JDK 8 新增的 LongAdder,得过来看一下
前言
在介绍 AtomicInteger 时,已经说明在高并发下大量线程去竞争更新同一个原子变量时,因为只有一个线程能够更新成功,其他的线程在竞争失败后,只能一直循环,不断的进行 CAS 尝试,从而浪费了 CPU 资源。而在 JDK 8 中新增了 LongAdder 用来解决高并发下变量的原子操作。下面同样通过阅读源码来了解 LongAdder 。
公众号:liuzhihangs,记录工作学习中的技术、开发及源码笔记;时不时分享一些生活中的见闻感悟。欢迎大佬来指导!
介绍
一个或多个变量共同维持初值为 0 总和。 当跨线程竞争更新时,变量集可以动态增长以减少竞争。 方法 sum 返回当前变量集的总和。
当多个线程更新时,这个类是通常优选 AtomicLong ,比如用于收集统计信息,不用于细粒度同步控制的共同总和。 在低更新竞争,这两个类具有相似的特征。 但在高更新竞争时,使用 LongAdder 性能要高于 AtomicLong,同样要消耗更高的空间为代价。
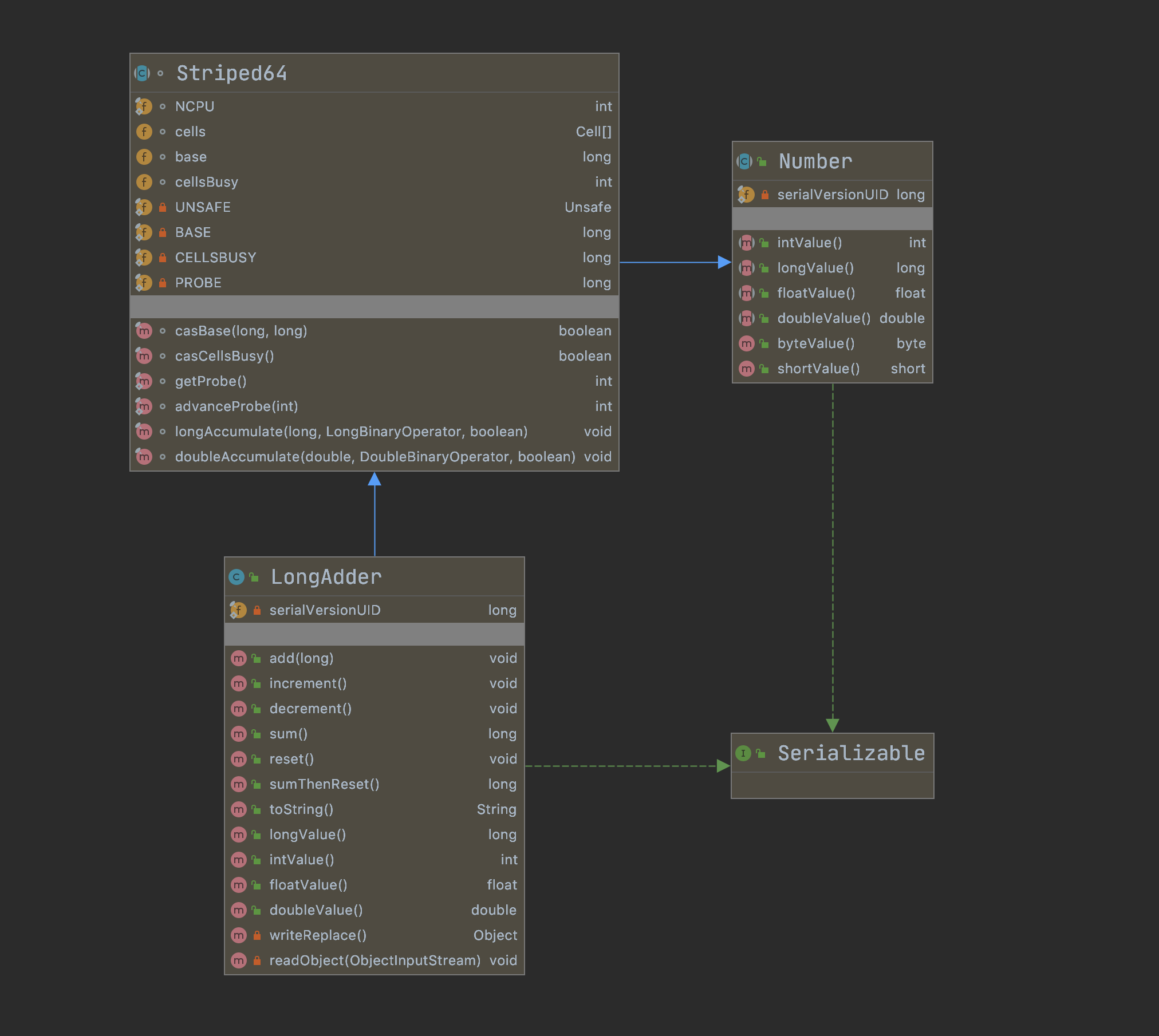
LongAdder 继承了 Striped64,内部维护一个 Cells 数组,相当于多个 Cell 变量, 每个 Cell 里面都有一个初始值为 0 的 long 型变量。
源码分析
Cell 类
Cell 类 是 Striped64 的静态内部类。
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset
(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
- Cell 使用 @sun.misc.Contended 注解。
- 内部维护一个被 volatile 修饰的 long 型 value 。
- 提供 cas 方法,更新value。
其中 @sun.misc.Contended 注解作用是为了减少缓存争用。什么是缓存争用,这里只做下简要介绍。
伪共享
CPU 存在多级缓存,其中最小存储单元是 Cache Line,每个 Cache Line 能存储 64 个字节的数据。
在多线程场景下,A B 两个线程数据如果被存储到同一个 Cache Line 上,此时 A B 更新各自的数据,就会发生缓存争用,导致多个线程之间相互牵制,变成了串行程序,降低了并发。
@sun.misc.Contended 注解,则可以保证该变量独占一个 Cache Line。
详细可参考:http://openjdk.java.net/jeps/142
Striped64 核心属性
abstract class Striped64 extends Number {
/** CPU 的数量,以限制表大小 */
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* cell 数组,当非空时,大小是 2 的幂。
*/
transient volatile Cell[] cells;
/**
* Base 值,在无争用时使用,表初始化竞赛期间的后备。使用 CAS 更新
*/
transient volatile long base;
/**
* 调整大小和创建Cells时自旋锁(通过CAS锁定)使用。
*/
transient volatile int cellsBusy;
