On-Demand Learning for Deep Image Restoration
摘要
论文来源:ICCV 2017
之前的缺点:目前的机器学习方法只专注于在特定困难程度的图像损坏(如一定程度的噪声或模糊)情况下进行良好的训练模型。
改进的方法:提出了一种基于深度卷积神经网络的按需学习算法来训练图像恢复模型。
优势之处:其主要思想是利用反馈机制,在最需要的地方自行生成训练实例,从而学习模型,可以在不同难度级别上泛化。在四项恢复任务(图像修复、像素插值、图像去模糊和图像去噪)和三种不同的数据集上,我们的方法始终优于现有的训练程序和课程学习方案。
网络结构:
数据集:CelebFaces Attributes 、SUN397 Scenes、the Denoising Benchmark 11
code:
介绍
现状
图像损坏存在不同程度的严重程度,因此在现实应用中恢复图像的难度也会有很大差异,inpainter可能会面对缺失内容大小不同的图像,而去模糊系统可能会遇到不同程度的模糊。直观上,缺失的像素越多或者模糊越严重,恢复任务就越困难。
现有的深度学习方法的准则是训练一个模型,成功地恢复显示出特定程度的损坏图像。简单地汇集所有难度级别的训练实例会使深度网络难以充分地学习这个概念。
本文提出的方法
我们的方法依赖于一种反馈机制,在训练的每个阶段,让系统引导自己的学习朝着每个难度级别正确的子任务比例前进。通过这种方式,系统本身可以发现哪些子任务值得更多或更少的关注。
我们设计了一个通用的编码器解码器网络实现几个恢复任务。我们评估了4个低级任务——修复、像素插值、图像去模糊和去噪——以及3个不同的数据集、CelebFaces Attributes 、SUN397 Scenes和the Denoising Benchmark 11
本文的贡献
在所有的任务和数据集上,结果一致地证明了我们的方法的优势。随需应变学习有助于避免深度网络过度专门化而导致窄带失真困难的常见陷阱(但迄今为止被忽视了)。
相关工作
Deep Learning in Low-Level Vision
堆叠去噪自动编码器、Burger等人采用多层感知器(multi-layer perceptron, MLP)进行图像去噪,Schuler等人采用后去噪。卷积神经网络也应用于自然图像去噪,并用于去除噪声模式(如污垢/雨水)。除了去噪,深度学习也在其他各种低级任务中获得了吸引力:超分辨率[、inpainting[31,43]、deconvolution[42]、matting和着色。虽然许多模型专门化的体系结构为一个恢复任务,最近的工作我们的编码器-解码器管道也适用于不同的任务,并为我们的主要贡献——按需学习的想法——提供了一个良好的测试平台。
Curriculum and Self-Paced Learning
像自定进度的学习一样,我们的方法不依赖于人工注释来将训练示例从最容易到最难排序。然而,与自定进度的工作不同,我们的按需方法会自动生成目标难度的训练实例。
Active Learning
与主动学习不同,我们的方法不使用人工标注,而是根据训练的进度主动合成不同损坏程度的训练实例。我们所有的训练数据都可以“免费”获得,并且基本事实(原始未被破坏的图像)总是可用的。
The Fixation Problem(固有问题)
Pathak主要集中在一个大的中心块进行修复任务。刘解决去噪、像素插值和颜色插值任务,所有这些任务都有一定程度的损坏。虽然这种方法可以确定训练中的损坏程度,作为概念的证明,但它们并不能提供一种使模型普遍适用的解决办法。

图像修复和去模糊的过拟合严重程度的说明。这些模型在一定程度上过度损坏。它们在此种损坏程度下表现得非常好,但是即使对于容易得多的子任务也不能产生令人满意的恢复结果。
为了以一般方式令人满意地应用它们,需要为每个超参数训练一个单独的模型。即使可以做到这一点,也很难衡量一个小说形象的损坏程度,并决定使用哪种模式。最后,正如我们将在下面看到的,简单地汇集所有难度级别的训练实例也是不够的。
Approach
Problem Formulation
