未来云原生世界的“领头羊”:容器批量计算项目Volcano 1.0版本发布
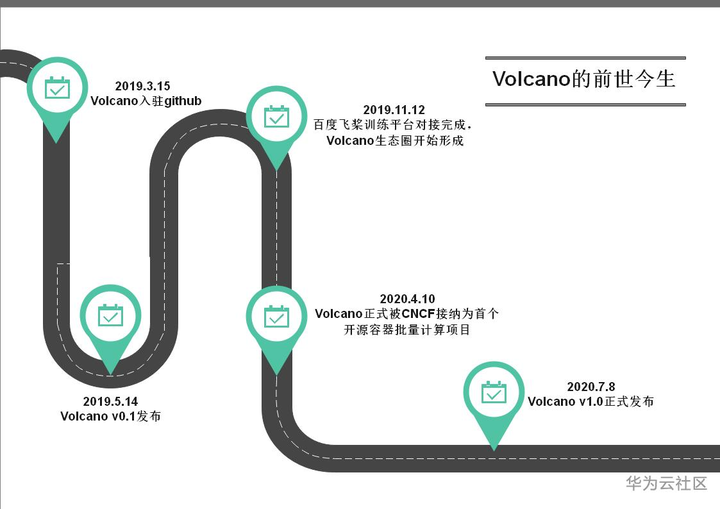
在刚刚结束的CLOUD NATIVE+ OPEN SOURCE Virtual Summit China 2020上,由华为云云原生团队主导的容器批量计算项目Volcano正式发布1.0版本,标志着Volcano项目已经开始走向成熟与稳定。
Volcano项目介绍
Volcano是基于Kubernetes的云原生批量计算引擎,基于华为云在AI、大数据领域的深厚业务积累,补齐了Kubernetes在面向AI、大数据、高性能计算等批量计算任务调度、编排等场景下的短板,向下支持鲲鹏、昇腾、X86等多元算力,向上使能TensorFlow、Spark、华为MindSpore等主流行业计算框架,让数据科学家和算法工程师充分享受到云原生技术所带来的高效计算与极致体验。
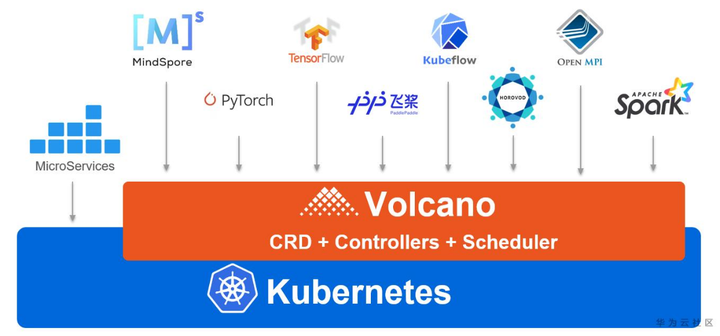
Volcano架构示意图
随着Kubernetes作为AI、大数据和高性能批量计算的下一代基础设施的趋势逐渐清晰,越来越多的企业对Kubernetes在深度学习、科学计算、高性能渲染等方面提出了更高的要求。
然而Kubernetes作为普适的容器化解决方案,仍与业务诉求存在一定差距,主要体现在:
- K8s的原生调度功能无法满足计算要求
- K8s作业管理能力无法满足AI训练的复杂诉求
- 数据管理方面,缺少计算侧数据缓存能力,数据位置感知等功能
- 资源管理方面缺少分时共享,利用率低
- 硬件异构能力弱
Volcano的诞生正是基于这些痛点,在调度、作业管理、数据管理、资源管理四个方面进行了重点优化。
- 增强了任务调度能力,如公平的调度(fair-share)、组调度(gang-scheduling)
- 进一步优化了作业管理能力,如multiple pod template能力、更灵活的error handling机制
- 增加计算侧数据缓存,提升数据的传输与读取效率
- 引入多维度的综合评分机制,实现资源更高效的管理和分配
- 多元算力支持:支持x86、鲲鹏和昇腾等算力
Volcano v1.0新特性介绍
Volcano v1.0的核心概念和关键特性,主要包含以下要点:
- Queue、PodGroup、Volcano Job等核心概念均已实现
- 支持Binpack、Conformance、DRF、Gang、Preempt、Reclaim、Priority、Proportion等多种调度策略
- 支持Rest API、CLI等多种交互方式
- 完成与Spark、Argo、MPI、Flink、Mxnet、Paddlepaddle、Tensorflow、MindSpore等主流高性能计算框架的无缝对接
- 支持Job的全生命周期管理和动态扩缩容
- 支持GPU异构与共享
- 完备的golangCI-lint check、e2e以建立增强代码质量和稳定性
除以上特性外,Volcano始终保持与Kubernetes社区、Golang最新版本保持一致。
Volcano社区和生态建设进展
经过一年多的发展,Volcano的社区和生态建设已经步入快车道。截至目前,社区和生态建设取得了以下成绩:
- 社区贡献者80+
- 社区贡献参与组织15+,包括华为、百度、腾讯、AWS、IBM、 Oracle等