}
Striped64 类主要提供以下几个属性:
- NCPU:CPU 的数量,以限制表大小。
- cells:Cell[] cell 数组,当非空时,大小是 2 的幂。
- base:long 型,Base 值,在无争用时使用,表初始化竞赛期间的后备。使用 CAS 更新。
- cellsBusy:调整大小和创建Cells时自旋锁(通过CAS锁定)使用。
下面看是进入核心逻辑:

LongAdder#add
public class LongAdder extends Striped64 implements Serializable {
public void add(long x) {
Cell[] as; long b, v; int m; Cell a;
// cells 是 数组,base 是基础值
if ((as = cells) != null || !casBase(b = base, b + x)) {
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
}
}
}
abstract class Striped64 extends Number {
// 使用 CAS 更新 BASE 的值
final boolean casBase(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, BASE, cmp, val);
}
// 返回当前线程的探测值。 由于包装限制,从ThreadLocalRandom复制
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
}
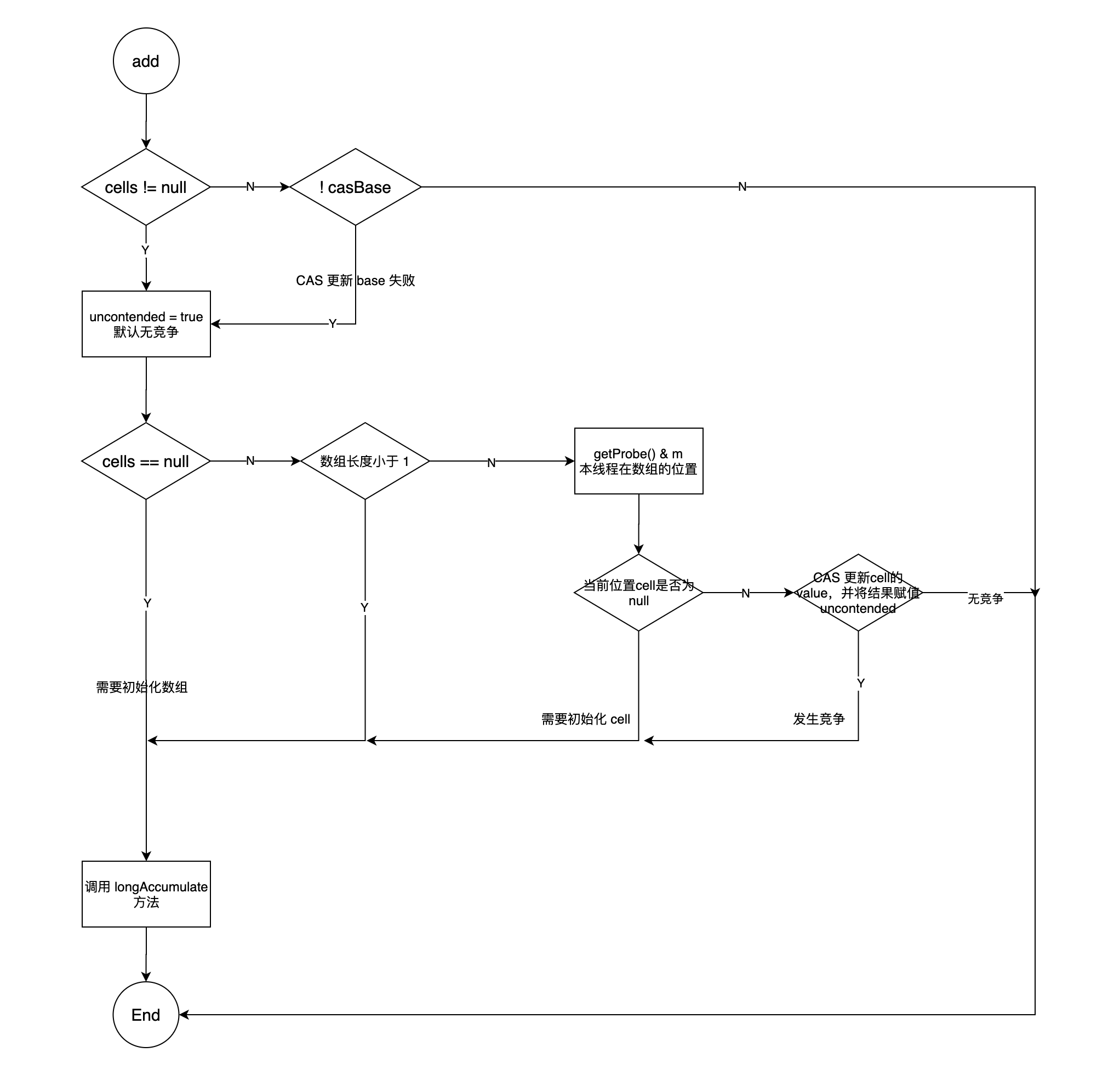
- 首先会对 Base 值进行 CAS 更新,当 Base 发生竞争时, 会更新数组内的 Cell 。
- 数组未初始化,Cell 未初始化, Cell 更新失败,即 Cell 也发生竞争时,会调用 Striped64 的 longAccumulate 方法。
Striped64#longAccumulate
abstract class Striped64 extends Number {
/**
* x 要增加的值
* wasUncontended 有没有发生竞争
*/
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
// 当前线程有无初始化线程探测值, 给当前线程生成一个 非 0 探测值
if ((h = getProbe()) == 0) {
ThreadLocalRandom.current(); // force initialization
h = getProbe();
wasUncontended = true;
}
boolean collide = false; // True if last slot nonempty
// 循环
for (;;) {
Cell[] as; Cell a; int n; long v;
// 数组不为空切数组长度大于 0
if ((as = cells) != null && (n = as.length) > 0) {
// (n - 1) & h 获取到索引,索引处 cell 是否为 null, cell未初始化
if ((a = as[(n - 1) & h]) == null) {
