centos7搭建dolphinscheduler集群
一、简述
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。有如下特性:
高可靠性
去中心化的多Master和多Worker, 自身支持HA功能, 采用任务队列来避免过载,不会造成机器卡死
简单易用
DAG监控界面,所有流程定义都是可视化,通过拖拽任务定制DAG,通过API方式与第三方系统对接, 一键部署
丰富的使用场景
支持暂停恢复操作. 支持多租户,更好的应对大数据的使用场景. 支持更多的任务类型,如 spark, hive, mr, python, sub_process, shell
高扩展性
支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master和Worker支持动态上下线
二、搭建过程
1.环境配置
集群服务划分:
192.168.30.141 s141 (master)
192.168.30.142 s142 (master)
192.168.30.143 s143 (api)
192.168.30.144 s144 (worker)
192.168.30.145 s145 (worker)
192.168.30.146 s146 (worker)
192.168.30.147 s147 (worker)
1>安装软件
PostgreSQL (8.2.15+) or MySQL (5.7系列) : 两者任选其一即可, 如MySQL则需要JDBC Driver 5.1.47+
JDK (1.8+) : 必装,请安装好后在/etc/profile下配置 JAVA_HOME 及 PATH 变量
ZooKeeper (3.4.6+) :必装
Hadoop (2.6+) or MinIO :选装,如果需要用到资源上传功能,可以选择上传到Hadoop or MinIO上
注意:DolphinScheduler本身不依赖Hadoop、Hive、Spark,仅是会调用他们的Client,用于对应任务的提交。
2>创建部署用户
# 创建用户需使用root登录,设置部署用户名,请自行修改,后面以dolphinscheduler为例
useradd dolphinscheduler; # 设置用户密码,请自行修改,后面以111111为例
echo "111111" | passwd --stdin dolphinscheduler # 配置sudo免密
