day35:线程队列&进程池和线程池&回调函数&协程
目录
线程队列
1.线程队列的基本方法
put 存
get 取
put_nowait 存,超出了队列长度,报错
get_nowait 取,没数据的时候,直接报错
[linux windows] 线程中 put_nowait/get_nowait 都支持(区别于进程队列)
2.Queue:先进先出,后进后出
# (1) Queue
"""先进先出,后进后出"""
q = Queue()
q.put(1)
q.put(2)
print(q.get())
print(q.get()) print(q.get()) # 取不出来,阻塞 print(q.get_nowait()) # 没有数据时,报错 # 指定队列长度
q2 = Queue(3)
q2.put(100)
q2.put(101)
q2.put(102) q2.put(103) # 存放的数据超出了队列长度,阻塞
q2.put_nowait(104) # 存放的数据超出了队列长度,报错
3.LifoQueue:先进后出,后进先出
# (2)LifoQueue 先进后出,后进先出(栈的特点)
from queue import LifoQueue
lq = LifoQueue(3)
lq.put(11)
lq.put(22)
lq.put(33) lq.put_nowait(44) # error print(lq.get()) #
print(lq.get()) #
print(lq.get()) # print(lq.get()) # 阻塞
4.PriorityQueue:按照优先级顺序进行排序
# (3)PriorityQueue 按照优先级顺序进行排序(默认从小到大)
from queue import PriorityQueue
pq = PriorityQueue()
# 1.可以存放数字--->按照数字大小排序
pq.put(80)
pq.put(81)
pq.put(18) # 2.可以存放字符串 (按照ascii编码进行排序,依次返回)
pq.put("wangwen")
