使用RSEM进行转录组测序的差异表达分析
仍然是两年前的笔记
1. prepare-reference
如果用RSEM对比对后的bam进行转录本定量,则在比对过程中要确保比对用到的索引是由rsem-prepare-reference产生的。
~/software/rsem/rsem-prepare-reference \
--transcript-to-gene-map ~/project/RNA-seq/ref_cds/gene_transcript.txt \ #作用是在后面的定量结果文件中,添加gene名称, 转录本名称两列,该文件每一行都是gene_id\ttranscript_id的形式,eg: cluster_11236 cluster_11236.1
--bowtie2 \ #RSEM可调用bowtie, bowtie2, STAR三种比对工具;这里选用bowtie2
~/project/RNA-seq/ref_cds/HC_cds_and_8sample_clustercds.fa \
~/project/RNA-seq/ref_cds/cds.byrsem

可以看到,单纯用bowtie2建的索引和rsem调用bowtie2建的索引是不一样的。
2. calculate-expression
用法分为两类,分别是从fa/fq得到表达矩阵,和从sam/bam得到表达矩阵(仍然要求是比对到rsem-prepare-reference生成的索引)。以单端的fq数据为例。
rsem-calculate-expression [options] upstream_read_file(s) reference_name sample_name
rsem-calculate-expression [options] --paired-end upstream_read_file(s) downstream_read_file(s) reference_name sample_name
rsem-calculate-expression [options] --sam/--bam [--paired-end] input reference_name sample_name
cat ~/project/RNA-seq/dir.txt | while read id
do
~/software/rsem/rsem-calculate-expression -p 8 --bowtie2 \
~/project/data/RNA-seq/${id}.fastq.gz \
~/project/RNA-seq/ref_cds/cds.byrsem \
--samtools-sort-mem 2G --fragment-length-mean 50 \ # 单端数据建议使用--fragment-length-mean和--fragment-length-sd
~/project/RNA-seq/map/${id}.rsem
done

完成之后得到这些文件,其中,rsem.genes.results和rsem.isoforms.results分别表示gene水平和转录本水平的定量结果。每一列含义:
less rsem.genes.results|head -n 1
gene_id transcript_id(s) length effective_length expected_count TPM FPKM
less rsem.isoforms.results|head -n 1
transcript_id gene_id length effective_length expected_count TPM FPKM IsoPct
后面用EBseq检验差异基因/转录本时,会使用到这两个文件。
3. Differential Expression Analysis using EBSeq
下面以gene水平差异分析为例。
3.1 generate-data-matrix
这一步提取上一步得到的每个样本定量结果文件中的expected_count列,组成数据矩阵。
~/software/rsem/rsem-generate-data-matrix \
SRR1.rsem.genes.results SRR2.rsem.genes.results \
SRR3.rsem.genes.results SRR4.rsem.genes.results \
SRR5.rsem.genes.results SRR6.rsem.genes.results \
SRR7.rsem.genes.results SRR8.rsem.genes.results \
> ~/project/RNA-seq/count/GeneMat.txt
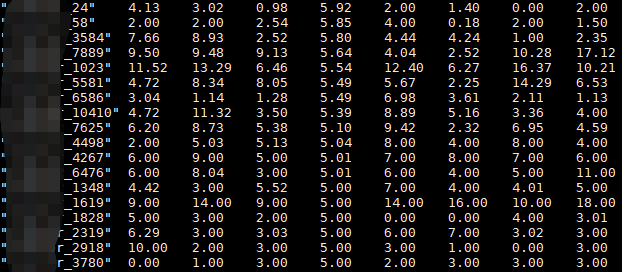