- 获得Star 1100+,Fork 220+
- 代码库7个,Release 6个
- Issue 320+,PR 590+
- 已完成对Spark、Argo、MPI、Flink、Mxnet、Paddlepaddle、Tensorflow、MindSpore、Cromwell等10+主流计算框架的支持
- 华为云CCE(云容器引擎)、CCI(云容器实例)、ModelArts等多个云服务已将Volcano集成为基础设施底座并商用,服务领域已涵盖AI、大数据应用、基因计算、批处理等场景,并实现与华为鲲鹏、昇腾处理器深度融合,最快每秒1000个容器的调度发放,成为高性能、极致性价比的批量计算解决方案。
深入了解Volcano
如果想更加深入了解Volcano,可以参考以下资源:
Volcano官网:
https://volcano.sh/
Github:
https://github.com/volcano-sh
Volcano简介:
https://github.com/volcano-sh/volcano
Volcano设计:
https://github.com/volcano-sh/volcano/tree/master/docs/design
Volcano路线图:
https://github.com/volcano-sh/volcano/blob/master/docs/community/roadmap.md
Volcano社区交流微信群:
Volcano CN
未来可期
随着Volcano v1.0的发布,Volcano社区建设与上下游生态的融合必将更加紧密,基于Volcano的商业应用也将极大地促进AI、大数据、科学计算、渲染等领域充分享受到云计算带来的极大便利和极致体验,助力企业数字化转型进入新的高度。
展望未来,华为云也将在云原生领域持续耕耘,持续引领创新、繁荣生态,助力各行业走向快速智能发展之路。
未来云原生世界的“领头羊”:容器批量计算项目Volcano 1.0版本发布的更多相关文章
- 重磅!业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目
摘要:4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个云原生批量计算项目Volcano正式晋级为CNCF孵化项目. 4月7日,云原生计算基金会(CNCF)宣布,由华为云捐献的业界首个 ...
- 谈到云原生, 绕不开"容器化"
传送门 什么是云原生? 云原生设计理念 .NET微服务 Containers 现在谈到云原生, 绕不开"容器". 在<Cloud Native Patterns>一书中 ...
- 支持边云协同终身学习特性,KubeEdge子项目Sedna 0.3.0版本发布!
摘要:随着边缘设备数量指数级增长以及设备性能的提升,边云协同机器学习应运而生,以期打通机器学习的最后一公里. 本文分享自华为云社区<支持边云协同终身学习特性,KubeEdge子项目Sedna 0 ...
- 云原生交付加速!容器镜像服务企业版支持 Helm Chart
2018 年 6 月,Helm 正式加入了 CNCF 孵化项目:2018 年 8 月,据 CNCF 的调研表明,有百分之六十八的开发者选择了 Helm 作为其应用包装方案:2019 年 6 月,阿里云 ...