pq.put("wangzhihe")
pq.put("gelong") # 3.可以存放容器--->按照容器的元素排序,从第一个元素开始
pq.put( (18,"wangwen") )
pq.put( (18,"maohonglei") )
pq.put( (18,"wangawei") ) # 4.是否可以将不同类型的数据都放到一个队列中的呢? 不可以!
# error
"""
pq.put(1)
pq.put("abc")
""" print(pq.get())
print(pq.get())
print(pq.get())
进程池和线程池
1.ProcessPoolExecutor:进程池的基本使用
from concurrent.futures import ProcessPoolExecutor def func(i):
print("任务执行中 ... start" , os.getpid())
time.sleep(3)
print("任务执行结束 ... end " , i)
return i if __name__ == "__main__":
lst = []
# (1) 创建进程池对象
"""参数: 默认获取的是最大cpu逻辑核心数 8"""
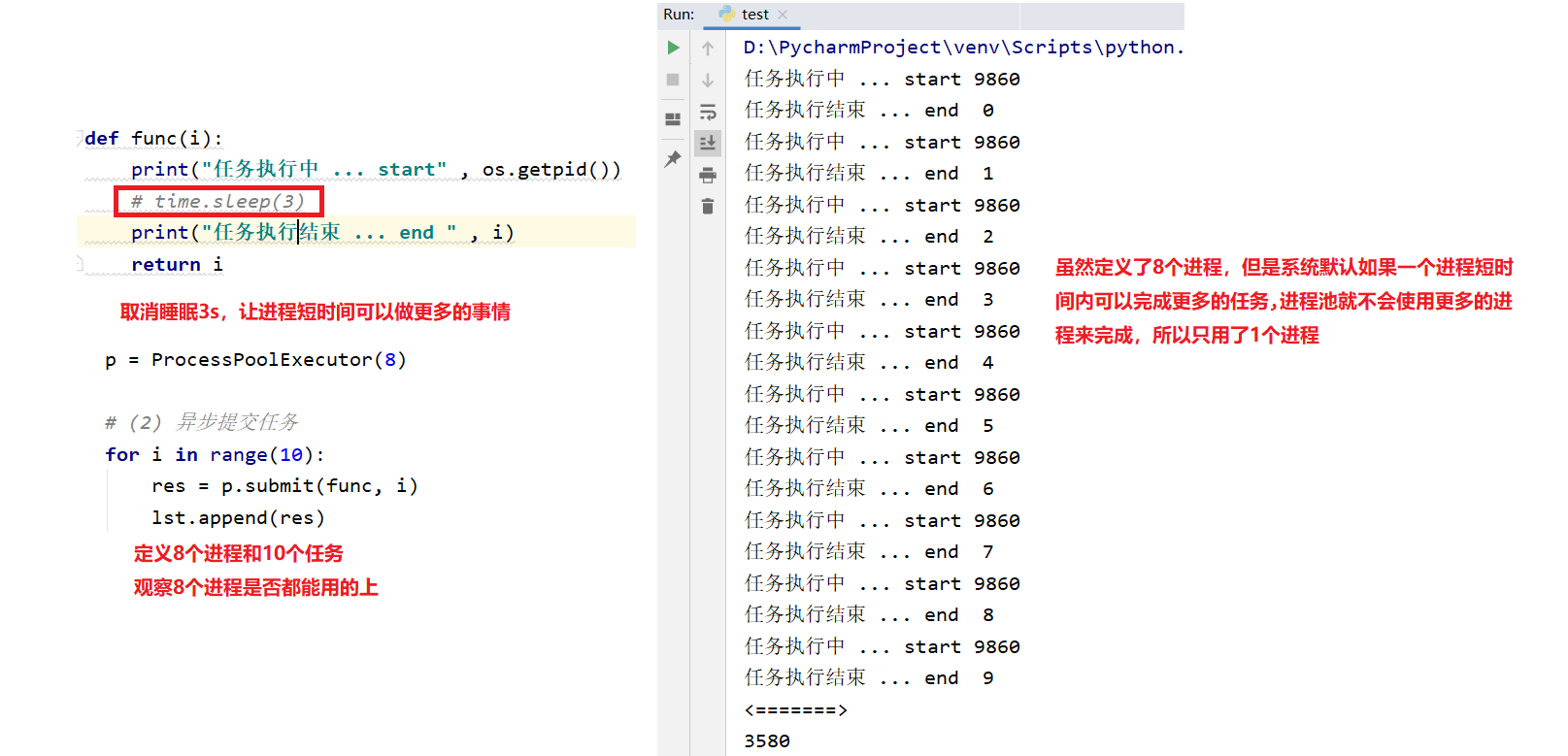
p = ProcessPoolExecutor(8) # (2) 异步提交任务
"""默认如果一个进程短时间内可以完成更多的任务,进程池就不会使用更多的进程来完成,以节省资源"""
for i in range(10):
res = p.submit(func, i)
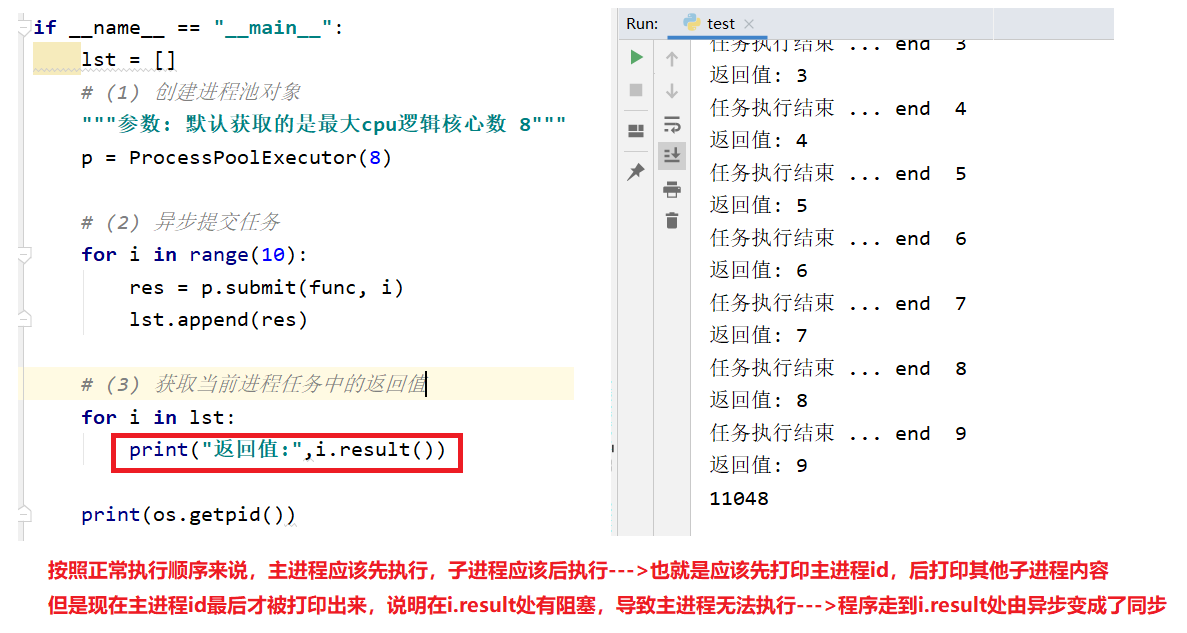
lst.append(res) # (3) 获取当前进程任务中的返回值(result在获取任务的返回值时,有阻塞)
for i in lst:
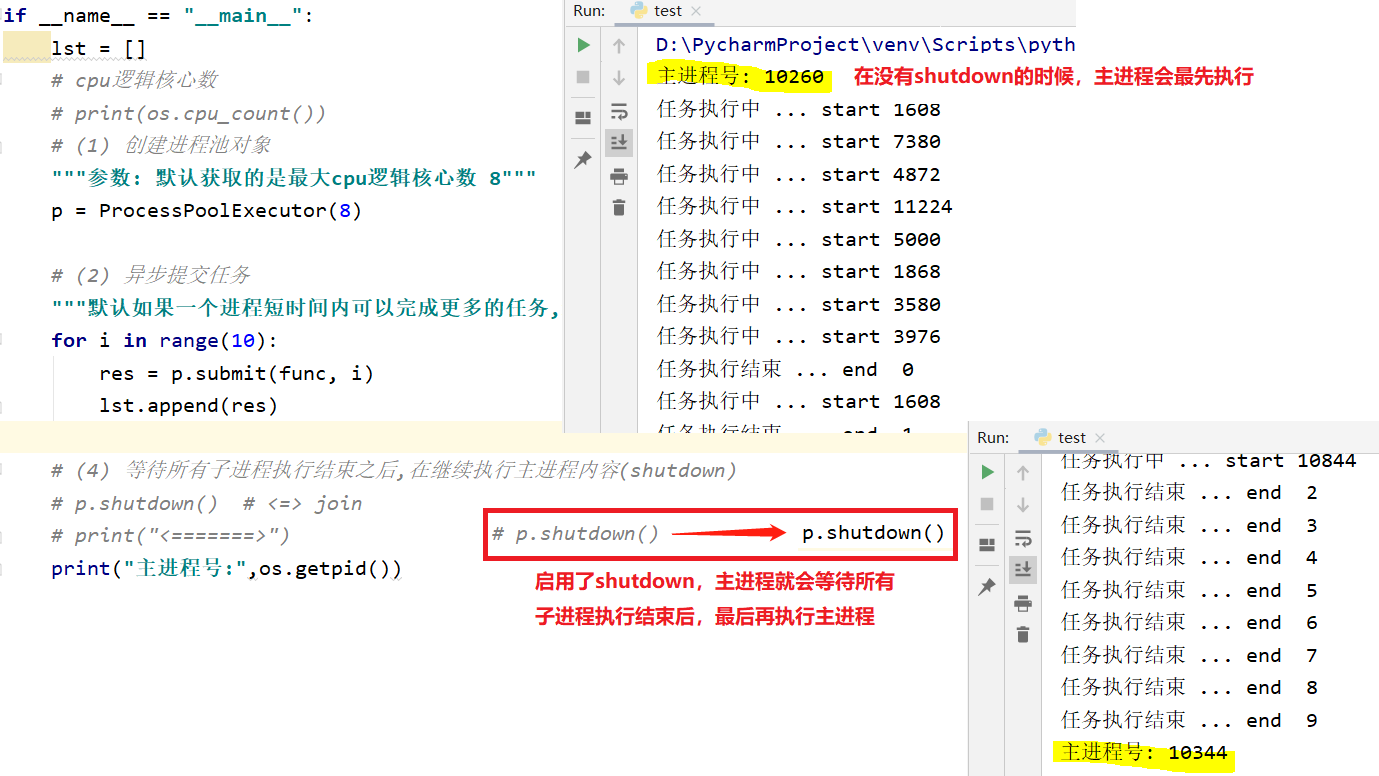
print(i.result()) # (4) 等待所有子进程执行结束之后,在继续执行主进程内容(shutdown)
