第14.4节 使用IE浏览器获取网站访问的http信息
上节《第14.3节 使用google浏览器获取网站访问的http信息》中介绍了使用Google浏览器怎么获取网站访问的http相关报文信息,本节介绍IE浏览器中怎么获取相关信息。以上节为基础,部分http相关知识在此不再介绍。
步骤1:登录网站并打开准备获取信息的网页
步骤2:在网页上按F12或选择对应内容后鼠标右键选择检查元素(如下图)
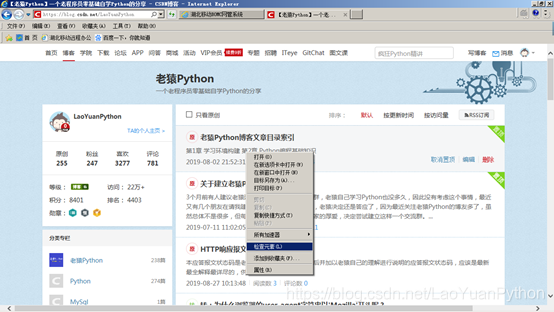
打开开发者工具并点击下图左上角蓝色标记的“启用网络流量捕获”的按钮开始捕获网页的网络报文:

回到网页访问窗口刷新页面再回到开发者工具窗口禁用捕获,防止捕获多余的网络信息干扰分析。选择第一条网络报文(如下图):
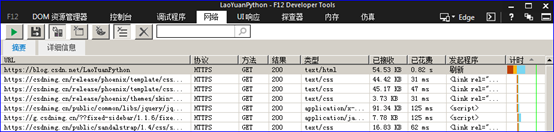
鼠标双击打开,获得该请求的具体信息如下图:
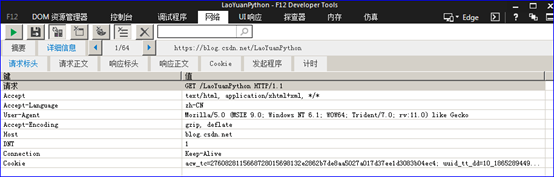
选择下图黄色标记的“响应标头”,出现响应报文头信息如下:

这样就获取了IE浏览器的请求报文相关信息,同样可以获取响应报文的信息。获取这些信息后,我们可以复制相关信息用于Python应用中模拟浏览器访问网站。
本节老猿介绍的案例是基于IE11版本的,当然浏览器的不同版本上述界面会有所差异,但总体应该差不多。除Google和IE外的其他浏览器老猿没有研究,不知道是否有开发者工具,如果有相关功能应该也差不多的。
老猿Python,跟老猿学Python!
博客地址:https://blog.csdn.net/LaoYuanPython
老猿Python博客文章目录:https://blog.csdn.net/LaoYuanPython/article/details/98245036
请大家多多支持,点赞、评论和加关注!谢谢!
第14.4节 使用IE浏览器获取网站访问的http信息的更多相关文章
- 第14.7节 Python模拟浏览器访问实现http报文体压缩传输
一. 引言 在<第14.6节 Python模拟浏览器访问网页的实现代码>介绍了使用urllib包的request模块访问网页的方法.但上节特别说明http报文头Accept-Encodin ...
- YII2.0 获取当前访问地址/IP信息
假设我们当前页面的访问地址是:http://localhost/CMS/public/index.php?r=news&id=1 一. 1.获取当前域名:echo Yii::app()-> ...
- 第14.5节 利用浏览器获取的http信息构造Python网页访问的http请求头
一. 引言 在<第14.3节 使用google浏览器获取网站访问的http信息>和<第14.4节 使用IE浏览器获取网站访问的http信息>中介绍了使用Google浏览器和IE ...
- 第14.17节 爬虫实战3: request+BeautifulSoup实现自动获取本机上网公网地址
一. 引言 一般情况下,没有特殊要求的客户,宽带服务提供商提供的上网服务,给客户家庭宽带分配的地址都是一个宽带服务提供商的内部服务地址,真正对外访问时通过NAT进行映射到一个公网地址,如果我们想确认自 ...
- 第14.6节 使用Python urllib.request模拟浏览器访问网页的实现代码
Python要访问一个网页并读取网页内容非常简单,在利用<第14.5节 利用浏览器获取的http信息构造Python网页访问的http请求头>的方法构建了请求http报文的请求头情况下,使 ...
