阿里面试官:HashMap 熟悉吧?好的,那就来聊聊 Redis 字典吧!
最近,小黑哥的一个朋友出去面试,回来跟小黑哥抱怨,面试官不按套路出牌,直接打乱了他的节奏。
事情是这样的,前面面试问了几个 Java 的相关问题,我朋友回答还不错,接下来面试官就问了一句:看来 Java 基础还不错,Java HashMap 你熟悉吧?
我朋友回答。工作经常用,有看过源码。
我朋友本来想着,你随便来吧,这个问题之前已经准备好了,随便问吧。
谁知道,面试官下面一句:
那好的,我们来聊聊 Redis 字典吧。
直接将他整蒙逼。

小黑哥的朋友由于没怎么研究过 Redis 字典,所以这题就直接回答不知道了。
当然,如果面试中真不知道,那就回答不了解,直接下一题,不要乱答。
不过这一题,小黑哥觉得还是很可惜,其实 Redis 字典基本原理与 HashMap 差不多,那我们其实可以套用这其中的原理,不求回答满分,但是怎么也可以得个及格分吧~
面试过程真要碰到这个问题,我们可以从下面三个方面回答。
- 数据结构
- 元素增加过程
- 扩容
字典数据结构
说起字典,也许大家比较陌生,但是我们都知道 Redis 本身提供 KV 查询的方式,这个 KV 就是其实通过底层就是通过字典保存。