p.shutdown() # <=> join
print("<=======>")
print(os.getpid())
1.创建进程池对象
2.异步提交任务
3.获取当前进程任务中的返回值
4.shutdown:等待所有子进程执行结束之后,在继续执行主进程内容
2.ThreadPoolExecutor:线程池的基本使用
from concurrent.futures import ThreadPoolExecutor from threading import current_thread as cthread def func(i):
print("thread ... start", cthread().ident)
print("thread ... end ", i)
return cthread().ident if __name__ == "__main__":
lst = []
setvar = set()
# (1) 创建线程池对象
"""参数: 默认并发的线程数 是 os.cpu_count() * 5 = 40"""
tp = ThreadPoolExecutor() # (2) 异步提交任务
"""默认如果一个线程短时间内可以完成更多的任务,线程池就不会使用更多的线程来完成,以节省资源"""
for i in range(100):
res = tp.submit(func, 10)
lst.append(res) # (3) 获取返回值
for i in lst:
setvar.add(i.result()) # (4) 等待所有子线程执行结束之后,在执行主线程
# tp.shutdown()
print("主线程执行结束 .... ")
print(setvar, len(setvar))
创建线程池时注意:
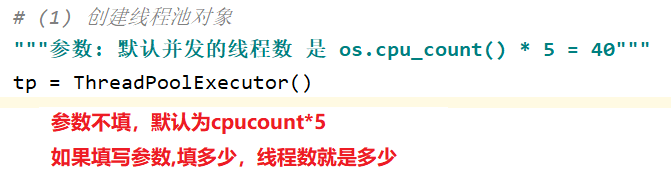
回调函数
1.进程池的回调函数: 由主进程执行调用完成的
def func1(i):
print("process start ... " , os.getpid())
