@Indexed 注解
本文转载自:https://www.cnblogs.com/aflyun/p/11992101.html
最近在看 SpringBoot 核编程思想(核心篇),看到走向注解驱动编程这章,里面有讲解到:在SpringFramework 5.0 引入了一个注解@Indexed ,它可以为 Spring 的模式注解添加索引,以提升应用启动性能。
在往下阅读的时候,请注意一些模式注解:
| Spring注解 | 场景说明 |
|---|---|
| @Repository | 数据仓库模式注解 |
| @Component | 通用组件模式注解 |
| @Service | 服务模式注解 |
| @Controller | Web控制器模式注解 |
| @Configuration | 配置类模式注解 |
使用场景
在应用中使用@ComponentScan扫描 package 时,如果 package 中包含很多的类,那么 Spring 启动的时候就会变慢。
提升性能的一个方案就是提供一个 Component 的候选列表,Spring 启动时直接扫描注入这些列表就行了,而不需要一个个类去扫描,再筛选出候选 Component。
需要注意的是:在这种模式下,所有组件扫描的目标模块都必须使用这种机制——大白话将就所有的 Component 组件都必须生成到列表文件中去。
While classpath scanning is very fast, it is possible to improve the startup performance of large applications by creating a static list of candidates at compilation time. In this mode, all modules that are target of component scan must use this mechanism.
使用方式
在项目中使用的时候需要导入一个spring-context-indexer jar包。
<dependencies>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context-indexer</artifactId>
<version>xxxx</version>
<optional>true</optional>
</dependency>
</dependencies>
然后在代码中,对于使用了模式注解的类上加上@Indexed注解即可。如下:
@Indexed
@Controller
public class HelloController {
}
加了上面的依赖后,项目就会自动使用索引的方式启动Spring。
原理说明
摘自官网:

简单说明一下:在项目中使用了@Indexed之后,编译打包的时候会在项目中自动生成META-INT/spring.components文件。
当Spring应用上下文执行ComponentScan扫描时,META-INT/spring.components将会被CandidateComponentsIndexLoader 读取并加载,转换为CandidateComponentsIndex对象,这样的话@ComponentScan不在扫描指定的package,而是读取CandidateComponentsIndex对象,从而达到提升性能的目的。
知道上面的原理,可以看一下org.springframework.context.index.CandidateComponentsIndexLoader的源码。
ublic final class CandidateComponentsIndexLoader {
public static final String COMPONENTS_RESOURCE_LOCATION = "META-INF/spring.components";
public static final String IGNORE_INDEX = "spring.index.ignore";
private static final boolean shouldIgnoreIndex = SpringProperties.getFlag(IGNORE_INDEX);
private static final Log logger = LogFactory.getLog(CandidateComponentsIndexLoader.class);
private static final ConcurrentMap<ClassLoader, CandidateComponentsIndex> cache =
new ConcurrentReferenceHashMap<>();
private CandidateComponentsIndexLoader() {
}
@Nullable
public static CandidateComponentsIndex loadIndex(@Nullable ClassLoader classLoader) {
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = CandidateComponentsIndexLoader.class.getClassLoader();
}
return cache.computeIfAbsent(classLoaderToUse, CandidateComponentsIndexLoader::doLoadIndex);
}
@Nullable
private static CandidateComponentsIndex doLoadIndex(ClassLoader classLoader) {
if (shouldIgnoreIndex) {
return null;
}
try {
Enumeration<URL> urls = classLoader.getResources(COMPONENTS_RESOURCE_LOCATION);
if (!urls.hasMoreElements()) {