另外,Redis 支持多种数据类型,其中一种类型为 Hash 键,也可以用来存储 KV 数据。
小黑哥刚开始了解的这个数据结构的时候,本来以为这个就是使用字典实现。其实并不是这样的,初始创建 Hash 键,默认使用另外一种数据结构-ZIPLIST(压缩列表),以此节省内存空间。
不过一旦以下任何条件被满足,Hash 键的数据结构将会变为字典,加快查询速度。
- 哈希表中某个键或某个值的长度大于
server.hash_max_ziplist_value(默认值为64)。 - 压缩列表中的节点数量大于
server.hash_max_ziplist_entries(默认值为512)。
Redis 字典新建时默认将会创建一个哈希表数组,保存两个哈希表。
其中 ht[0] 哈希表在第一次往字典中添加键值时分配内存空间,而另一个 ht[1] 将会在下文中扩容/缩容才会进行空间分配。
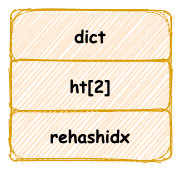
字典中哈希表其实就等同于Java HashMap,我们知道 Java 采用数组加链表/红黑树的实现方式,其实哈希表也是使用类似的数据结构。
哈希表结构如下所示:
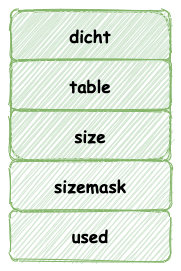