// 判断 cellsBusy 是否为 0
if (cellsBusy == 0) { // Try to attach new Cell
Cell r = new Cell(x); // Optimistically create
// cellsBusy == 0 且 使用 casCellsBusy 方法将其更新为 1,失败会继续循环
if (cellsBusy == 0 && casCellsBusy()) {
boolean created = false;
try { // Recheck under lock
Cell[] rs; int m, j;
// 重新检查状态 并创建
if ((rs = cells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
// 创建完成之后, 改回 cellsBusy 值
cellsBusy = 0;
}
if (created)
break;
// 未创建继续循环
continue; // Slot is now non-empty
}
}
collide = false;
}
// 传入的 wasUncontended 为 false 即发生碰撞了, 修改为未碰撞, 此处会继续循环,走到下一步,相当于会一直循环这个 cell
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
// cas 更新 cell 的 value, 成功则返回
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// 数组到最大长度 即大于等于 CPU 数量, 或者 cells 数组被改变,
else if (n >= NCPU || cells != as)
collide = false; // At max size or stale
else if (!collide)
collide = true;
// 乐观锁 进行扩容
else if (cellsBusy == 0 && casCellsBusy()) {
try {
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
// 当前探针值不能操作成功,则重新设置一个进行尝试
h = advanceProbe(h);
}
// 没有加 cellsBusy 乐观锁 且 没有初始化,且获得锁成功(此时 cellsBusy == 1)
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
// 尝试在base上累加
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
}
longAccumulate 方法一共有三种情况
(as = cells) != null && (n = as.length) > 0数组不为空且长度大于 0 。- 获取索引处的 cell , cell 为空则进行初始化。
- cell 不为空,使用 cas 更新, 成功
break;跳出循环, 失败则还在循环内,会一直尝试。 - collide 指是否发生冲突,冲突后会进行重试。
- 冲突后会尝试获得锁并进行扩容,扩容长度为原来的 2 倍,然后继续重试。
- 获得锁失败(说明其他线程在扩容)会重新进行计算探针值。
