MySQL——事务ACID&隔离级别
数据库事务ACID&隔离级别
什么是事务
事务是用户定义的一个数据库操作序列。这些操作要么全执行,要么全不执行,是一个不可分割的工作单元。在关系型数据库中,事务可以是一条SQL语句,也可以是一组SQL语句或整个程序。
程序和事务是两个概念。一般地将,一个程序包含多个事务。
事务的开始和结束可以由用户显示控制。如果用户未显示定义事务,则有数据库管理系统按默认规定划分事务。在SQL中,定义事务的语句:
begin/start transaction
commit
rollback
事务通常以begin/start transaction开始,以commit或rollback结束。
- begin/start transaction 表示启动一个事务
- commit 表示提交,即提交事务的所有操作,将事务中所有对数据库的增删改写回到磁盘上的物理数据库中去,事务正常结束;
- rollback表示回滚,即在事务运行的过程中发生了某种故障,事务不能继续执行,将事务中所有对数据库已完成的增删改操作全部撤销,回滚到事务开始时的状态;
事务的ACID特性
事务具有四个特性:原子性(Atomicity)、一致性(Consistency)、隔离型(Isolation)、持久性(Durability),简称ACID。
- 原子性 事务是数据库的逻辑工作单位,事务中的操作不可拆分,要么全做,要么全不做;
- 一致性 事务的执行的结果必须使数据库从一个一致性状态变到另一个一致性状态;
- 隔离性 一个事务的执行不能被其它事务干扰,即一个事务的内部操作及使用的数据库对其他并发事务是隔离的,并发执行的各个事务之间互不干扰;
- 持久性 持久性也称永久性,一个事物一旦提交,它对数据库中的数据的改变就是永久性的,接下来的其他操作或故障不应该对其执行结果有任何影响;
举一个经典的银行转账例子:账户A余额1500元,账户B余额2000元,账户A需要想账户B转账1000;简单来说需要2步操作:第1步,账户A余额1500-1000=500;第2步账户B余额2000+1000=3000;原子性:这两步要么全做,要么全部做;不能账户A余额减少1000而账户B的余额没有相应的增加1000,保证这2个操作是一个原子操作。一致性:事务(转账)开始时账户A的余额1500,账户B余额2000,一共3500;事务(转账)结束时账户A余额500,账户B余额3000,一共3500;从一个一致性状态来到另一个一致性状态并且保证账户余额不为负数(可见一致性与原子性密切相关)。隔离性:在转账的构成中,事务没有提交(转账没有结束),查询账户A、B的余额均不会变化;如果此时账户C给账户B转账500,那么当两个事务(转账)都结束的时候,B账户余额应该是A转给B的1000加上C转给B的500再加开始的余额2000。持久性:一旦转账成功(事务提交),两个账户的里面的余额就会真的发生变化(会把数据写入数据库做持久化保存)。
在DBMS中,保证了一个操作的序列全部执行或全部不执行(原子性),从一个一致性状态变到另一个一致性状态(一致性),操作一旦提交就持久化到数据库中(持久性),当多个事务同时操作同一个数据之间互不干扰(隔离性);当多个事务并发操作事,如果控制不好隔离级别,就有可能产生脏读、不可重复读或者幻读问题。
隔离级别
隔离级别要比想象的要复杂,四种隔离级别,每一种隔离级别规定了一个事务中所做的修改,哪些在事务内和事务间是可见的,哪些是不可见的。较低级别的隔离可以执行更高并发,系统开销也更低。
不同的RDMS厂商的默认隔离级别不一样,Oracle、Sql Server为已提交读(Read committed),MySQL为可重复读(Repeatable read)。
| 隔离级别 | 脏读(Dirty Read)可能性 | 不可重复读(NonRepeatable Read)可能性 | 幻读(Phantom Read)可能性 |
|---|---|---|---|
| 未提交读(Read uncommitted) | 可能 | 可能 | 可能 |
| 已提交读(Read committed) | 不可能 | 可能 | 可能 |
| 可重复读(Repeatable read) | 不可能 | 不可能 | 可能 |
| 可串行化(Serializable) | 不可能 | 不可能 | 不可能 |
脏读:事务T1读取了另一个事务T2未提交的insert、update、delete的数据,因为事务T2没有提交事务T1读取到的数据为脏数据,称为脏读。
不可重复读:事务T1多次读取同一数据期间,另一个事务T2对此数据进行update、delete操作;T1多次读取的数据不一致,称为不可重复读。
幻读:一个事务T1通过检索条件,读取N条数据,另一个事务T2写入了1条满足T1检索条件的数据,后续T1对检索的数据进行修改时,发现影响的数据记录数N+1,称为幻读。
未提交读(Read uncommitted)
-- 创建表tx
create table tx (id int auto_increment,name varchar(10),primary key(id)) engine=innodb;
-- 查看全局事务隔离级别
select @@global.tx_isolation;
-- 查看会话事务隔离级别
select @@session.tx_isolation;
-- 设置会话事务隔离级别
set session transaction isolation level read uncommitted
set session transaction isolation level read committed
set session transaction isolation level repeatable read
set session transaction isolation level serializable