其中 table 属性是个数组, 其中数组元素保存一种 dictEntry 的结构,这个结构完全类似与 HashMap 中的 Entry 类型,这个结构存储一个 KV 键值对。
同时,为了解决 hash 碰撞的问题,dictEntry 存在一个 next 指针,指向下一个dictEntry ,这样就形成 dictEntry 的链表。
现在,我们回头对比 Java 中 HashMap,可以发现两者数据结构基本一致。
只不过 HashMap 为了解决链表过长问题导致查询变慢,JDK1.8 时在链表元素过多时采用红黑树的数据结构。
下面我们开始添加新元素,了解这其中的原理。
元素增加过程
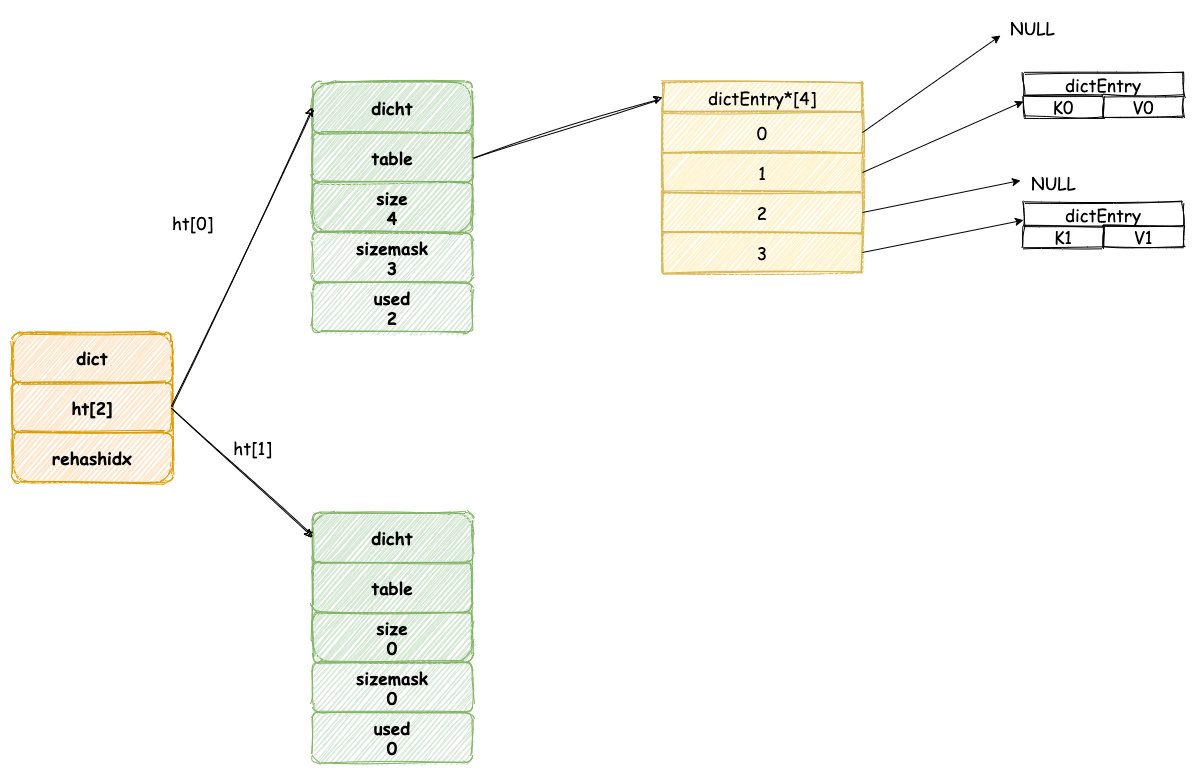
当我们往一个新字典中添加元素,默认将会为字典中 ht[0] 哈希表分配空间,默认情况下哈希表 table 数组大小为 4(DICT_HT_INITIAL_SIZE)。
新添加元素的键值将会经过哈希算法,确定哈希表数组的位置,然后添加到相应的位置,如图所示:
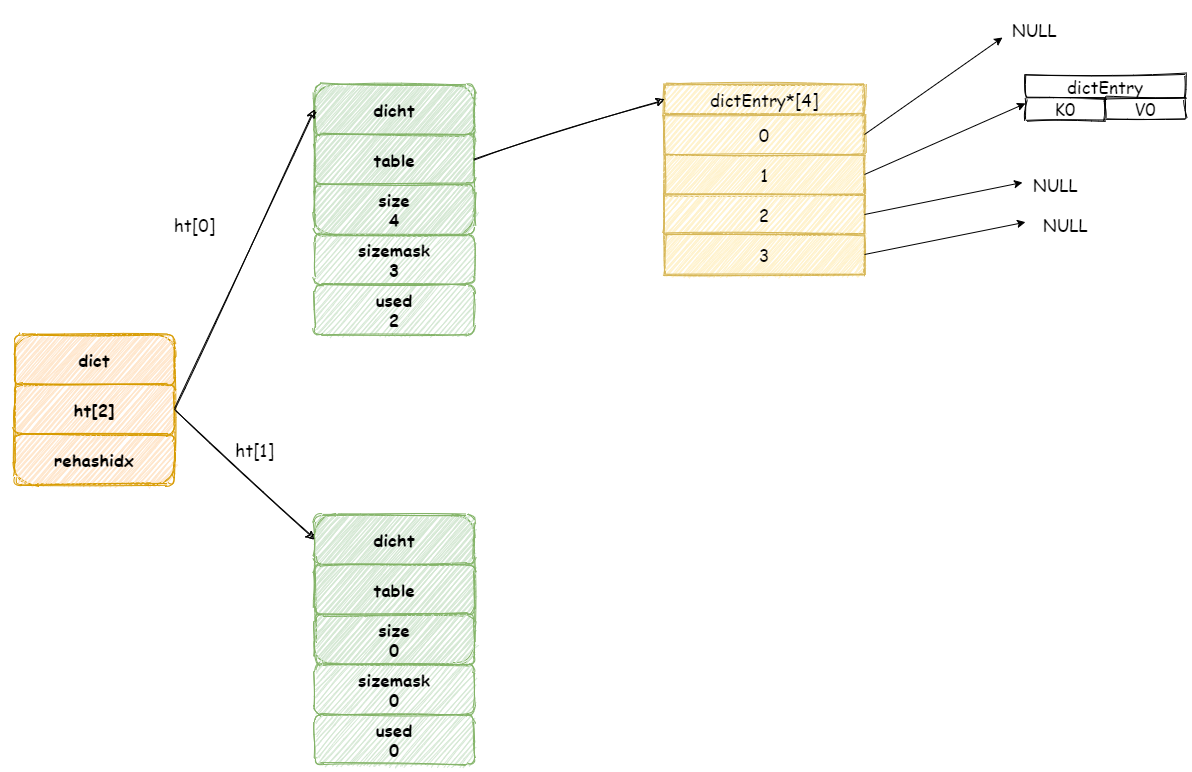
继续增加元素,此时如果两个不同键经过哈希算法产生相同的哈希值,这样就发生了哈希碰撞。
假设现在我们哈希表中拥有是三个元素,:
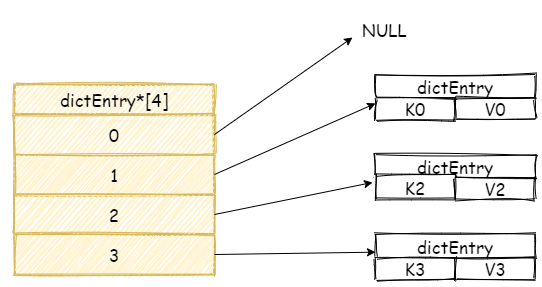
我们再增加一个新元素,如果此时刚好在数组 3 号位置上发生碰撞,此时 Redis 将会采用链表的方式解决哈希碰撞。
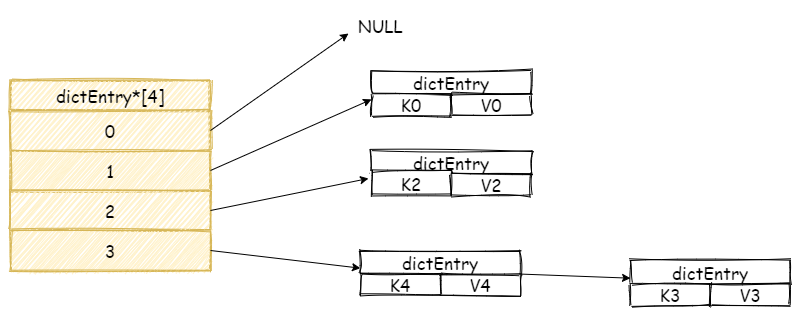
注意,新元素将会放在链表头结点,这么做目的是因为新增加的元素,很大概率上会被再次访问,放在头结点增加访问速度。
这里我们在对比一下元素添加过程,可以发现 Redis 流程其实与 JDK 1.7 版本的 HashMap 类似。
当我们元素增加越来越多时,哈希碰撞情况将会越来越频繁,这就会导致链表长度过长,极端情况下 O(1) 查询效率退化成 O(N) 的查询效率。
为此,字典必须进行扩容,这样就会使触发字典 rehash 操作。
扩容
当 Redis 进行 Rehash 扩容操作,首先将会为字典没有用到 ht[1] 哈希表分配更大空间。
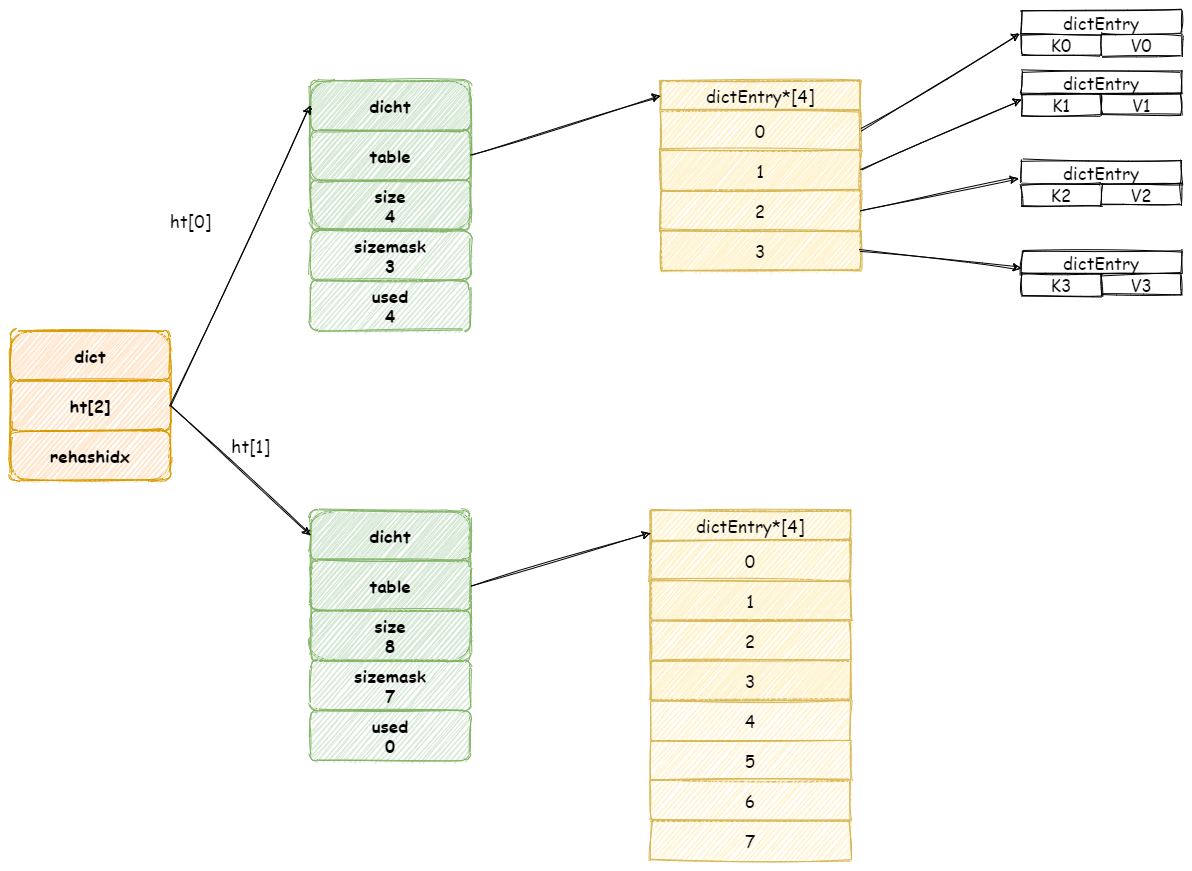
画外音:
ht[1]哈希表大小为第一个大于等于ht[0].used*2的 2^2(2的n 次方幂)
然后再将 ht[0] 中所有键值对都迁移到 ht[1] 中。
当节点全部迁移完毕,将会释放 ht[0]占用空间,并将 ht[1] 设置为 ht[0]。