return null;
}
List<Properties> result = new ArrayList<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
Properties properties = PropertiesLoaderUtils.loadProperties(new UrlResource(url));
result.add(properties);
}
if (logger.isDebugEnabled()) {
logger.debug("Loaded " + result.size() + "] index(es)");
}
int totalCount = result.stream().mapToInt(Properties::size).sum();
return (totalCount > 0 ? new CandidateComponentsIndex(result) : null);
}
catch (IOException ex) {
throw new IllegalStateException("Unable to load indexes from location [" +
COMPONENTS_RESOURCE_LOCATION + "]", ex);
}
}
}
使用注意点
虽然这个@Indexed注解能提升性能,但是在使用的时候也需要注意下。
假设Spring应用中存在一个包含META-INT/spring.components资源的a.jar,但是 b.jar 仅存在模式注解,那么使用@ComponentScan扫描这两个JAR中的package时,b.jar 中的模式注解不会被识别,请务必注意这样的问题。
举个列子说明下,能够更好的理解。
DemoA项目(使用
@Indexed注解)
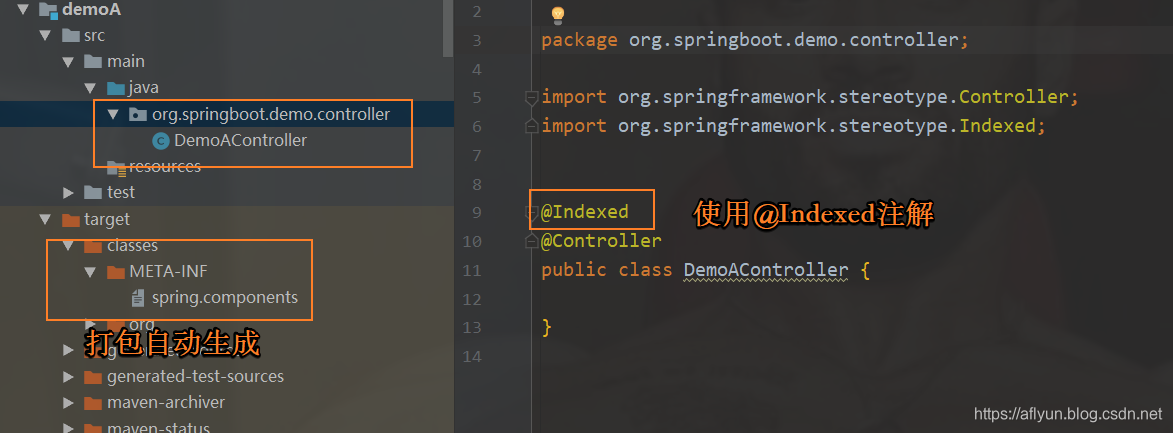
DemoB项目(不使用
@Indexed注解)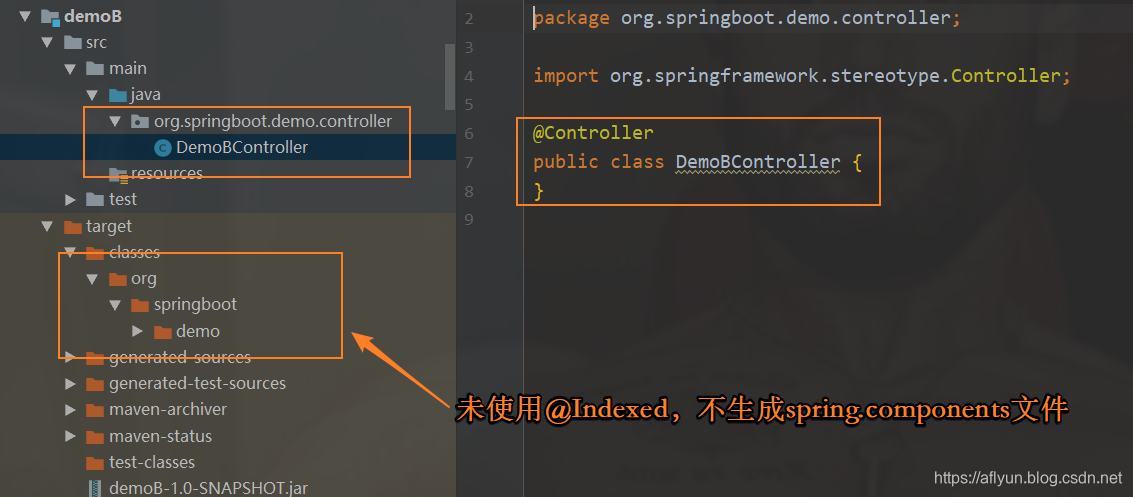
SpringBootDemo项目
在此项目中引入DemoA.jar和DemoB.jar。然后进行如下测试,测试代码如下:
配置类,扫描模式注解
@Configuration
@ComponentScan(basePackages = "org.springboot.demo")
public class SpringIndexedConfiguration {
}
测试类:
@Test
public void testIndexedAnnotation(){
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(SpringIndexedConfiguration.class);
System.out.println("获取DemoA Jar中【org.springboot.demo.controller.DemoAController】");
DemoAController demoAController = context.getBean(DemoAController.class);
System.out.println("DemoAController = " + demoAController.getClass());
System.out.println("获取DemoB Jar中【org.springboot.demo.controller.DemoBController】");
DemoBController demoBController = context.getBean(DemoBController.class);
System.out.println("DemoBController = " + demoBController.getClass());
}
结果:
beanDefinitionName = demoAController
获取DemoA Jar中【org.springboot.demo.controller.DemoAController】
DemoAController = class org.springboot.demo.controller.DemoAController
获取DemoB Jar中【org.springboot.demo.controller.DemoBController】
org.springframework.beans.factory.NoSuchBeanDefinitionException: No qualifying bean of type 'org.springboot.demo.controller.DemoBController' available
找不到 DemoBController 。
通过这样一个简单的Demo,验证了上面提到的使用注意点。
对于这种情况,Spring 官网提示了配置相关属性,不再使用index方式启动。要是这样的话,我们完全可以不添加spring-context-indexer 依赖,这样整体就不会使用index模式了。
The index is enabled automatically when a
META-INF/spring.componentsis found on the classpath. If an index is partially available for some libraries (or use cases) but could not be built for the whole application, you can fallback to a regular classpath arrangement (as though no index was present at all) by settingspring.index.ignoretotrue, either as a system property or in aspring.propertiesfile at the root of the classpath.