time.sleep(1)
print("process end ... ", i)
return "*" * i def call_back1(obj):
print("<===回调函数callback进程号===>" , os.getpid())
print(obj.result()) if __name__ == "__main__":
p = ProcessPoolExecutor()
for i in range(1,11):
res = p.submit(func1,i)
# print(res.result())
res.add_done_callback(call_back1)
# self.func(func2)
p.shutdown()
print("主进程执行结束 ... " , os.getpid())
回调函数执行流程
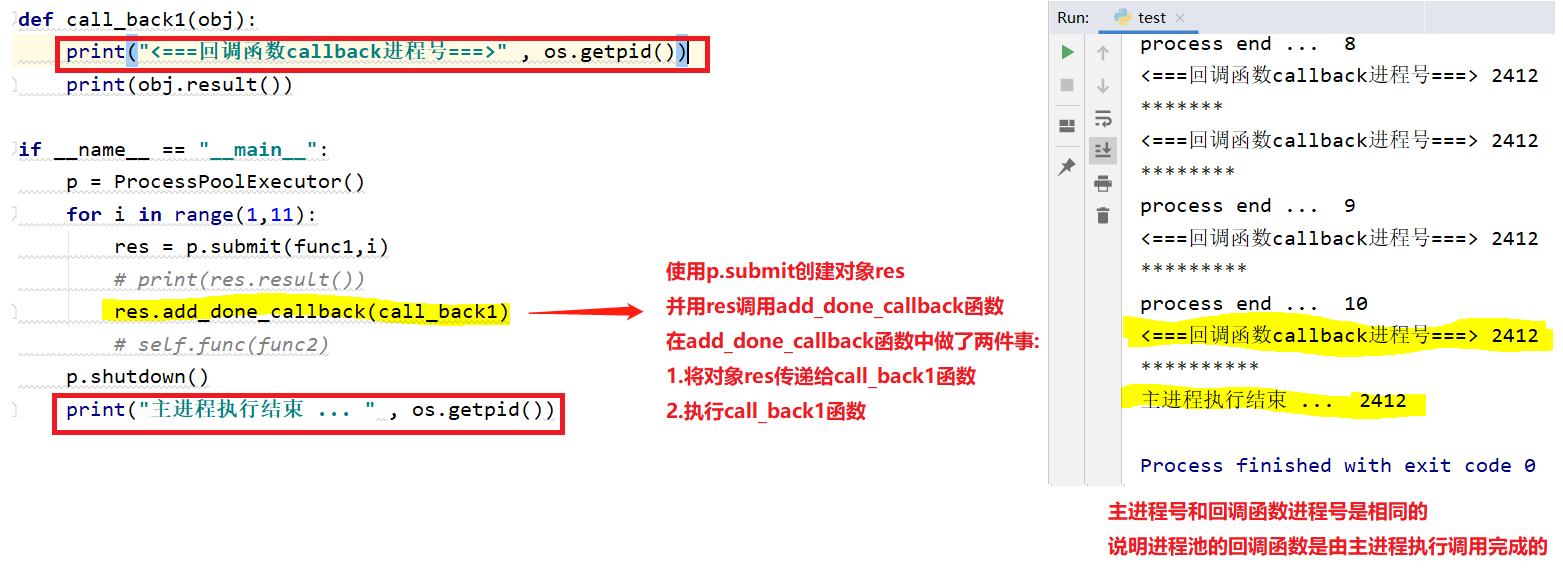
2.线程池的回调函数 : 由当前子线程调用完成的
def func2(i):
print("thread start ... " , cthread().ident)
time.sleep(1)
print("thread end ... ", i)
return "*" * i def call_back2(obj):
print("<===回调函数callback线程号===>" ,cthread().ident)
print(obj.result()) if __name__ == "__main__":
tp = ThreadPoolExecutor(5)
for i in range(1, 11):
res = tp.submit(func2, i)
res.add_done_callback(call_back2) tp.shutdown()
print("主线程执行结束 ... ", cthread().ident)
线程池回调函数的执行流程和进程池的几乎一致,在此不在赘述
唯一不同的是线程池的回调函数是由当前子线程调用完成的
协程:线程的具体实现
1.用协程改写生产者消费者模型