3.2 run-ebseq
调用EBseq进行检验
~/software/rsem/rsem-run-ebseq \
GeneMat.txt 2,2,2,2 GeneMat.results #2,2,2,2表示4个condition, 每个condition有两个重复;顺序要和3.1中输入文件表示的condition的顺序一致
#会得到三个文件
GeneMat.results.condmeans GeneMat.results GeneMat.results.pattern
#GeneMat.results.pattern
"C1" "C2" "C3" "C4"
"Pattern1" 1 1 1 1
"Pattern2" 1 1 1 2
"Pattern3" 1 1 2 1
"Pattern4" 1 1 2 2
"Pattern5" 1 2 1 1
"Pattern6" 1 2 1 2
"Pattern7" 1 2 2 1
"Pattern8" 1 2 2 2
"Pattern9" 1 1 2 3
"Pattern10" 1 2 1 3
"Pattern11" 1 2 2 3
"Pattern12" 1 2 3 1
"Pattern13" 1 2 3 2
"Pattern14" 1 2 3 3
"Pattern15" 1 2 3 4
#以Pattern14为例,1 2 3 3表示某基因表达:C1与C2不同,C3与C4相同
#四种condition如果有基因表达存在差异,就这些情况了
#GeneMat.results
#第一列是各个基因名称,接着15列是该基因符合该种Parttern的概率
#"MAP"为该基因最可能的模式;"PPDE":posterior probability of being differentially expressed,越大越好
"Pattern1" "Pattern2" "Pattern3" "Pattern4" "Pattern5" "Pattern6" "Pattern7" "Pattern8" "Pattern9" "Pattern10" "Pattern11" "Pattern12" "Pattern13" "Pattern14" "Pattern15" "MAP" "PPDE"
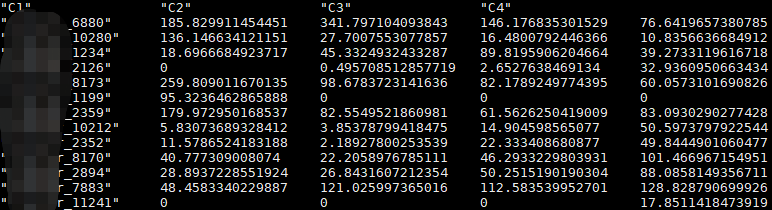
#GeneMat.results.condmeans
#为每个样本合并重复之后的定量结果,如下图,这个结果可以用来控制fold change
3.3 control_fdr
控制FDR(错误发现率)来挑选差异基因
~/software/rsem/rsem-control-fdr \
GeneMat.results 0.05 GeneMat.de.txt
将GeneMat.results文件中,PPDE大于0.95的记录提取出来
因水平有限,有错误的地方,欢迎批评指正!
使用RSEM进行转录组测序的差异表达分析的更多相关文章
- 转录组差异表达分析工具Ballgown
Ballgown是分析转录组差异表达的R包. 软件安装: 运行R, source(“http://bioconductor.org/biocLite.R”) biocLite(“ballgown”) ...
- 单细胞转录组测序数据的可变剪接(alternative splicing)分析方法总结
可变剪接(alternative splicing),在真核生物中是一种非常基本的生物学事件.即基因转录后,先产生初始RNA或称作RNA前体,然后再通过可变剪接方式,选择性的把不同的外显子进行重连,从 ...
- 差异表达分析之FDR
差异表达分析之FDR 随着测序成本的不断降低,转录组测序分析已逐渐成为一种很常用的分析手段.但对于转录组分析当中的一些概念,很多人还不是很清楚.今天,小编就来谈谈在转录组分析中,经常会遇到的一个概念F ...
- Differential expression analysis for paired RNA-seq data 成对RNA-seq数据的差异表达分析
Differential expression analysis for paired RNA-seq data 抽象背景:RNA-Seq技术通过产生序列读数并在不同生物条件下计数其频率来测量转录本丰 ...
- RNA-Seq differential expression analysis: An extended review and a software tool RNA-Seq差异表达分析: 扩展评论和软件工具
RNA-Seq differential expression analysis: An extended review and a software tool RNA-Seq差异表达分析: 扩展 ...