我们将真实图像表示为R,将损坏的图像表示为C(例如,丢失了一个随机块)。我们通过p(R,C) = p(R)p(C|R)来模拟它们的联合概率分布,其中p(R)是真实图像的分布,p(C|R)是给定原始真实图像的损坏图像的分布。在固定模型的情况下,C可以是R的确定性函数(例如,特定模糊核)。
要恢复损坏的图像,最直接的方法是应用贝叶斯定理找到p(R|C)。但是,这是不可行的,因为p(R)是难以处理的。因此,我们通过一个编码器-解码器式的深层网络来进行点估计。通过最小化以下均方误差目标:
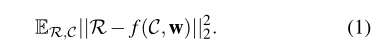
给定一个损坏的图像C0,上述目标的最小值是条件期望:ER[R|C = C0],它是可能产生给定损坏图像C0的所有可能的真实图像的平均值。表示真实图像集{Ri}。我们相应地合成损坏的图像{Ci},以产生训练图像对{Ri,Ci}。我们训练我们的深层网络,通过最小化均方误差目标的以下蒙特卡罗估计来学习其权重w:
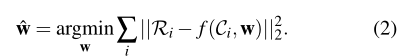
在测试过程中,我们训练的深度网络将损坏的图像C作为输入,并通过网络将其转发到输出f(C,w)作为恢复的图像。
Image Restoration Task Descriptions
在一般图像恢复解决方案的框架下,我们考虑四个任务。
- Image Inpainting 图像修复任务旨在重新填充丢失的区域,并重建不完整的损坏图像C的真实图像R(例如,去除了一组连续的像素)。
- Pixel Interpolation 像素插值与图像修复相关,像素插值旨在重新填充不连续的已删除像素。网络必须对图像结构进行推理,并通过从相邻像素进行插值来推断被删除像素的值。应用包括更精细的修补任务,如清除胶片上的灰尘斑点。
Image Deblurring 图像去模糊图像去模糊任务的目的是消除受损图像的模糊效应,以恢复相应的真实图像。我们使用高斯平滑来模糊真实图像,以创建训练示例。内核的水平和垂直宽度(sxand sy)控制模糊度,从而控制难度。应用包括消除运动模糊或散焦像差。
- Image Denoising 图像去噪任务旨在去除受损图像C的加性高斯白噪声(AWG)以恢复相应的真实图像R。我们通过添加来自方差为s(噪声水平)的零均值正态分布的噪声来损坏真实图像。
On-Demand Learning for Image Restoration
我们提出了一种按需学习的方法,在这种方法中,系统在最需要的地方动态调整其焦点。首先,我们将每个恢复任务分成N个难度递增的子任务。在训练过程中,我们的目标是联合训练深度神经网络恢复模型(架构细节如下),以适应所有N个子任务。最初,我们从每批中的每个子任务生成相同数量的训练例子。在每个时期结束时,我们在一个小的验证集上进行验证,并评估当前模型在所有子任务上的性能。我们计算每个子任务的验证集中所有图像的平均峰值信噪比(PSNR)。较低的PSNR表示更困难的子任务,这表明模型需要在这个子任务的例子上进行更多的训练。因此,我们在下一个时期的每一批中为这个子任务生成更多的训练示例。也就是说,我们重新分配分配给同一组训练图像的损坏级别。具体来说,我们在每一批中为下一个时期分配训练样本,与每个子任务T1的平均PSNR点成反比。
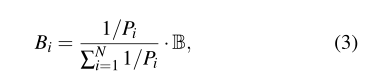
其中,B是批次大小,Bi是下一个时期分配给子任务Tif的训练样本数。
Deep Learning Network Architecture
编码器-解码器管道。编码器将大小为64⇥64的损坏图像c作为输入,并将其编码在潜在特征空间中。
解码器获取特征表示并输出复原图像f(C,w)。我们的编码器和解码器通过一个全通道连接层连接。我们在训练中使用的损失函数是L2损失,它是恢复图像f(C,w)和真实图像r之间的均方误差。
Experiments
实现细节
torch框架,ADAM为随机梯度下降优化器,batchsize B=100
按需学习的子任务数量控制着精度和运行时间之间的平衡。更大的N值将允许按需学习算法对其样本生成进行更细粒度的控制,这可以在每个时期结束时验证所有子任务的时间复杂度是0(N)。因此,在子任务中对训练示例进行更细粒度的划分是以训练期间运行时间更长为代价的。为了一致性,我们在训练中将每个图像恢复任务分为N = 5个难度级别。