echo 'dolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' >> /etc/sudoers
sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
注意: - 因为是以 sudo -u {linux-user} 切换不同linux用户的方式来实现多租户运行作业,所以部署用户需要有 sudo 权限,而且是免密的。 - 如果发现/etc/sudoers文件中有"Default requiretty"这行,也请注释掉 - 如果用到资源上传的话,还需要在`HDFS或者MinIO`上给该部署用户分配读写的权限
3>配置host映射和ssh打通
vim /etc/hosts 192.168.30.141 s141
192.168.30.142 s142
192.168.30.143 s143
192.168.30.144 s144
192.168.30.145 s145
192.168.30.146 s146
192.168.30.147 s147
在s141上,切换到部署用户并配置ssh本机免密登录(其他机器同理)
su dolphinscheduler; ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
注意:正常设置后,dolphinscheduler用户在执行命令ssh localhost 是不需要再输入密码的
在s141上,配置部署用户dolphinscheduler ssh打通到其他待部署的机器(其他机器同理)
su dolphinscheduler;
for ip in s142 s143 s144 s145 s146 s147; #请将此处s142 s143等替换为自己要部署的机器的hostname
do
ssh-copy-id $ip #该操作执行过程中需要手动输入dolphinscheduler用户的密码
done
# 当然 通过 sshpass -p xxx ssh-copy-id $ip 就可以省去输入密码了
在s141上,修改目录权限,创建并使得部署用户对/opt/dolphinscheduler目录有操作权限(其他机器同理)
cd /opt
mkdir dolphinscheduler
sudo chown -R dolphinscheduler:dolphinscheduler dolphinscheduler