def prodecer():
for i in range(100):
yield i # 消费者
def consumer(gen):
for i in range(10):
print(next(gen)) # 初始化生成器函数 -> 生成器
gen = prodecer()
consumer(gen)
consumer(gen)
consumer(gen)
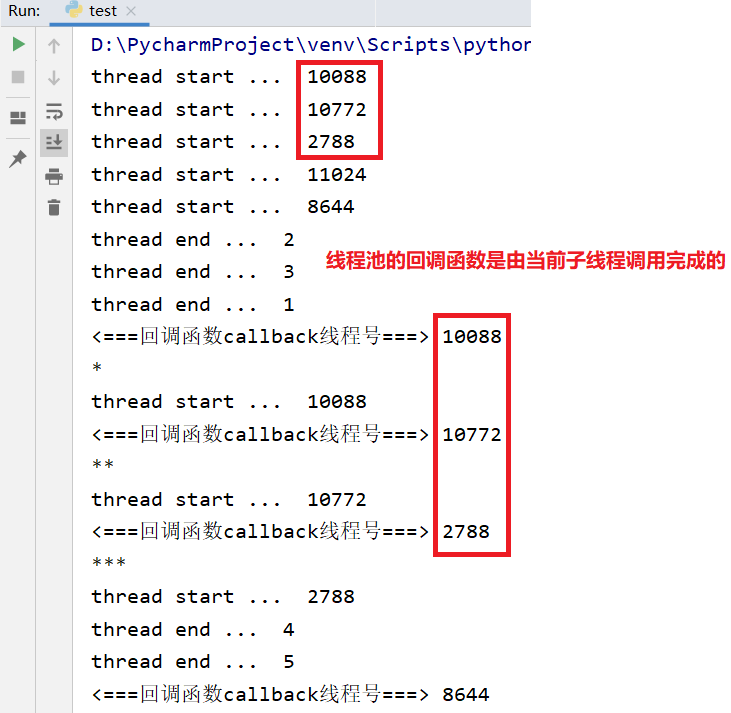
2.协程的历史:greenlet+switch
from greenlet import greenlet def eat():
print("eat 1")
g2.switch() # 手动切换到play
time.sleep(3)
print("eat 2") def play():
print("play 1")
time.sleep(3)
print("play 2")
g1.switch() # 手动切换到eat g1 = greenlet(eat) # 创建协程对象g1
g2 = greenlet(play) # 创建协程对象g2
g1.switch() # 手动切换到eat,执行程序
运行结果如下图所示
3.协程的历史:gevent可以实现切换,但是不能识别time.sleep阻塞
import gevent def eat():
print("eat 1")
# time.sleep(3) # gevent无法识别time.sleep阻塞,要使用自己的gevent.sleep
gevent.sleep(3)
print("eat 2") def play():
print("play 1")
# time.sleep(3) # gevent无法识别time.sleep阻塞,要使用自己的gevent.sleep
gevent.sleep(3)
print("play 2") # 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play) # 如果不加join阻塞,默认主线程执行时,不等待直接结束.
