Python内存浅析
Python内存分析
内存机制
转述:内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。
Python的内存机制和Java差不多,分为i栈内存区、堆内存区、常量区、数据区
换一句别人的话来说:内存空间在逻辑上分为三部分:代码区、静态数据区和动态数据区,动态数据区又分为栈区和堆区

栈内存区
栈内存(Stack):栈内存比较小,但是速度快。一般存储运行方法的形参、局部变量、返回值。由系统自动分配和回收
堆内存
堆内存(Heap):对内存一般比较大,但是速度慢。一般放对象
静态存储区
静态存储区(Stastic):这个区域也可以叫做常量池。存储全局变量、静态变量、常量,常量包括final修饰的常量和String常量。系统自动分配和回收
数据区
数据区(Data):这个区域专门加载代码字节数据,方法数据、函数等.高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换.
变量在内存中的存储
可变数据和不可变数据
可变数据:列表(list)、字典(dict)
不可变数据:整型(int)、浮点型(float)、字符串型(String)、元组(tuple)
为什么要区别可变和不可变?
这里的可变和不可变指的是内存中的那块内容是否可变,当数据是可变的时候,对数据进行操作时并不需要重新申请新的内存空间,只需要在此数据空间后连续申请即可。而当数据是不可变时,对数据进行一些操作的时候是需要重新在内存中申请一段新的空间,来存放新的数据。
实例
看几个实例来更深入的认识内存分配:
例子1
a = "Hello"
b = 3
c = ["Hello", 3]
print(id(a), id(b)) # 140415037732720 93831947674432
print(id(c[0]), id(c[1])) # 140415037732720 93831947674432
内存图:
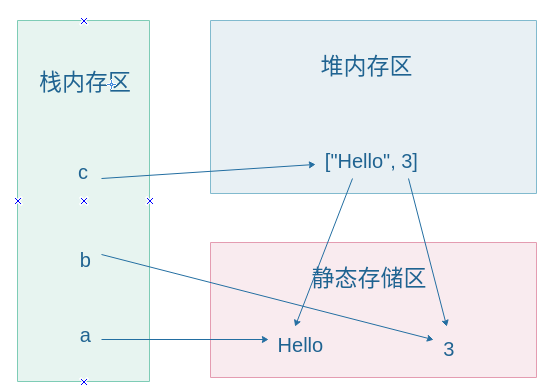
因为Hello和3都是常量,所以打印出来的内存地址是相同的
例子2
class Person:
def __init__(self):
self.name = "二狗子"
self.age = 20
self.relatives = ["舅舅", "姑姑", "大爷"]
p = Person()
print(id(p.name), id(p.age)) # 140415037701936 93831947674976
p.name = "狗蛋"
p.age = 18
print(id(p.name), id(p.age)) # 140415037701840 93831947674912
内存图:
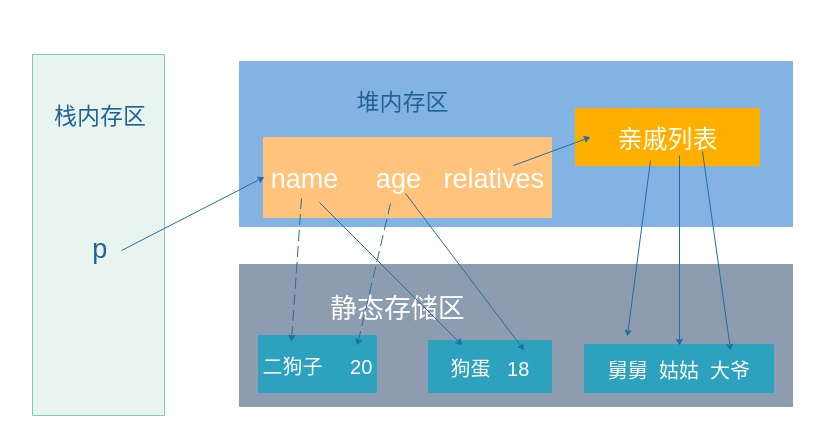
因为name是String字符串,age也是年龄都是常量,所以都是在静态存储区,并且当改变时是另开辟空间来存储新的数据。但是原来的数据并没有改变,所以打印出来的内存地址是不同的。
代码验证
来一个更有思考性的例子:
# 不可变数据
a = "Hello"
print('a的内存地址为:', id(a))
a = "World"
print('改变后a的内存地址为:', id(a))
# 可变数据
l = [12, 13, 15, 18, 20, "hello", ["world", "python"]]
b = 12
print(b, "的内存地址为:" ,id(b), id(l[0]))
b = "hello"
print(b, "的内存地址为:" ,id(b), id(l[0]))
b = ["world", "python"]
print(b, "的内存地址为:" ,id(b), id(l[0]))
print('b的内存地址为:', id(l))
l.append(4)
print('改变后b的内存地址为:', id(l))
id() 函数返回对象的唯一标识符,标识符是一个整数。
结果为:
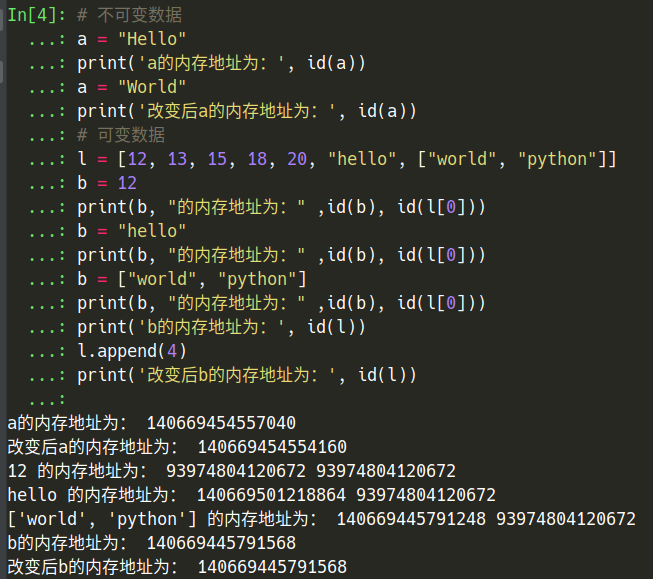
由此可知,列表当中存储的也是各个元素的内存地址,而这些最终也会指向静态区。
Python内存浅析的更多相关文章
- Jvm 内存浅析 及 GC个人学习总结
从诞生至今,20多年过去,Java至今仍是使用最为广泛的语言.这仰赖于Java提供的各种技术和特性,让开发人员能优雅的编写高效的程序.今天我们就来说说Java的一项基本但非常重要的技术内存管理 了解C ...