cellsBusy == 0 && cells == as && casCellsBusy()数组为空,获得乐观锁成功。- 直接初始化数组。
- 初始数组长度为 2 。
casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x)))获得乐观锁失败。- 说明有其他线程在初始化数组,直接 CAS 更新 base 。
LongAdder#sum
public class LongAdder extends Striped64 implements Serializable {
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
}
- 数组为空,说明没有发生竞争,直接返回 base 。
- 数组不为空,说明发生竞争,累加 cell 的 value 和 base 的和进行返回。
总结
基本流程
- LongAdder 继承了 Striped64,内部维护一个 Cells 数组,相当于多个 Cell 变量, 每个 Cell 里面都有一个初始值为 0 的 long 型变量。
- 未发生竞争时(Cells 数组未初始化),是对 base 变量进行原子操作。
- 发生竞争时,每个线程对自己的 Cell 变量的 value 进行原子操作。
如何确定哪个线程操作哪个 cell?
通过 getProbe() 方法获取该线程的探测值,然后和数组长度 n - 1 做 & 操作 (n - 1) & h 。
static final int getProbe() {
return UNSAFE.getInt(Thread.currentThread(), PROBE);
}
Cells 数组初始化及扩容?
初始化扩容时会判断 cellsBusy, cellsBusy 使用 volatile 修饰,保证线程见可见性,同时使用 CAS 进行更新。 0 表示空闲,1 表示正在初始化或扩容。
初始化时会创建长度为 2 的 Cell 数组。扩容是创建一个长度是原数组长度 2 倍的新数组,并循环赋值。
如果线程访问分配的 Cell 元素有冲突后,会使用 advanceProbe() 方法重新获取探测值,再次进行尝试。
使用场景
在高并发情况下,需要相对高的性能,同时数据准确性要求不高,可以考虑使用 LongAdder。
当要保证线程安全,并允许一定的性能损耗时,并对数据准确性要求较高,优先使用 AtomicLong。
JDK 8 新增的 LongAdder,得过来看一下的更多相关文章
- JDK 7中的文件操作的新特性
文件系统综述 一个文件系统在某种媒介(通常是一个或多个硬盘)上存储和组织文件.如今的大多数文件系统都是以树状结构来存储文件.在树的顶端是一个或多个根节点,在根节点一下,是文件和目录(在Windows系 ...
- Java JDK 版本的区别
jdk6和jdk5相比的新特性有: 1.instrumentation 在 Java SE 6 里面,instrumentation 包被赋予了更强大的功能:启动后的 instrument.本地代码 ...
- JDK 9 & JDK 10 新特性
JDK 9 新增了不少特性,官方文档:https://docs.oracle.com/javase/9/whatsnew/toc.htm#JSNEW-GUID-527735CF-44E1-4144-9 ...