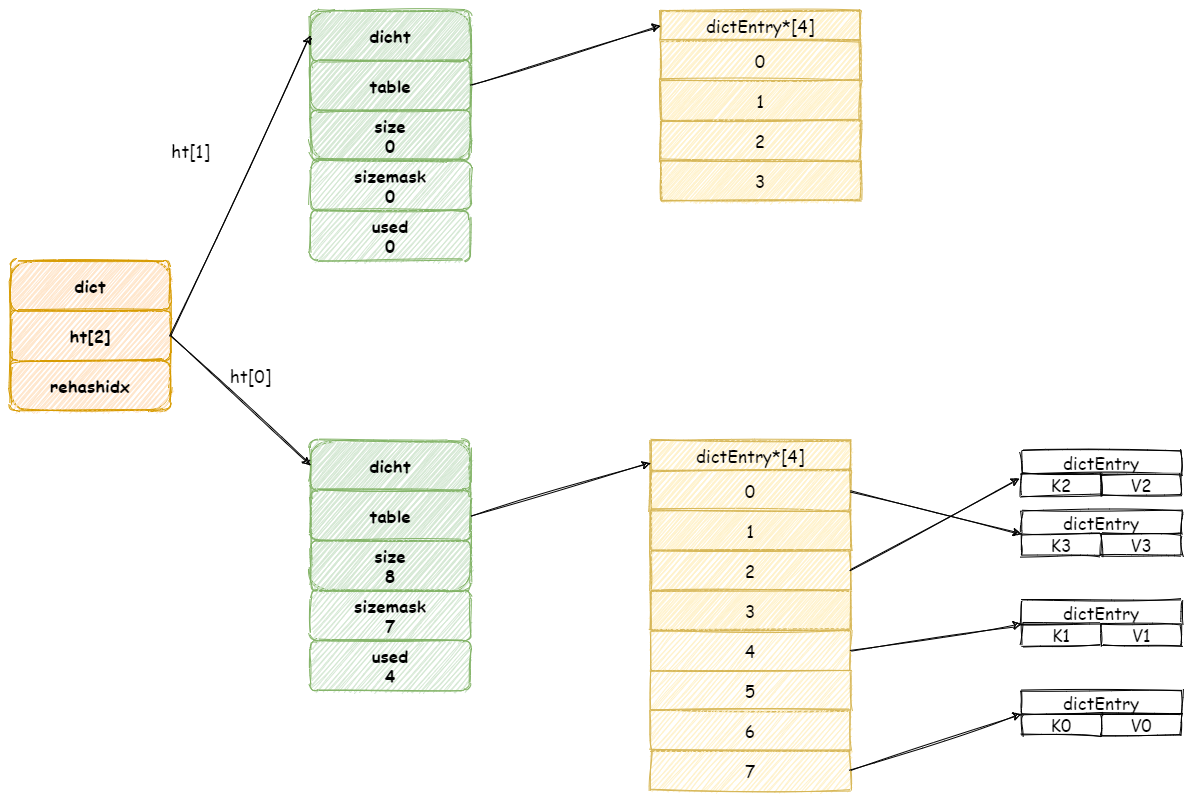
扩容 操作需要将 ht[0]所有键值对都 Rehash 到 ht[1] 中,如果键值过多,假设存在十亿个键值对,这样一次性的迁移,势必导致服务器会在一段时间内停止服务。
另外如果每次 rehash 都会阻塞当前操作,这样对于客户端处理非常不友好。
为了避免 rehash对服务器的影响,Redis 采用渐进式的迁移方式,慢慢将数据迁移分散到多个操作步骤。
这个操作依赖字典中一个属性 rehashidx,这是一个索引位置计数器,记录下一个哈希表 table 数组上元素,默认情况为值为 -1。
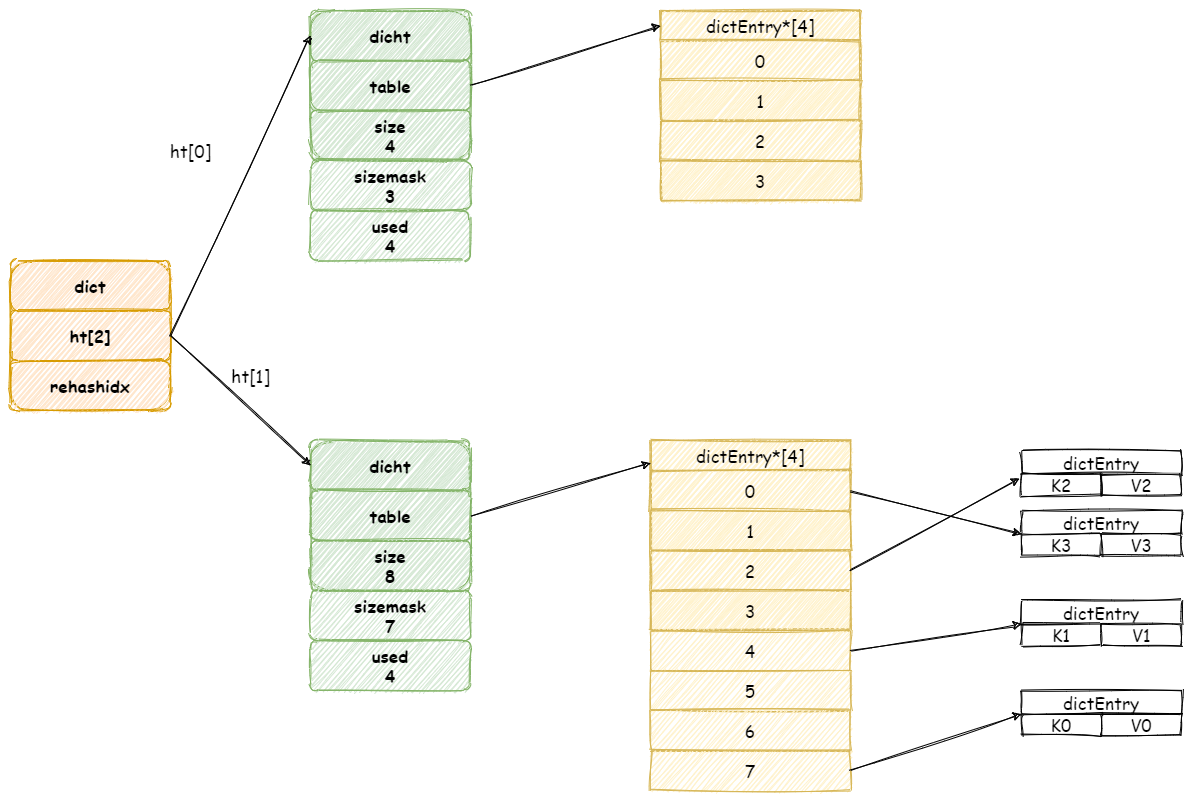
假设此时扩容前字典如图所示:
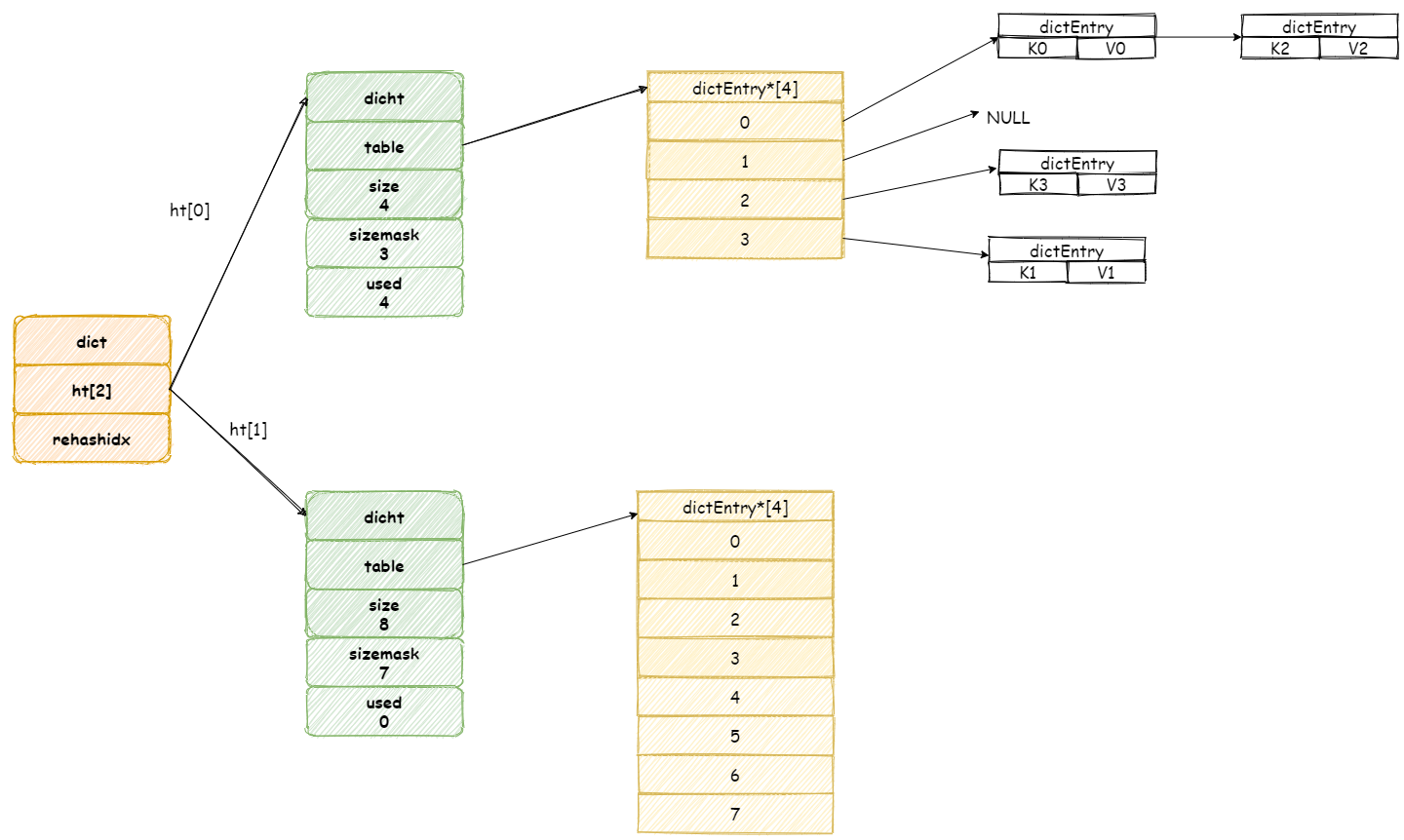
当开始 rehash 操作,rehashidx将会被设置为 0 。
这个期间每次收到增加,删除,查找,更新命令,除了这些命令将会被执行以外,还会顺带将 ht[0]哈希表在 rehashidx 位置的元素 rehash 到 ht[1] 中。