@Indexed 注解的更多相关文章
- SpringFramework5.0 @Indexed注解 简单解析
目录 使用场景 使用方法 原理说明 使用需注意点 案例说明 参考资料 纸上得来终觉浅 绝知此事要躬行 -陆游 最近在看SpringBoot核编程思想(核心篇),看到走向注解驱动编程这章,里面有讲解到: ...
- mongo注解详解
1.@Entity如果你想通过Morphia把你的对象保存到Mongo中,你首先要做的是使用@Entity注解你的类:@Entity(value="comm_user_favorite_co ...
- 死磕Spring之IoC篇 - BeanDefinition 的解析过程(面向注解)
该系列文章是本人在学习 Spring 的过程中总结下来的,里面涉及到相关源码,可能对读者不太友好,请结合我的源码注释 Spring 源码分析 GitHub 地址 进行阅读 Spring 版本:5.1. ...
- Spring Boot 自动装配(一)
目录 目录 前言 1.起源 2.Spring 模式注解 2.1.装配方式 2.2.派生性 3.Spring @Enable 模块驱动 3.1.Spring框架中@Enable实现方式 3.2.自定义@ ...
- Solr7.x学习(8)-使用spring-data-solr
1.maven配置 <dependency> <groupId>org.springframework.data</groupId> <artifactId& ...
- 学习Spring-Data-Jpa(六)---spring-data-commons中的repository
1.spring-data-commons项目 spring-data-commons项目是所有spring-data项目的核心,我们来看一下该项目下的repository包中的接口和注解. 2.Re ...
- static关键字有何魔法?竟让Spring Boot搞出那么多静态内部类
生命太短暂,不要去做一些根本没有人想要的东西.本文已被 https://www.yourbatman.cn 收录,里面一并有Spring技术栈.MyBatis.JVM.中间件等小而美的专栏供以免费学习 ...
- SpringBoot数据访问(三) SpringBoot整合Redis
前言 除了对关系型数据库的整合支持外,SpringBoot对非关系型数据库也提供了非常好的支持,比如,对Redis的支持. Redis(Remote Dictionary Server,即远程字典服务 ...
- 这样优化Spring Boot,启动速度快到飞起!
微服务用到一时爽,没用好就呵呵啦,特别是对于服务拆分没有把控好业务边界.拆分粒度过大等问题,某些 Spring Boot 启动速度太慢了,可能你也会有这种体验,这里将探索一下关于 Spring Boo ...
随机推荐
- 阿里云VOD(一)
一.阿里云视频点播 1.功能介绍 视频点播(ApsaraVideo VoD,简称VoD)是集视频采集.编辑.上传.媒体资源管理.自动化转码处理(窄带高清TM).视频审核分析.分发加速于一体的一站式音视 ...
- CentOS对接GlusterFS
存储节点部署示例环境,仅供参考 主机名 IP 系统 gfs01 10.10.10.13 CentOS 7.4.1708 gfs02 10.10.10.14 CentOS 7.4.1708 一.Glus ...
- 深圳某小公司面试题:AQS是什么?公平锁和非公平锁?ReentrantLock?
AQS总体来说没有想象中那么难,只要了解它的实现框架,那理解起来就不是什么问题了. AQS在Java还是占很重要的地位的,面试也是经常会问. 目前已经连载11篇啦!进度是一周更新两篇,欢迎持续关注 [ ...
- Python赋值、浅复制和深复制
Python赋值.浅复制和深复制 首先我们需要知道赋值和浅复制的区别: 赋值和浅复制的区别 赋值,当一个对象赋值给另一个新的变量时,赋的其实是该对象在栈中的地址,该地址指向堆中的数据.即赋值后,两 ...
- 离线安装docker-ce
1.用一台可以连外网的虚拟机把docker-ce安装包下载下来,vim /tmp/docker-download.sh #!/bin/bash set -e mkdir -p /apps/docker ...
- JavaScript中函数的调用!
JavaScript中函数的调用! 1 普通函数 // 1 普通函数 function fn() { console.log(123); } // 函数名 + 一个小括号! 或者 函数名.call() ...
- 2021/1/20随记,MTU
背景: 事情是这样的,客户2台防火墙部署了ipsec,内网互通,但是其中ssh以及其他大命令之类的操作就会卡住,简单的vi命令可以使用. 解决: 排除网络问题,因为内网互通,其次是系统层面问题,最终定 ...
- 详解SpringMVC
详解SpringMVC 一.什么是MVC? MVC是模型(Model).视图(View).控制器(Controller)的简写,是一种软件设计规范.就是将业务逻辑.数据.显示分离的方法来组织代码. ...
- WireShark 之 text2pcap
前言 本来想用 010Editer 的,看到破解教程头都大了,那么就用 WireShark 的 Text2pcap 吧! 正文 打开CMD控制台窗口,转到WireShark安装目录 ,此处可以shif ...
- CSS3 Flex Box 弹性盒子、弹性布局
目录 1. 概要 2. justify-content 属性 3. align-items 属性 4. flex-wrap 属性 5. align-content 属性 6. 居中 7. align- ...