# 阻塞,必须等待g1协程任务执行完毕之后,放行
g1.join()
# 阻塞,必须等待g2协程任务执行完毕之后,放行
g2.join()
运行结果如下图所示

4.协程的历史:使用monkey彻底解决gevent模块不识别阻塞的问题
from gevent import monkey
monkey.patch_all() # 只要在monkey下面的导入,gevent都可以识别这些阻塞
import time
import gevent def eat():
print("eat 1")
time.sleep(3)
print("eat 2") def play():
print("play 1")
time.sleep(3)
print("play 2") # 利用gevent.spawn创建协程对象g1
g1 = gevent.spawn(eat)
# 利用gevent.spawn创建协程对象g2
g2 = gevent.spawn(play) # 如果不加join阻塞,默认主线程执行时,不等待直接结束.
# 阻塞,必须等待g1协程任务执行完毕之后,放行
g1.join()
# 阻塞,必须等待g2协程任务执行完毕之后,放行
g2.join() print("主线程执行结束 ... ")
执行结果如下图所示
5.协程相关方法
1.spawn(函数,参数1,参数2... ) 启动协程
2.join 阻塞,直到某个协程任务执行完毕之后,在执行下面代码
3.joinall 等待所有协程任务都执行完毕之后,放行
g1.join() g2.join() => gevent.joinall( [g1,g2] ) (推荐)
4.value 获取协程任务中的返回值 g1.value g2.value
from gevent import monkey monkey.patch_all()
import time
import gevent def eat():
print("eat 1")
time.sleep(3)
print("eat 2")
return "吃完了" def play():
print("play 1")
time.sleep(3)
print("play 2")
return "玩完了" g1 = gevent.spawn(eat)
g2 = gevent.spawn(play) # 等待g1,g2协程任务执行完毕之后,在放行
gevent.joinall([g1, g2]) print("主线程执行结束 .. ")
print(g1.value) # 吃完了
print(g2.value) # 玩完了
利用协程爬取数据
HTTP 状态码:
200 ok
404 not found
400 bad request
response基本用法
# 获取状态码
print(response.status_code) # 获取网站中的编码
res = response.apparent_encoding
print(res) # 设置编码集,防止乱码
response.encoding = res # 获取网页里面的数据
res = response.text
print(res)
1.用正常的方式去爬取数据
from gevent import monkey ; monkey.patch_all()
import requests
import time
import gevent url_lst = [
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/",
"http://www.baidu.com/",
"http://www.taobao.com/",
"http://www.jingdong.com/",
"http://www.4399.com/",
"http://www.7k7k.com/"
] def get_url(url):
response = requests.get(url)
if response.status_code == 200:
# print(response.text)
pass startime = time.time()
for i in url_lst:
get_url(i)
endtime = time.time()
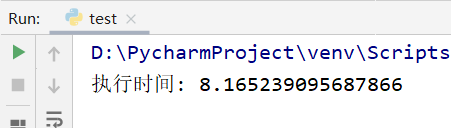
print("执行时间:",endtime - startime) #8.165239095687866
用正常的方式去爬取数据,需要8.16s
2.用协程的方式去爬取数据
lst = []
startime = time.time()
for i in url_lst:
g = gevent.spawn(get_url, i)
lst.append(g) gevent.joinall(lst)
endtime = time.time()
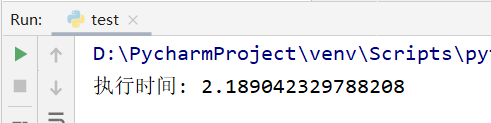
print("执行时间:", endtime - startime) # 2.189042329788208
用协程的方式去爬取数据,只需要2.18s
3.最终的理想状态
利用好多进程,多线程,多协程让服务器运行速度更快,抗住更大的并发
day35:线程队列&进程池和线程池&回调函数&协程的更多相关文章
- 什么是协程?与线程和进程对比优劣在哪?gevent协程示例代码
协程 协程,又称微线程,纤程.英文名Coroutine..一句话说明什么是线程:协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其他地方,在 ...
- Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就绪,挂起,运行) ,***协程概念,yield模拟并发(有缺陷),Greenlet模块(手动切换),Gevent(协程并发)
Python进阶----异步同步,阻塞非阻塞,线程池(进程池)的异步+回调机制实行并发, 线程队列(Queue, LifoQueue,PriorityQueue), 事件Event,线程的三个状态(就 ...
- python 管道 事件(Event) 信号量 进程池(map/同步/异步)回调函数
####################总结######################## 管道:是进程间通信的第二种方式,但是不推荐使用,因为管道会导致数据不安全的情况出现 事件:当我运行主进程的 ...