假设此时收到一个 K3 键的查询操作,Redis 首先执行查询操作,接着 Redis 将会为 ht[0]哈希表上 table 数组第 rehashidx索引上所有节点都迁移到 ht[1] 中。
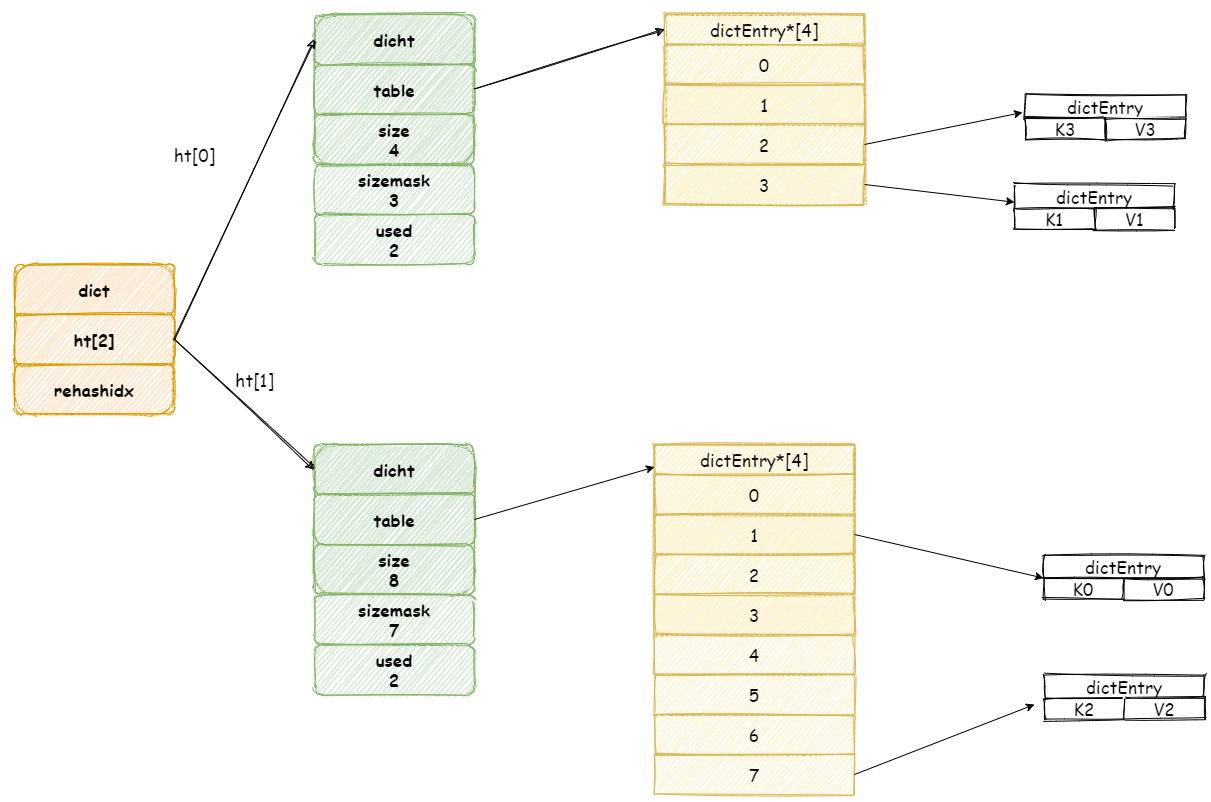
当操作完成之后,再将 rehashidx 属性值加 1。
最后当所有键值对都 rehash 到 ht[1]中时,rehashidx将会被重新设置为 -1。
虽然渐进式的 rehash 操作减少了工作量,但是却带来键值操作的复杂度。
这是因为在渐进式 rehash 操作期间,Redis 无法明确知道键到底在 ht[0]中,还是在 ht[1] 中,所以这个时候 Redis 不得不查找两个哈希表。
以查找为例,Redis 首先查询 ht[0] ,如果没找到将会继续查找 ht[1],除了查询以外,更新,删除也会执行如上的操作。
添加操作其实就没这么麻烦,因为ht[0]不会在使用,那就统一都添加到 ht[1] 中就好了。
最后我们再对比一下 Java HashMap 扩容操作,它是一个一次性操作,每次扩容需要将所有键值对都迁移到新的数组中,所以如果数据量很大,消耗时间就会久。
总结
Redis 字典使用哈希表作为底层实现,每个字典包含两个哈希表,一个平时使用,一个仅在 rehash 操作中使用。