| session1 | session2 | |
|---|---|---|
| 查看事务隔离级别 | select @@session.tx_isolation; 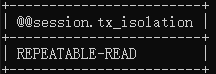 |
select @@session.tx_isolation; |
| 会话2设置隔离级别 | set session transaction isolation level read uncommitted; | |
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; 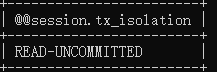 |
| 开启事务 | begin; | begin; |
| 查看数据 | select * from tx;  |
select * from tx;  |
| 会话1写入数据 | insert into tx (name) values ('a');  |
|
| 查看数据 | select * from tx; 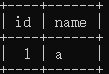 |
select * from tx;  |
| 会话1事务回滚 | rollback; | |
| 会话2查看数据 | select * from tx; |
|
| 会话2事务提交 | commit; |
将会话2的事务隔离级别设置为未提交读,会话2中的事务能够读取会话1事务中未提交的数据,产生脏读;
未提交读最低的隔离级别,允许读取并发事务尚未提交的数据,会出现脏读、不可重复读、幻读
已提交读(Read committed)
-- 写入数据
insert into tx (name) values ('a');
| session1 | session2 | |
|---|---|---|
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; |
| 会话2设置隔离级别 | set session transaction isolation level read committed; | |
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; 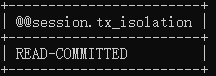 |
| 开启事务 | begin; | begin; |
| 查看数据 | select * from tx where id=2;  |
select * from tx where id=2; |
| 会话1更新数据 | update tx set name='b' where id=2;  |
|
| 查看数据 | select * from tx where id=2;  |
select * from tx where id=2; |
| 会话1事务提交 | commit; | |
| 会话2查看数据 | select * from tx where id=2; |
|
| 会话2事务提交 | commit; |
将会话2的事务隔离级别设置为已提交读:会话2事务未能读取会话1事务未提交的数据,解决了脏读问题;当会话1事务提交后,会话1再次读取数据,读取到会话1事务修改的数据,产生了不可重复读的问题
已提交读允许读取并发事务尚已提交的数据,解决脏读问题,仍会出现不可重复读、幻读。
可重复读(Repeatable read)
-- 写入数据
insert into tx (name) values ('aa');
| session1 | session2 | |
|---|---|---|
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; |
| 会话2设置隔离级别 | set session transaction isolation level repeatable read; | |
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; 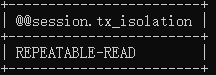 |
| 开启事务 | begin; | begin; |
| 查看数据 | select * from tx where id >1; 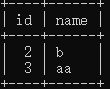 |
select * from tx where id >1; |
| 会话1更新数据 | update tx set name='c' where id=2; |
|
| 查看数据 | select * from tx where id >1; 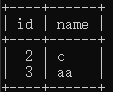 |
select * from tx where id >1; |
| 会话1事务写入数据 | insert into tx (name) values ('aaa');  |
|
| 查看数据 | select * from tx where id >1; 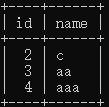 |
select * from tx where id >1; |
| 会话1事务提交 | commit; | |
| 会话2查看数据 | select * from tx where id>1; 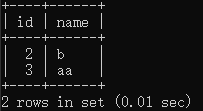 |
|
| 会话2查看数据 | select * from tx where id>2; 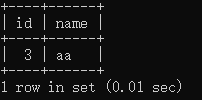 |