- 表达谱(DGE)测序与转录组测序的差别
DGE-seq和普通的transcriptomic profiling相比较有什么不同,有什么特点? DGE就是用酶将mRNA切断,只使用靠近poly A的一小段RNA去测序. #1 由于不是测定mR ...
- 单细胞转录组测序技术(scRNA-seq)及细胞分离技术分类汇总
单细胞测序流程(http://learn.gencore.bio.nyu.edu) 在过去的十多年里,高通量测序技术被广泛应用于生物和医学的各种领域,极大促进了相关的研究和应用.其中转录组测序(RNA ...
- 转录组测序(RNA-seq)技术
转录组是某个物种或者特定细胞类型产生的所有转录本的集合.转录组研究能够从整体水 平研究基因功能以及基因结构,揭示特定生物学过程以及疾病发生过程中的分子机理,已广泛应 用于基础研究.临床诊断和药 ...
- 转录组分析综述A survey of best practices for RNA-seq data analysis
转录组分析综述 转录组 文献解读 Trinity cufflinks 转录组研究综述文章解读 今天介绍下小编最近阅读的关于RNA-seq分析的文章,文章发在Genome Biology 上的A sur ...
随机推荐
- scala 时间,时间格式转换
scala 时间,时间格式转换 1.scala 时间格式转换(String.Long.Date) 1.1时间字符类型转Date类型 1.2Long类型转字符类型 1.3时间字符类型转Long类型 2. ...
- [源码分析] Dynomite 分布式存储引擎 之 DynoJedisClient(1)
[源码分析] Dynomite 分布式存储引擎 之 DynoJedisClient(1) 目录 [源码分析] Dynomite 分布式存储引擎 之 DynoJedisClient(1) 0x00 摘要 ...
- Codeforces 1364C - Ehab and Prefix MEXs
题意:给1e5的数组a 保证 ai <= ai+1 ai<=i 求一个一样长的数组b 使得mex(b1,b2···bi) = ai QAQ:不知道为啥这1600分的题比赛时出不了 啊啊 ...
- Educational Codeforces Round 84 E. Count The Blocks
传送门: 1327- E. Count The Blocks 题意:给你一个整数n,求10^n内(每个数有前导零)长度为1到n的块分别有多少个.块的含义是连续相同数字的长度. 题解:从n=1开始枚举 ...
- Codeforces Round #479 (Div. 3) C. Less or Equal (排序,贪心)
题意:有一个长度为\(n\)的序列,要求在\([1,10^9]\)中找一个\(x\),使得序列中恰好\(k\)个数满足\(\le x\).如果找不到\(x\),输出\(-1\). 题解:先对这个序列排 ...
- Codeforces Round #669 (Div. 2) C. Chocolate Bunny (交互,构造)
题意:有一个长度为\(n\)的隐藏序列,你最多可以询问\(2n\)次,每次可以询问\(i\)和\(j\)位置上\(p[i]\ mod\ p[j]\)的结果,询问的格式是\(?\ x\ y\),如果已经 ...
- QQ空间自动点赞js代码
1.jQuery().each(): each() 方法为每个匹配元素规定要运行的函数. 提示:返回 false 可用于及早停止循环. 函数原型: function(index,element) 为每 ...
- js中for循环遍历的写法
众所周知,for循环是编程中必不可少的知识点:那么如何高效的写出循环呢? 我们要先知道for循环的基础样式是由自有变量自增自减和if判组成的: 1 for(条件){ 2 执行语句 3 } 而for循环 ...
- kubeadm---高可用安装
1.修改主机名 如何使用hostnamectl set-hostname name来为每台主机设置不同的机器名 #hostnamectl set-hostname k8s-master01 或者使用以 ...
- Java中输出小数点后几位
笔试时候,遇到让你写输出小数点后几位,当时很是头疼,下来后,查了查发现,没什么难的.网上有各种情况都讨论了(一般分为4种),在这里我着重讨论一下比较实用,比较简单,比较方便操作的几种: 1 publi ...