哈希表总的来说,跟 Java HashMap 真的很类似,底层实现也是一个数组加链表数据结构。
最后,当对哈希表进行扩容操作时间,将会采用渐进性 rehash 操作,慢慢将所有键值对迁移到新哈希表中。
其实了解 Redis 字典的其中的原理,再去比较 Java HashMap ,其实可以发现这两者有如此多的相似点。
所以学习这类知识时,不要仅仅去背,我们要了解其底层原理,知其然知其所以然。
帮助资料
欢迎关注我的公众号:程序通事,获得日常干货推送。如果您对我的专题内容感兴趣,也可以关注我的博客:studyidea.cn
阿里面试官:HashMap 熟悉吧?好的,那就来聊聊 Redis 字典吧!的更多相关文章
- 厉害!这份阿里面试官 甩出的Spring源码笔记,GitHub上已经爆火
前言 时至今日,Spring 在 Java 生态系统与就业市场上,面试出镜率之高,投产规模之广,无出其右.随着技术的发展,Spring 从往日的 IoC 框架,已发展成 Cloud Native 基础 ...
- 阿里面试官用HashMap把我问倒了
本人是一名大三学生,最近在找暑期实习,其中也面试过两次阿里,一次菜鸟网络部门.一次网商银行部门,当然我都失败了,同时也让我印象很深刻,因此记录了其中一些面试心得,我觉得这个问题很值得分享,因此分享给大 ...