- 第14.1节 通过Python爬取网页的学习步骤
如果要从一个互联网前端开发的小白,学习爬虫开发,结合自己的经验老猿认为爬虫学习之路应该是这样的: 一. 了解HTML语言及css知识 这方面的知识请大家通过w3school 去学习,老猿对于html总 ...
- 第14.9节 Python中使用urllib.request+BeautifulSoup获取url访问的基本信息
利用urllib.request读取url文档的内容并使用BeautifulSoup解析后,可以通过一些基本的BeautifulSoup对象输出html文档的基本信息.以博文<第14.6节 使用 ...
- 第14.18节 爬虫实战4: request+BeautifulSoup+os实现利用公众服务Wi-Fi作为公网IP动态地址池
写在前面:本文相关方法为作者独创,仅供参考学习爬虫技术使用,请勿用作它途,禁止转载! 一. 引言 在爬虫爬取网页时,有时候希望不同的时候能以不同公网地址去爬取相关的内容,去网上购买地址资源池是大部分人 ...
- 第14.16节 爬虫实战2:赠人玫瑰,手留余香! request+BeautifulSoup实现csdn博文自动点赞
写在前面:本文仅供参考学习,请勿用作它途,禁止转载! 在<第14.14节 爬虫实战准备:csdn博文点赞过程http请求和响应信息分析>老猿分析了csdn博文点赞处理的http请求和响应报 ...
随机推荐
- 等效介质理论模型---利用S参数反演法提取超材料结构的等效参数
等效介质理论模型---利用S参数反演法提取超材料结构的等效参数 S参数反演法,即利用等效模型的传输矩阵和S参数求解超材料结构的等效折射率n和等效阻抗Z的过程.本文对等效介质理论模型进行了详细介绍,并提 ...
- HTML5 实现的一个俄罗斯方块实例代码
/*实现的功能:方块旋转(W键).自动下落.移动(ASD).消行.快速下落(空格键).下落阴影.游戏结束.*/ <!DOCTYPE html> <html> < ...
- MSSQL 指定分隔符号 生成数据集
DECLARE @xml VARCHAR(MAX)='磨毛:1 缩率:2 干磨:3 湿摩:4 水洗牢度:5 手感:6 防水:7 PH:8 日晒:9' SET @xml= '<root>'+ ...
- Centos7上一次War包的部署与运行
Centos7上一次War包的部署与运行 前言 由于前段时间第一次部署一个小型的项目,时间一长所以有些步骤有时候时间一长就忘了,在此做个简单的记录 一.原始系统开发环境 操作系统:Windows10: ...
- 在Linux下的安装mysql-5.7.28 心得总结
mysql-5.7.28 在Linux下的安装教程图解 这篇文章主要介绍了mysql-5.7.28 的Linux安装,本文通过图文并茂的形式给大家介绍的非常详细,具有一定的参考借鉴价值,希望给有需要的 ...
- 掉电后osdmap丢失无法启动osd的解决方案
前言 本篇讲述的是一个比较极端的故障的恢复场景,在整个集群全部服务器突然掉电的时候,osd里面的osdmap可能会出现没刷到磁盘上的情况,这个时候osdmap的最新版本为空或者为没有这个文件 还有一种 ...
- JavaScript复习大纲
1. HTML.CSS和JavaScript各自在网页设计中的作用. 1.HTML生成结构. 2.CSS样式美化. 3.JavaScript的作用: (1) 操作HTML及CSS,让网页具有动态行为. ...
- IP地址分类的计算方法
IP地址由四段组成,每个字段是一个字节,8位,最大值是255,但实际中我们用点分十进制记法. IP地址由两部分组成,即网络地址和主机地址.网络地址表示其属于互联网的哪一个网络(常见ABC三类,以固定网 ...
- a标签禁用
a标签禁用可以使用CSS3的特性来控制 <a class="disabled">我是a标签</a> a.disabled { pointer-events: ...
- 掌握Python可以去哪些岗位?薪资如何?
一.人工智能 Python作为人工智能的黄金语言,选择人工智能作为就业方向是理所当然的,就业前景也还不错.人工智能工程师的招聘起薪一般在20K-35K,如果是初级工程师,起薪一般12K. 二.大数据 ...