- python内存管理机制
主要分为三部分: (1)内存池机制(2)引用计数(3)垃圾回收 (1)内存池机制对于python来说,对象的类型和内存都是在运行时确定的,所以python对象都是动态类型简单来说,python内存分为 ...
- 解读Python内存管理机制
转自:http://developer.51cto.com/art/201007/213585.htm 内存管理,对于Python这样的动态语言,是至关重要的一部分,它在很大程度上甚至决定了Pytho ...
- 转发:[Python]内存管理
本文为转发,原地址为:http://chenrudan.github.io/blog/2016/04/23/pythonmemorycontrol.html 本文主要为了解释清楚python的内存管理 ...
- python 内存泄露的诊断 - 独立思考 - ITeye技术网站
python 内存泄露的诊断 - 独立思考 - ITeye技术网站 python 内存泄露的诊断 博客分类: 编程语言: Python Python多线程Blog.net 对于一个用 python ...
- Python内存优化
实际项目中,pythoner更加关注的是Python的性能问题,之前也写过一篇文章<Python性能优化>介绍Python性能优化的一些方法.而本文,关注的是Python的内存优化,一般说 ...
- 使用gc、objgraph干掉python内存泄露与循环引用!
Python使用引用计数和垃圾回收来做内存管理,前面也写过一遍文章<Python内存优化>,介绍了在python中,如何profile内存使用情况,并做出相应的优化.本文介绍两个更致命的问 ...
- python 内存NoSQL数据库
python 内存NoSQL数据库 来自于网络,经过修改,秉承Open Source精神,回馈网络! #!/usr/bin/python #-*- coding: UTF-8 -*- # # memd ...
- [转] 使用gc && objgraph 优化python内存
转自https://www.cnblogs.com/xybaby/p/7491656.html 使用gc.objgraph干掉python内存泄露与循环引用! 目录 一分钟版本 python内存管 ...
随机推荐
- 它听键盘声就知道你敲的是什么——GitHub 热点速览 Vol.51
作者:HelloGitHub-小鱼干 本以为本周的 GitHub 和十二月一样平平无奇就那么度过了,结果 BackgroundMattingV2 重新刷新了本人的认知,还能这种骚操作在线实时抠视频去背 ...
- 唐诗宋词APP
古诗词个人爱好,已收集5万多首唐诗以及1万多首宋词,因时间有限目前只开发了苹果版,后期开发安卓版, <风月醉>一 国学经典,有兴趣的可以下载学习古诗词,有问题可以留言哦! https:// ...
- git使用上
因为最近工作上多处都用到了基于 Git 的开发,需要深入理解 Git 的工作原理,以往的 Git 基本知识已经满足不了需求了,因此写下这篇 Git 进阶的文章,主要是介绍了一些大家平时会碰到但是很少去 ...
- C++雾中风景16:std::make_index_sequence, 来试一试新的黑魔法吧
C++14在标准库里添加了一个很有意思的元函数: std::integer_sequence.并且通过它衍生出了一系列的帮助模板: std::make_integer_sequence, std::m ...
- Lightweight Render Pipeline
(翻译) Lightweight Render Pipeline (LWRP),轻量级渲染管线,是一个Unity预制的Scriptable Render Pipeline (SRP).LWRP可以为移 ...
- TensorFlow 基础概念
初识TensorFlow,看了几天教程后有些无聊,决定写些东西,来夯实一下基础,提供些前进动力. 一.Session.run()和Tensor.eval()的区别: 最主要的区别就是可以使用sess. ...
- TCP VS UDP
摘要:计算机网络基础 引言 网络协议是每个前端工程师都必须要掌握的知识,TCP/IP 中有两个具有代表性的传输层协议,分别是 TCP 和 UDP,本文将介绍下这两者以及它们之间的区别. 一.TCP/I ...
- 任意文件下载漏洞的接口URL构造分析与讨论
文件下载接口的URL构造分析与讨论 某学院的文件下载接口 http://www.****.edu.cn/item/filedown.asp?id=76749&Ext=rar&fname ...
- 剑指offer 面试题3:数组中重复的数字
题目描述 在一个长度为n的数组里的所有数字都在0到n-1的范围内. 数组中某些数字是重复的,但不知道有几个数字是重复的.也不知道每个数字重复几次.请找出数组中任意一个重复的数字. 例如,如果输入长度为 ...
- Deep Learn I'm back.
Intorduction: 时隔好几个月,我准备重新进入Deep Learning 的领域.昨天和老师聊了很多,之前觉得我做的工作就是排列组合,在水论文,灌水.但老师却说:这也是为将来的研究打基础. ...