2.安装包获取
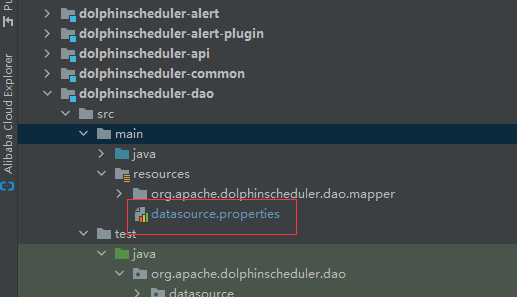
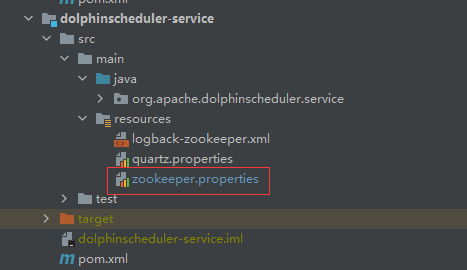
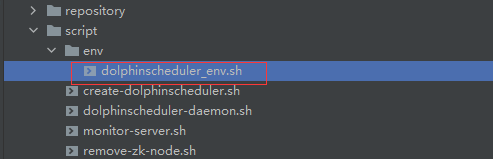
可以下载最新版本的后端安装包,也可以从github上clone源代码自己打包,推荐后者,可以先把datasource.properties中数据库连接修改为对应的,把dolphinscheduler_env.sh中环境变量修改自己对应的位置,将代码包上传至服务器 /opt/dolphinscheduler 下
3.安装脚本
该脚本只启动了worker,如果要启动其他服务,可以解开注释或添加对应服务的命令即可,划分好集群中各机器部署的服务,对应相应的脚本
#!/bin/sh
workDir=`dirname $0`
workDir=`cd ${workDir};pwd` files=$(ls -l /opt/dolphinscheduler/ |awk '/^-/ {print $NF}' | grep 'apache-dolphinscheduler-incubating')
file=''
for i in $files
do
file=$i
done
tar -zxvf $workDir/$file -C $workDir
ds_dir=${file%%.tar.gz*} #sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop master-server
sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop worker-server
#sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh stop api-server rm -rf $workDir/dolphinscheduler
echo "mv $workDir/$ds_dir to $workDir/dolphinscheduler"
mv $workDir/$ds_dir $workDir/dolphinscheduler chmod 755 $workDir/dolphinscheduler/bin/*