- 第三十四天- 线程队列、线程池(map/submit/shutdown/回调函数)
1.线程列队 queue队列 :使用import queue,用法与进程Queue一样 class queue.Queue(maxsize=0) # 先进先出: q = queue.Queue(3) ...
- (并发编程)进程池线程池--提交任务2种方式+(异步回调)、协程--yield关键字 greenlet ,gevent模块
一:进程池与线程池(同步,异步+回调函数)先造个池子,然后放任务为什么要用“池”:池子使用来限制并发的任务数目,限制我们的计算机在一个自己可承受的范围内去并发地执行任务池子内什么时候装进程:并发的任务 ...
- 进击的Python【第九章】:paramiko模块、线程与进程、各种线程锁、queue队列、生产者消费者模型
一.paramiko模块 他是什么东西? paramiko模块是用python语言写的一个模块,遵循SSH2协议,支持以加密和认证的方式,进行远程服务器的连接. 先来个实例: import param ...
- Python 开启线程的2中方式,线程VS进程(守护线程、互斥锁)
知识点一: 进程:资源单位 线程:才是CPU的执行单位 进程的运行: 开一个进程就意味着开一个内存空间,存数据用,产生的数据往里面丢 线程的运行: 代码的运行过程就相当于运行了一个线程 辅助理解:一座 ...
- (day31) Event+协程+进程/线程池
目录 昨日回顾 GIL全局解释器锁 计算密集型和IO密集型 死锁现象 递归锁 信号量 线程队列 FOFI队列 LIFO队列 优先级队列 今日内容 Event事件 线程池与进程池 异步提交和回调函数 协 ...
- concurrent.futures进线程池和协程
concurrent.futures 异步执行进程线程池的模块,一个抽象类,定义submit,map,shutdown方法 from concurrent.futures import Process ...
随机推荐
- 题解 UVA1608 【不无聊的序列 Non-boring sequences】
思路: 算法很显然: 一.在区间\([l,r]\)找到一个只出现一次的元素P(如果不存在,那么序列\(boring\)) 二.递归处理区间\([l,p-1]\)和区间\([p+1,r]\). 其关键在 ...
- sourceTree安装、跳过bitbucket注册免登陆方法
下载好以后,点击安装运行,会出现下面这个窗口 关掉这个窗口,打开C:\Users\{users}\AppData\Local\Atlassian\SourceTree(users是计算机的名字),新建 ...
- functools 中的 reduce 函数基本写法
reduce 返回的往往是一整个可迭代对象的 操作结果 reduce(函数,可迭代对象) 注:lambda x,y 两个参数 2020-05-04
- HTML中div嵌套div的margin不起作用
下面介绍一下div嵌套div时margin不起作用的解决方案. 顺便科普下margin的定义和用法. div嵌套的HTML代码: <!DOCTYPE html> <html lang ...
- PHP settype() 函数
settype() 函数用于设置变量的类型.高佣联盟 www.cgewang.com PHP 版本要求: PHP 4, PHP 5, PHP 7 语法 bool settype ( mixed &am ...
- 2020牛客暑期多校训练营 第二场 C Cover the Tree 构造 贪心
LINK:Cover the Tree 最受挫的是这道题,以为很简单 当时什么都想不清楚. 先胡了一个树的直径乱搞的贪心 一直过不去.后来意识到这类似于最经典长链剖分优化贪心的做法 然后那个是求最大值 ...
- luogu P3217 [HNOI2011]数矩形
LINK:数矩形 题意:给出n个点 求出一个最大的矩形. 矩形可以使斜着的.(不会告诉你样例我算了几年 这道题的一个潜规则 矩形面积都是整数 我也不知道为啥一定是整数 姑且是题目输出的要求吧. 所以用 ...
- OAuth2.0-1
分布式授权解决方案: 其中授权服务一般放在网关服务上,资源服务指的是,挂在网关下得各个微服务 网关授权客户端>客户端拿到token>客户端拿到token到网关验证,获取token明文> ...
- 016_go语言中的递归
代码演示 package main import "fmt" func fact(n int) int { if n == 0 { return 1 } return n * fa ...
- 使用selenium再次爬取疫情数据(链接数据库)
爬取网页地址: 丁香医生 数据库连接代码: def db_connect(): try: db=pymysql.connect('localhost','root','zzm666','payiqin ...