- 当阿里面试官问我:Java创建线程有几种方式?我就知道问题没那么简单
这是最新的大厂面试系列,还原真实场景,提炼出知识点分享给大家. 点赞再看,养成习惯~ 微信搜索[武哥聊编程],关注这个 Java 菜鸟. 昨天有个小伙伴去阿里面试实习生岗位,面试官问他了一个老生常谈的 ...
- 100道Java高频面试题(阿里面试官整理)
我分享文章的时候,有个读者回复说他去年就关注了我的微信公众号,打算看完我的所有文章,然后去面试,结果我后来很长时间不更新了...所以为了弥补一直等我的娃儿们,给大家的金三银四准备了100道花时间准备的 ...
- 阿里面试官:字符串在JVM中如何存放?90%的人就真的只回答在哪里存放
目录: 一道面试题的引出 案例分析 intern 源码分析 总结 1. 一道面试题的引出 在面试BAT这种一线大厂时,如果面试官问道:字符串在 JVM 中如何存放?大多数人能顺利的给出如下答案: 字符 ...
- 阿里面试官让我实现一个线程安全并且可以设置过期时间的LRU缓存,我蒙了!
目录 1. LRU 缓存介绍 2. ConcurrentLinkedQueue简单介绍 3. ReadWriteLock简单介绍 4.ScheduledExecutorService 简单介绍 5. ...
- 阿里面试官最喜欢问的21个HashMap面试题
1.HashMap 的数据结构? A:哈希表结构(链表散列:数组+链表)实现,结合数组和链表的优点.当链表长度超过 8 时,链表转换为红黑树. transient Node<K,V>\[\ ...
- 阿里面试官让我讲讲Unicode,我讲了3秒说没了,面试官说你可真菜
本文首发于微信公众号:程序员乔戈里 乔哥:首先说说什么是Unicode.码点吧~要想搞懂,这些概念必须清楚 什么是Unicode? 下图来自http://www.unicode.org/standar ...
- 阿里技术专家十五问,真题面试刀刀见肉,快来和阿里面试官battle
引言 2020阿里巴巴专家组出题,等你来答: 题目:如何判断两个链表是否相交 出题人:阿里巴巴新零售技术质量部 参考答案: $O(n^2)$: 两层遍历,总能发现是否相交 $O(n)$: 一层遍历,遍 ...
随机推荐
- 太鸡冻了!我用 Python 偷偷查到暗恋女生的名字
1 目 标 场 景 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人 ...
- 微信公众号怎么发PDF文件?
微信公众号怎么发PDF文件? 我们都知道创建一个微信公众号,在公众号中发布一些文章是非常简单的,但公众号添加附件下载的功能却被限制,如今可以使用小程序“微附件”进行在公众号中添加附件. 以下是公众 ...
- 我搭的神经网络不work该怎么办!看看这11条新手最容易犯的错误
1. 忘了数据规范化 2. 没有检查结果 3. 忘了数据预处理 4. 忘了正则化 5. 设置了过大的批次大小 6. 使用了不适当的学习率 7. 在最后一层使用了错误的激活函数 8. 网络含有不良梯度 ...
- 2020-05-31:假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
福哥答案2020-05-31: 使用keys指令可以扫出指定模式的key列表.对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?这个时候你要回答redis关键的 ...
- 怎么把txt转换成excel
地址: https://jingyan.baidu.com/article/c1465413b2f2c50bfdfc4c61.html
- 企业项目实战 .Net Core + Vue/Angular 分库分表日志系统 | 控制反转搭配简单业务
教程预览 01 | 前言 02 | 简单的分库分表设计 03 | 控制反转搭配简单业务 说明 我们上一节已经成功通过 连接提供程序存储库,获取到了 连接提供程序,但是连接提供程序和数据库连接依赖太深, ...
- .NET Core + K8S + Apollo 玩转配置中心
1.引言 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性,适用于微服务配置管理 ...
- VUE数据更新视图不更新的原因
当你利用索引直接设置一个项时,例如:vm.items[indexOfItem] = newValue当你修改数组的长度时,例如:vm.items.length = newLength 数组更新只能通过 ...
- Redis哨兵模式的配置
绪论 现有三台设备,192.168.137.11.192.168.137.12和192.168.137.13,要求在三台设备上实现redis哨兵模式,其中192.168.137.11为master,其 ...
- linux驱动之定时器的使用
被文章摘自一下几位网友.非常感谢他们. http://blog.sina.com.cn/s/blog_57330c3401011cq3.html Linux的内核中定义了一个定时器的结构: #incl ...