|
| 会话2更新数据 | update tx set name='bb' where id>3;  |
|
| 会话2事务提交 | commit; | |
| 查看数据 | select * from tx where id >1; 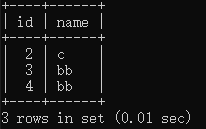 |
select * from tx where id >1; |
将会话2的事务隔离级别设置为可重复读:会话2事务未能读取到会话1事务修改的id=2的数据,当会话1事务提交后,会话2事务再次读取仍未读取到会话1事务修改id=2的数据,解决了不可重复读的问题;但会话1事务读取id>2的数据为1条,更新id>2的数据Rows matched: 2 Changed: 2,影响2条数据产生幻读问题,可通过锁机制Next-Key Lock解决。
| session1 | session2 | |
|---|---|---|
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; |
| 查看数据 | select * from tx where id=2; 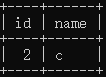 |
select * from tx where id=2; |
| 开启事务 | begin; | begin; |
| 查看数据 | select * from tx where id=2; |
|
| 会话1更新数据 | update tx set name='d' where id=2; |
|
| 查看数据 | select * from tx where id=2; 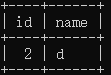 |
|
| 会话1事务提交 | commit; | |
| 会话2查看数据 | select * from tx where id=2; |
|
| 会话2事务提交 | commit; |
注意这个场景:会话2事务隔离级别依然是可重复读,会话2事务读取到会话1事务提交的数据,是不是很困惑?
可重复读解决的是不可重复读问题,此场景没有产生不可重复读问题(第一次select);属于一致性非锁定读/快照读,通过MVCC机制实现。
- MySQL的读有一致性非锁定度/一致性锁定读
- 一致性非锁定度(俗称快照读),普通的SELECT,通过多版本并发控制(MVCC)实现。
- 一致性锁定读(俗称当前读),SELECT...FOR UPDATE/SELECT...LOCK IN SHARE MODE。
可串行化(Serializable)
此隔离级别很简单,读操作加共享锁,写操作加排他锁,读写互斥。使用悲观锁的理论,实现简单,避免了脏读、不可重复读、幻读,并发能力降低。
| session1 | session2 | |
|---|---|---|
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; |
| 会话2设置隔离级别 | set session transaction isolation level serializable; | |
| 查看事务隔离级别 | select @@session.tx_isolation; |
select @@session.tx_isolation; 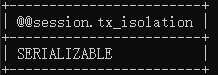 |
| 会话2开启事务 | begin; | |
| 会话2查看数据 | select * from tx where id=2; |
|
| 会话1查看数据 | select * from tx where id=2; |
|
| 会话1查看数据 | select * from tx where id=2 lock in share mode; |
|
| 会话1查看数据 | select * from tx where id=2 for update;  |
|
| 会话2修改数据 | update tx set name='e' where id=2; |
|
| 会话1查看数据 | select * from tx where id=2; |
|
| 会话1查看数据 | select * from tx where id=2 lock in share mode;  |
上面通过命令行演示了MySQL中不同的事务隔离级别,以及不同的事务隔离级别解决的问题;在实际工作中需根据业务场景设置相应的事务隔离级别。
MySQL——事务ACID&隔离级别的更多相关文章
- MySQL事务及隔离级别详解
MySQL事务及隔离级别详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MySQL的基本架构 MySQL的基本架构可以分为三块,即连接池,核心功能层,存储引擎层. 1> ...
- MySQL事务学习-->隔离级别
MySQL事务学习-->隔离级别 6 事务的隔离级别 设置的目的 在数据库操作中,为了有效保证并发读取数据的正确性,提出的事务隔离级别. 数据库是要被广大客户所共享访问的,那么在数据库操作过程中 ...
- MySql事务的隔离级别及作用
逻辑工作单元遵循一系列(ACID)规则则称为事务. 原子性:保证事务是一系列的运作,如果中间过程有一个不成功则全部回滚,全部成功则成功.保证了事务的原则性. 一致性:一致性指的是比如A向B转100块钱 ...
- MySQL事务及隔离级别(读书小结)
标签: MySQL事务 隔离 0.什么是事务? 事务是指MySQL的一些操作看做是一个不可分割的执行单元.事务的特点是要么所有操作都执行成功,要么一个都不执行.也就是如果一个事务有操作执行失败,那么就 ...