- JDK 8 - Lambda Expression 的优点与限制
我们知道 JDK 8 新增了 Lambda Expression 这一特性. JDK 8 为什么要新增这个特性呢? 这个特性给 JDK 8 带来了什么好处? 它可以做什么?不可以做什么? 在这篇文章, ...
- JDK 8 - JVM 对类的初始化探讨
在<深入理解 Java 虚拟机>(第二版,周志明著)中,作者介绍了 JVM 必须初始化类(或接口)的五种情况,但是是针对 JDK 7 而言的. 那么,在 JDK 8 中,这几种情况有没有变 ...
- Java程序员必备基础:JDK 5-15都有哪些经典新特性
前言 JDK 15发布啦~ 我们一起回顾JDK 5-15 的新特性吧,大家一起学习哈~ 本文已经收录到github ❝ https://github.com/whx123/JavaHome ❞ 「公众 ...
- 译文《全新首发JDK 16全部新特性》
封面:洛小汐 译者:潘潘 JDK 8 的新特性都还没摸透,JDK 16 的新特性就提着刀来了. 郑重申明: 第一次冒险翻译专业领域的文献,可想而知,效果特别糟糕.一般翻译文献特别是 技术专业领域 的内 ...
- 【原创】JDK 9-17新功能30分钟详解-语法篇-var
JDK 9-17新功能30分钟详解-语法篇-var 介绍 JDK 10 JDK 10新增了新的关键字--var,官方文档说作用是: Enhance the Java Language to exten ...
- 从 Linux 内核角度探秘 JDK NIO 文件读写本质
1. 前言 笔者在 <从 Linux 内核角度看 IO 模型的演变>一文中曾对 Socket 文件在内核中的相关数据结构为大家做了详尽的阐述. 又在此基础之上介绍了针对 socket 文件 ...
随机推荐
- STM32CubeMX HAL库串口: 使用DMA数据发送、使用DMA不定长度数据接收
转载自 https://blog.csdn.net/euxnijuoh/article/details/81638676
- Centos6.6x系统与unbutu18.04系统升级ssh到8.3版本
Centos6.6升级ssh5.3版本到ssh8.3版本 下载所需要的源码包: ]#wget https://files-cdn.cnblogs.com/files/luckjinyan/zlib-1 ...
- 联赛模拟测试8 Dash Speed 线段树分治
题目描述 分析 对于测试点\(1\).\(2\),直接搜索即可 对于测试点\(3 \sim 6\),树退化成一条链,我们可以将其看成序列上的染色问题,用线段树维护颜色相同的最长序列 对于测试点\(7\ ...
- milvus和faiss安装及其使用教程
写在前面 高性能向量检索库(milvus & faiss)简介 Milvus和Faiss都是高性能向量检索库,可以让你在海量向量库中快速检索到和目标向量最相似的若干个向量,这里相似度量标准可以 ...
- I2C总线的Arduino库函数
I2C总线的Arduino库函数 I2C即Inter-Integrated Circuit串行总线的缩写,是PHILIPS公司推出的芯片间串行传输总线.它以1根串行数据线(SDA)和1根串行时钟线(S ...
- Navicat连接MySQL报错-2059
解释原因:据说,mysql8 之前的版本中加密规则是mysql_native_password,而在mysql8之后,加密规则是caching_sha2_password, 解决问题方法有两种,一种是 ...
- 一道算法题,引出collections.Counter的特殊用法
题目描述: 题目编号:1002. 查找常用字符 给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表.例如,如果一个字符在每个字符串中出现 3 次, ...
- 对json数组按照id精确查询并修改值
//json数组,里面有一个id等于5的,班级的标识和名称不是该班级,通过id把班级信息修改为指定的信息 var zNodes=[ { id:1, classid:1, className:" ...
- 微信小程序 - 重置checkbox样式
/* 未选中的 背景样式 */ checkbox .wx-checkbox-input { border-radius: 50%;/* 圆角 */ width: 30rpx; /* 背景的宽 */ h ...
- gin教程
Golang Gin 实战(十)| XML渲染 Golang Gin 实战(九)| JSONP跨域和劫持 Golang Gin 实战(八)| JSON渲染输出 Golang Gin 实战(七)| 分组 ...