- 未来云原生 | CIF 论坛精彩看点
当下云原生技术正在飞速发展,那么如何准确理解「云原生」?在发展不够成熟,行业认知差异大的情况下,不论是云原生计算基金会(CNCF),还是行业的任何大咖,都不能给出精确的.便于理解的定义.我们要理解的逻 ...
- 云原生时代之Kubernetes容器编排初步探索及部署、使用实战-v1.22
概述 **本人博客网站 **IT小神 www.itxiaoshen.com Kubernetes官网地址 https://kubernetes.io Kubernetes GitHub源码地址 htt ...
- 初探云原生应用管理之:聊聊 Tekton 项目
[编者的话]“人间四月芳菲尽,山寺桃花始盛开.” 越来越多专门给 Kubernetes 做应用发布的工具开始缤纷呈现,帮助大家管理和发布不断增多的 Kubernetes 应用.在做技术选型的时候,我们 ...
- Volcano火山:容器与批量计算的碰撞
[摘要] Volcano是基于Kubernetes构建的一个通用批量计算系统,它弥补了Kubernetes在“高性能应用”方面的不足,支持TensorFlow.Spark.MindSpore等多个领域 ...
- 从Vessel到二代裸金属容器,云原生的新一波技术浪潮涌向何处?
摘要:云原生大势,深度解读华为云四大容器解决方案如何加速技术产业融合. 云原生,可能是这两年云服务领域最火的词. 相较于传统的应用架构,云原生构建应用简便快捷,部署应用轻松自如.运行应用按需伸缩,是企 ...
随机推荐
- JVM 专题三:类加载子系统(一)类装载器子系统
类装载器子系统 1.1 什么是类装载子系统? 类装载器子系统负责从文件系统或者网络中加载Class文件,Class文件在文件开头有特定的文件标识(魔数). 类装载器子系统(ClassLoader)只负 ...
- css 实现动态二级菜单
动态实现简单的二级菜单 当鼠标放到一级标签上时,鼠标会变成小手的形状 展示二级菜单,源码如下,复制即可直接使用 <!DOCTYPE html> <html lang="en ...
- 树形dp 之 小胖守皇宫
题目描述 huyichen世子事件后,xuzhenyi成了皇上特聘的御前一品侍卫. 皇宫以午门为起点,直到后宫嫔妃们的寝宫,呈一棵树的形状:有边相连的宫殿间可以互相望见.大内保卫森严,三步一岗,五步一 ...
- 使用SQL语句进行特定值排序
使用SQL语句进行查询时,对数据进行排序,排序要求为排序的一个字段中特定值为顶部呈现: select * from TableName order by case TableFieldName whe ...
- Laravel 5.4 使用 Mail 发送邮件获取验证码功能(使用的配置邮箱为126邮箱)
<?php namespace App\Modules\Liveapi\Http\Controllers\Personnel; use App\Modules\Liveapi\Http\Cont ...
- 大型Java进阶专题(九) 设计模式之总结
前言 关于设计模式的文章就到这里了,学习这门多设计模式,你是不是有这样的疑惑,发现很多设计模式很类似,经常会混淆某些设计模式.这章节我们将对设计模式做一个总结,看看各类设计模式有什么区别.需要注意 ...
- vant ui 吸顶组件慎用 2020-1-15
- python3的字符串常用方法
find()# 方法 find()# 范围查找子串,返回索引值,找不到返回-1 # 语法 s.find(substring, start=0, end=len(string)) # 参数 # subs ...
- spring学习(七)spring整合JDBC
Spring中封装了一个可操作数据库的对象,该对象封装了JDBC技术 使用数据库 一.导包(IDEA的maven工程,在pom.xml文件中导入依赖,必须注意依赖,不然会报各种异常) <?xml ...
- 从零开始学Python网络爬虫PDF高清完整版免费下载|百度网盘
百度网盘:从零开始学Python网络爬虫PDF高清完整版免费下载 提取码:wy36 目录 前言第1章 Python零基础语法入门 11.1 Python与PyCharm安装 11.1.1 Python ...