sed -i 's/\r$//' $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh
sed -i 's/\r$//' $workDir/dolphinscheduler/conf/env/dolphinscheduler_env.sh #sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh start master-server
sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh start worker-server
#sh $workDir/dolphinscheduler/bin/dolphinscheduler-daemon.sh start api-server
4.部署
这里使用Alibaba Cloud Toolkit插件,可以很方便部署到多台机器上
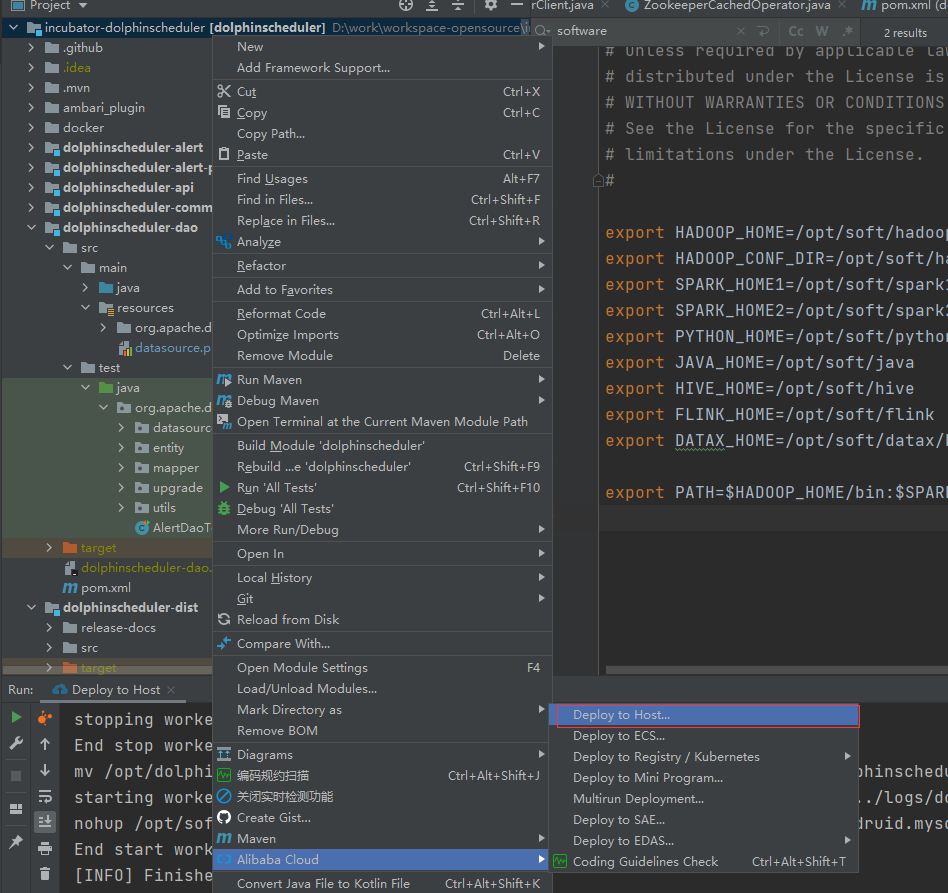
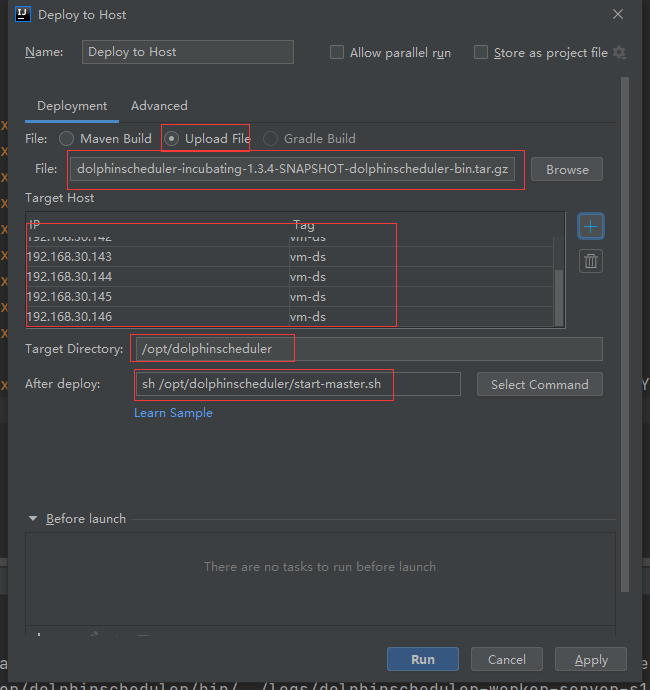
查看服务:
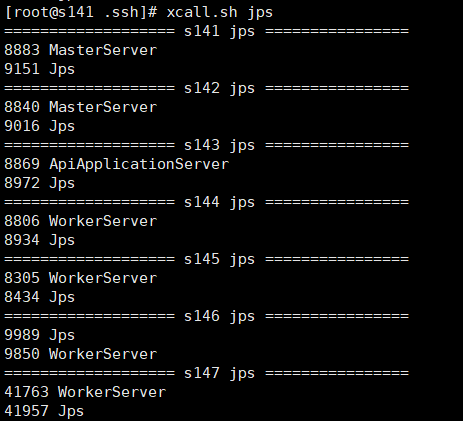
集群服务启动成功
访问页面:http://192.168.30.143:12345/dolphinscheduler
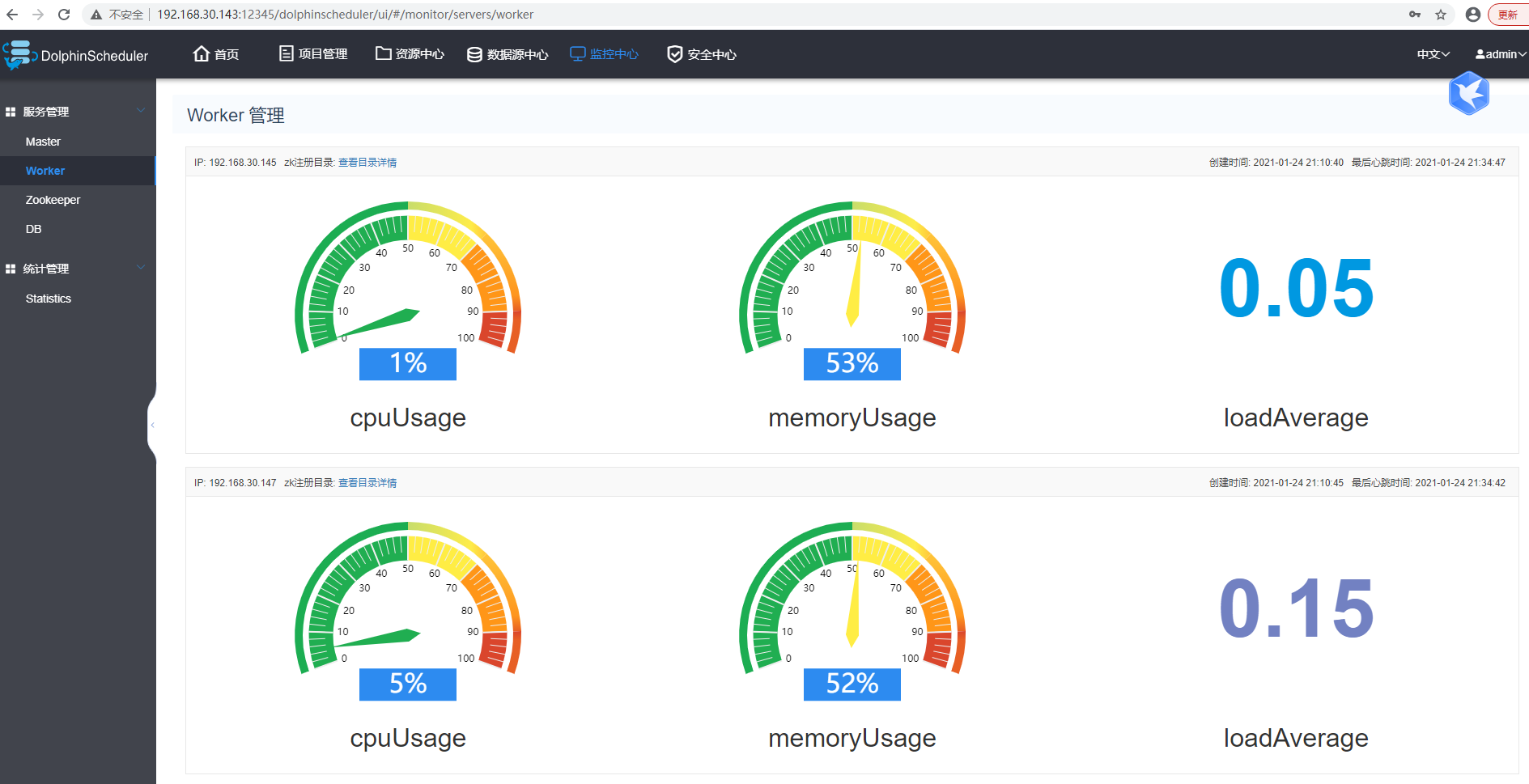
部署成功
centos7搭建dolphinscheduler集群的更多相关文章
- centos7搭建kafka集群-第二篇
好了,本篇开始部署kafka集群 Zookeeper集群搭建 注:Kafka集群是把状态保存在Zookeeper中的,首先要搭建Zookeeper集群(也可以用kafka自带的ZK,但不推荐) 1.软 ...
- centos7搭建kafka集群
一.安装jdk 1.下载jdk压缩包并移动到/usr/local目录 mv jdk-8u162-linux-x64.tar.gz /usr/local 2.解压 tar -zxvf jdk-8u162 ...
- 【转】centos7 搭建etcd集群
转自http://www.cnblogs.com/zhenyuyaodidiao/p/6237019.html 一.简介 “A highly-available key value store for ...