- image inpaiting 专注于在图像的不同位置修复大小为1 X 1到30 X 30的缺失方块。范围分为以下五个区间,这五个区间定义了五个难度级别:
- Pixel Interpolation:我们通过去除随机百分比的像素来训练具有损坏图像的像素插值网络。百分比从范围[0%,75%]中取样。
- Image Deblurring: 模糊内核宽度sxand sy,从范围[0,5]中采样,控制难度级别。
- Image Denoising:使用灰度图像去噪。加性白高斯噪声的方差s从范围[0,100]采样。
Fixated Model vs. Our Model
按需算法成功地解决了固定问题,其中固定模型采用了与我们相同的网络架构。对于修复,固定模型(难/易)仅被训练来分别修复32⇥32或5⇥5中心块;对于像素插值,删除80%(难)或10%(易)像素;对于去模糊,level5(硬)或level11(易);对于去噪,s = 90(硬)或s = 10(易)。
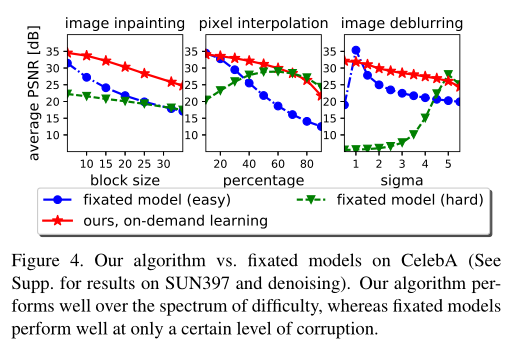
总结了CelebA数据集上各种损坏级别的图像的测试结果。固定的模型过渡到一个特定的损坏水平(容易或困难)。对于其特定范围内的图像,它非常成功,但是当被迫尝试其特定范围之外的实例时,它的表现很差。对于修复,固定的模型也过渡到中心位置,因此不能在整个光谱上表现良好。相比之下,使用我们的算法训练的模型在整个难度范围内表现良好。
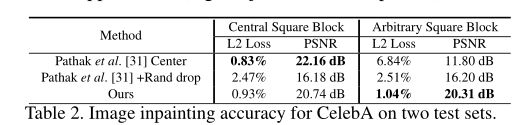
Comparison to Existing Inpainter
比较了本文图像修复器和来自context-encoder最先进的修复器。遵循相同的过程,在CelebA上训练两个变体:一个只训练修复中心正方形块,另一个训练使用随机区域缺失修复任意形状的区域。
表将这两种变体与我们在CelebA测试集上的模型进行了比较。他们的第一个修复程序在测试中心方块(左列)时表现非常好,但在测试位于图像任何位置的方块(右列)时,它无法产生令人满意的结果。他们的第二个模型在训练过程中使用了随机区域丢失,但是我们的修复器仍然表现得更好。此方法是具有竞争性的即使在更困难的任务中更强,即使没有在训练中使用的对抗性损失。
On-Demand Learning vs. Alternative Models

这些说明使用我们提出的按需方法训练的模型在不同腐败程度的图像上表现良好。使用单一模型,我们修复任意位置的不同大小的块,恢复具有不同百分比的删除像素的损坏图像,对不同模糊度的图像进行去模糊,并对不同噪声水平的图像进行去噪。相比之下,专注的模型只能在他们擅长的一个难度水平上表现良好。即使我们用小规模(64⇥64)图像进行效率实验,我们方法的定性结果在视觉上仍然优于包括刚性关节学习在内的其他基线。我们认为,我们的算法的增益并不依赖于某些子任务的更多训练实例,而是子任务的适当组合,以进行有效的训练。事实上,我们从未使用比任何基线更多的训练实例。
Conclusion
我们已经解决了利用深度模型解决图像恢复任务的现有工作中的一个常见问题:过拟合。我们设计了一个适用于所有图像恢复任务的对称编码器-解码器网络,并提出了一种简单但新颖的按需学习算法,该算法可以将固定模型转换为一个在整个难度范围内都能很好地执行任务的模型。在三个不同数据集上的四个任务上的实验证明了该方法的有效性。我们的按需学习思想是不限于图像恢复任务的一般概念,并且也可以应用于其他领域,例如自监督特征学习。作为未来的工作,我们计划设计连续的子任务来避免离散的子任务箱,我们将探索通过允许网络自行设计最理想的子任务来使图像恢复任务更加自定进度的方法。最后,另一个有希望的方向是探索不同类型失真的组合。
解码器获取特征表示并输出
原文: 可修改后右键重新翻译
On-Demand Learning for Deep Image Restoration的更多相关文章
- paper 124:【转载】无监督特征学习——Unsupervised feature learning and deep learning
来源:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio c ...