- mysql 事务、隔离级别
一.事务的四大特性(ACID) 1.原子性(Atomicity):事务开始后所有操作,要么全部做完,要么全部不做,不可能停滞在中间环节.事务执行过程中出错,会回滚到事务开始前的状态,所有的操作就像没有 ...
- 数据库事务ACID/隔离级别
参考博客 1. 事务的定义 事务是用户定义的一个数据库操作序列.这些操作要么全执行,要么全不执行,是一个不可分割的工作单元.在关系型数据库中,事务可以是一条SQL语句,也可以是一组SQL语句或整个程序 ...
- mysql事务、隔离级别
一.事务简介 事务是一组操作的集合,它是一一个不可分割的工作单位,事务会把所有的操作作为- -个整体一起向系统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败. 二.有关事务操作 mysql中 ...
- MySql事务及隔离级别
在数据库中,所谓事务是指作为单个逻辑工作单元执行的一系列操作. 事务的操作: 先定义开始一个事务,然后对数据作修改操作, 这时如果提交(COMMIT),这些修改就永久地保存下来 如果回退(ROLLBA ...
- [转]MySQL事务学习-->隔离级别
From : http://blog.csdn.net/mchdba/article/details/12837427 6 事务的隔离级别 设置的目的 在数据库操作中,为了有效保证并发读取数据的正确性 ...
随机推荐
- Mybatis之plugin插件设计原理
大多数框架,都支持插件,用户可通过编写插件来自行扩展功能,Mybatis也不例外. 我们从插件配置.插件编写.插件运行原理.插件注册与执行拦截的时机.初始化插件.分页插件的原理等六个方面展开阐述. 一 ...
- 构建者模式(Builder pattern)
构建者模式应用场景: 主要用来构建一些复杂对象,这里的复杂对象比如说:在建造大楼时,需要先打牢地基,搭建框架,然后自下向上地一层一层盖起来.通常,在建造这种复杂结构的物体时,很难一气呵成.我们需要首先 ...
- leetcode75:search-a-2d-matrix
题目描述 请写出一个高效的在m*n矩阵中判断目标值是否存在的算法,矩阵具有如下特征: 每一行的数字都从左到右排序 每一行的第一个数字都比上一行最后一个数字大 例如: 对于下面的矩阵: [ [1, 3, ...
- .NET5都来了,你还不知道怎么部署到linux?最全部署方案,总有一款适合你
随着2020进入4季度,.NET5正式版也已经与大家见面了.不过,尽管 .NET Core发布已经有四五年的时间,但到目前为止,依旧有很多.NET开发者在坚守者.NET4,原因不尽相同,但最大的问题可 ...
- c# 自动更新程序
首先看获取和更新的接口 更新程序Program.cs 1 using System; 2 using System.Collections.Generic; 3 using System.Diagno ...
- (1)ElasticSearch搭配Kibana在linux环境的部署
1.简介 这个章节主要介绍ElasticSearch+Kibana两个组件在linux环境的部署步骤,以及在部署过程中遇到问题解决,暂就不涉及集群部署知识点,后面章节再详细讲解这块.下面让我们来简单了 ...
- Netlink 内核实现分析 4
netlink 库函数: http://www.infradead.org/~tgr/libnl/doc/core.html#core_netlink_fundamentals #define NET ...
- kafka数据一致性(HW只能保证副本之间的数据一致性,并不能保证数据不丢失ack或者不重复。)
数据一致性问题:消费一致性和存储一致性 例如:一个leader 写入 10条数据,2个follower(都在ISR中),F1.F2都有可能被选为Leader,例如选F2 .后面Leader又活了.可能 ...
- CSP-S 2020 Travels
CSP-S 2020 Travels DAY 0 I hit the board in the morning before departure The rest of the time is dec ...
- Vue 组件化开发之插槽
插槽的作用 相信看过前一篇组件化开发后,你对组件化开发有了新的认识. 插槽是干什么的呢?它其实是配合组件一起使用的,让一个组件能够更加的灵活多变,如下图所示,你可以将组件当作一块电脑主板,将插槽当作主 ...