- 初学Hadoop:利用VMWare+CentOS7搭建Hadoop集群
一.前言 开始学习数据处理相关的知识了,第一步是搭建一个Hadoop集群.搭建一个分布式集群需要多台电脑,在此我选择采用VMWare+CentOS7搭建一个三台虚拟机组成的Hadoop集群. 注:1 ...
- Centos7搭建zookeeper集群
centos7与之前的版本都不一样,修改主机名在/ect/hostname 和/ect/hosts 这两个文件控制 首先修改/ect/hostname vi /ect/hostname 打开之后的内容 ...
- CentOS7 搭建RabbitMQ集群 后台管理 历史消费记录查看
简介 通过 Erlang 的分布式特性(通过 magic cookie 认证节点)进行 RabbitMQ 集群,各 RabbitMQ 服务为对等节点,即每个节点都提供服务给客户端连接,进行消息发送与接 ...
- CentOS7 搭建 Consul 集群
环境准备: ssh shell工具: 远程连接 三个CentOS示例: 部署集群 配置好各个实例之间的网络访问,以及ssh免密登录. 下载&上传: 1.下载 Consul: Download ...
- CentOS7 搭建 Redis 集群
一.手动搭建 1. 准备节点 节点数量至少为 6 个才能保证组成完整高可用的集群 (1) 目录结构 cluster ├── 9001 │ ├── data │ │ ├── appendon ...
- Centos7搭建k8s集群
一.部署环境 操作系统:CentOS Linux release 7.6.1810 (Core) 安装软件: docker:18.06.3-ce kubernetes:v1.15.4 二.部署架构: ...
随机推荐
- 使用 vue 仿写的一个购物商城
在学习了 vue 之后,决定做一个小练习,仿写了一个有关购物商城的小项目.下面就对项目做一个简单的介绍. 项目源码: github 项目的目录结构 -assets 与项目有关的静态资源,包括 css, ...
- iOS 集成友盟分享图片链接为http时无法加载问题解决
一.问题描述 UMShareWebpageObject *obj = [UMShareWebpageObject shareObjectWithTitle:title descr:shareText ...
- 使用Attribute限制Action只接受Ajax请求
原博文 https://www.cnblogs.com/h82258652/p/3939365.html 代码 /// <summary> /// 仅允许Ajax操作 /// </s ...
- 基于frp的内网穿透实例4-为本地的web服务实现HTTPS访问
原文地址:https://wuter.cn/1932.html/ 一.想要实现的功能 目前已经实现将本地的web服务暴露到公网,现想要实现https访问.(前提:已经有相应的证书文件,如果没有就去申请 ...
- Json串的字段如果和类中字段不一致,如何映射、转换?
Json串是我们现在经常会遇到的一种描述对象的字符串格式.在用Java语言开发的功能中,也经常需要做Json串与Java对象之间的转换. fastjson就是经常用来做Json串与Java对象之间的转 ...
- SM4
整体结构 T变换 SM4解密的合理性证明 秘钥扩展
- 使用node+puppeteer+express搭建截图服务
使用node+puppeteer+express搭建截图服务 转载请注明出处https://www.cnblogs.com/funnyzpc/p/14222807.html 写在之前 一开始我们的需求 ...
- C语言-表达式和运算符
表达式:表达式是c语言的主体,在c语言中,表达式由操作符和操作数组成.简单的表达式可以只有一个操作数.根据操作符的个数,可以将表达式分为简单表达式和复杂表达式,简单的表达式只含有一个操作符(如:5+5 ...
- 在onelogin中使用OpenId Connect Authentication Flow
目录 简介 OpenId Connect和Authentication Flow简介 onelogin的配置工作 使用应用程序连接onelogin 程序中的关键步骤 总结 简介 onelogin是一个 ...
- ASP.NET Core路由中间件[3]: 终结点(Endpoint)
到目前为止,ASP.NET Core提供了两种不同的路由解决方案.传统的路由系统以IRouter对象为核心,我们姑且将其称为IRouter路由.本章介绍的是最早发布于ASP.NET Core 2.2中 ...