- 论文笔记之:Learning Cross-Modal Deep Representations for Robust Pedestrian Detection
Learning Cross-Modal Deep Representations for Robust Pedestrian Detection 2017-04-11 19:40:22 Moti ...
- (转)Understanding, generalisation, and transfer learning in deep neural networks
Understanding, generalisation, and transfer learning in deep neural networks FEBRUARY 27, 2017 Thi ...
- 转:无监督特征学习——Unsupervised feature learning and deep learning
http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio clas ...
- 论文笔记之:UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS
UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS ICLR 2 ...
- Incentivizing exploration in reinforcement learning with deep predictive models
Stadie, Bradly C., Sergey Levine, and Pieter Abbeel. "Incentivizing exploration in reinforcemen ...
- A Gentle Introduction to Transfer Learning for Deep Learning | 迁移学习
by Jason Brownlee on December 20, 2017 in Better Deep Learning Transfer learning is a machine learni ...
- This instability is a fundamental problem for gradient-based learning in deep neural networks. vanishing exploding gradient problem
The unstable gradient problem: The fundamental problem here isn't so much the vanishing gradient pro ...
- [转] 无监督特征学习——Unsupervised feature learning and deep learning
from:http://blog.csdn.net/abcjennifer/article/details/7804962 无监督学习近年来很热,先后应用于computer vision, audio ...
随机推荐
- Luogu P4208 [JSOI2008]最小生成树计数
题意 给定一个 \(n\) 个点 \(m\) 条边的图,求最小生成树的个数. \(\texttt{Data Range:}1\leq n\leq 100,1\leq m\leq 10^4\) 题解 一 ...
- node+express如何接收fromData
使用express-formidable来进行解析 安装 express-formidable npm install express-formidable 在app.js里放入已下代码 const ...
- 教你如何 分析 Android ANR 问题
ANR介绍 ANR 的全称是 Application No Responding,即应用程序无响应,具体是一些特定的 Message (Key Dispatch.Broadcast.Service) ...
- 【填坑往事】Android手机锁屏人脸解锁优化过程实录
背景 写这篇文章,主要是为了以后面试方便.因为我简历上写了,上一份工作的最大亮点是将人脸解锁的速度由1200ms优化到了600ms,所以这些内容已经回答无数遍了.但每次总觉得回答的不完整,或者说总感觉 ...
- Servlet基础使用总结
Servlet通俗理解:主要功能在于交互式地浏览和生成数据,生成动态Web内容.Servlet运行于支持Java的应用服务器中.从原理上讲,Servlet可以响应任何类型的请求,但绝大多数情况下Ser ...
- .NetCore Docker一次记录
1:项目添加docker支持 2:定位到项目主目录 按住shift,鼠标右键,打开powershell,输入命令 dotnet publish 此时会在目录 bin\Debug\netcoreapp2 ...
- boston.csv 完整版 508个数据集
https://pan.baidu.com/s/1C1Llx8cTu5xBdK9GuDZ11A 提取码:u6cm
- 搭建vue-cli4.0项目
① Vue CLI的包名称由 vue-cli 改成了 @vue/cli. 如果已经全局安装了旧版本的 vue-cli(1.x或2.x), 你需要先通过 npm uninstall vue-cli ...
- yum 的一些问题总结
1. yum 只删除目标,不删除依赖 rpm -e --nodeps xxx 2.yum remove 出错 报错 Error: Cannot retrieve repository metadata ...
- logback怎么写?分类输出日志到不同的文件
此appender有顺序,最好不要乱调顺序,输出日志如下: drwxr-xr-x 2 root root 4096 Dec 3 00:00 2019-12-02drwxr-xr-x 2 root ro ...