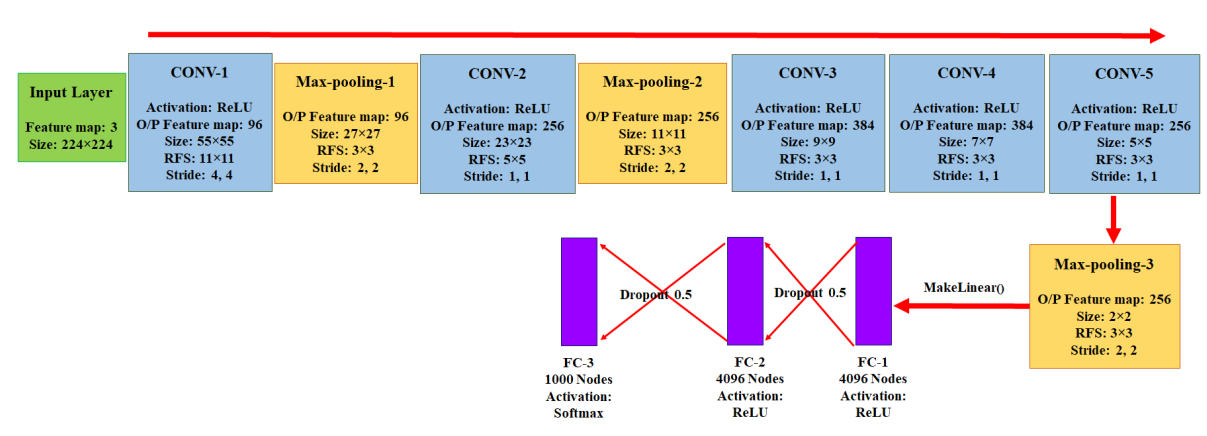
该研究使用的数据集的划分为:training : validation : testing = 0.6 : 0.2 : 0.2
该研究使用Caffe Deep Learning framework来训练模型,同时将数据集转换为Lightning Memory Mapped Database,将图片转换为256 × 256 像素
为在Caffe framework中实现模型,该研究调整AlexNEt模型为30 epochs,使用Caffe Stochastic Gradient Descent(SGD) solver方法
SGD solver方法使用的更新权重W的等式:
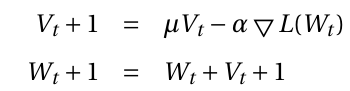
 是一个负梯度,vt是之前的权重更新参数,a是学习率,u是动量超参数
是一个负梯度,vt是之前的权重更新参数,a是学习率,u是动量超参数
初始化参数:

超参数:
学习率变化曲线:

经过多次迭代之后的动量将权重更新的大小乘1 / (1 - u)
最终使用的AlexNet架构:

AD阶段分类论文阅读笔记的更多相关文章
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximati
[论文阅读笔记] Fast Network Embedding Enhancement via High Order Proximity Approximation 本文结构 解决问题 主要贡献 主要 ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- [论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding
[论文阅读笔记] Adversarial Mutual Information Learning for Network Embedding 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
随机推荐
- hdu2504
代码一: //这个没有过 #include<stdio.h> //typedef long long ll; int main() { int T; scanf("%d" ...
- ASP.NET Web API 框架研究 Action的选择
如何从HttpController众多方法里如何选择出有效的Action方法?主要分一下几个步骤: 首先,获取候选HttpActionDescriptor列表(ILookup(string,HttpA ...
- 国内代码托管平台(Git)
可以说GitHub的出现完全颠覆了以往大家对代码托管网站的认识.GitHub不但是一个代码托管网站,更是一个程序员的SNS社区.GitHub真正迷人的是它的创新能力与Geek精神,这些都是无法模仿的. ...
- Django:查询后,分页功能为全部对象分页,丢失查询查询参数
问题: 原始的链接为 http://127.0.0.1:8000/article/list-article-titles-bysomeone/guchen/?column=django 有一个colu ...
- WPF实战案例-打印
在前段时间做了一下打印,因为需要支持的格式比较多,所以wpf能打印的有限分享一下几种格式的打印(.xls .xlsx .doc .docx .png .jpg .bmp .pdf) 首先为了保证exc ...
- WPF Command CanExecute 触发一次的问题
昨天在项目中遇到一个问题,按钮bind了Command后,利用CanExecute控制它的是否可点击.结果却在初始化viewmodel的时候执行了一次CanExecute,之后一直不触发,按钮的可用性 ...
- 【BZOJ3280】 小R的烦恼(费用流,建模)
有很浓厚的熟悉感?餐巾计划问题? 不就是多了几个医院,相当于快洗部和慢洗部开了分店. 考虑建图: 如果把每一天拆成两个点,一个表示需求,另一个表示拥有的话. 显然就是一个两边的图,考虑如果我现在有人, ...
- AJPFX:外汇的杠杆保证金是什么
外汇杠杆和保证金两者有着密切的关系.杠杆越大,交易时所用的保证金就越少. 杠杆即为保证金可以缩小的倍数.例如在没有杠杆的情况下,做一手即10万的欧元兑美元货币对合约(现在价格是1.05821),您所需 ...
- mysql添加外键的4种方式
今天开始复习,在过后的几天里开始在博客上记录一下平时疏忽的知识点,温故而知新 屁话不多--直接上货 创建主表: 班级 CREATE TABLE class(cid INT PRIMARY KEY AU ...
- shapefile的使用和地理信息的获得
Shapefile文件是美国ESRI公司发布的文件格式,因其ArcGIS软件的推广而得到了普遍的使用,是现在GIS领域使用最为广泛的矢量数据格式.官方称Shapefile是一种用于存储地理要素的几何位 ...