mysql单列去重复group by分组取每组前几条记录加order by排序
mysql分组取每组前几条记录(排名) 附group by与order by的研究,需要的朋友可以参考下
--按某一字段分组取最大(小)值所在行的数据
复制代码代码如下:
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
--创建表并插入数据:
复制代码代码如下:
create table tb(name varchar(10),val int,memo varchar(20))
insert into tb values('a', 2, 'a2(a的第二个值)')
insert into tb values('a', 1, 'a1--a的第一个值')
insert into tb values('a', 3, 'a3:a的第三个值')
insert into tb values('b', 1, 'b1--b的第一个值')
insert into tb values('b', 3, 'b3:b的第三个值')
insert into tb values('b', 2, 'b2b2b2b2')
insert into tb values('b', 4, 'b4b4')
insert into tb values('b', 5, 'b5b5b5b5b5')
go
--一、按name分组取val最大的值所在行的数据。
复制代码代码如下:
--方法1:select a.* from tb a where val = (select max(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val > a.val)
--方法3:
select a.* from tb a,(select name,max(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , max(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name
/*
name val memo
---------- ----------- --------------------
a 3 a3:a的第三个值
b 5 b5b5b5b5b5
*/
本人推荐使用1,3,4,结果显示1,3,4效率相同,2,5效率差些,不过我3,4效率相同毫无疑问,1就不一样了,想不搞了。
--二、按name分组取val最小的值所在行的数据。
复制代码代码如下:
--方法1:select a.* from tb a where val = (select min(val) from tb where name = a.name) order by a.name
--方法2:
select a.* from tb a where not exists(select 1 from tb where name = a.name and val < a.val)
--方法3:
select a.* from tb a,(select name,min(val) val from tb group by name) b where a.name = b.name and a.val = b.val order by a.name
--方法4:
select a.* from tb a inner join (select name , min(val) val from tb group by name) b on a.name = b.name and a.val = b.val order by a.name
--方法5
select a.* from tb a where 1 > (select count(*) from tb where name = a.name and val < a.val) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 1 b1--b的第一个值
*/
--三、按name分组取第一次出现的行所在的数据。
复制代码代码如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
*/
--四、按name分组随机取一条数据。
复制代码代码如下:
select a.* from tb a where val = (select top 1 val from tb where name = a.name order by newid()) order by a.name/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
b 5 b5b5b5b5b5
*/
--五、按name分组取最小的两个(N个)val
复制代码代码如下:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val < a.val ) order by a.name,a.valselect a.* from tb a where val in (select top 2 val from tb where name=a.name order by val) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val < a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 1 a1--a的第一个值
a 2 a2(a的第二个值)
b 1 b1--b的第一个值
b 2 b2b2b2b2
*/
--六、按name分组取最大的两个(N个)val
复制代码代码如下:
select a.* from tb a where 2 > (select count(*) from tb where name = a.name and val > a.val ) order by a.name,a.val
select a.* from tb a where val in (select top 2 val from tb where name=a.name order by val desc) order by a.name,a.val
select a.* from tb a where exists (select count(*) from tb where name = a.name and val > a.val having Count(*) < 2) order by a.name
/*
name val memo
---------- ----------- --------------------
a 2 a2(a的第二个值)
a 3 a3:a的第三个值
b 4 b4b4
b 5 b5b5b5b5b5
*/
--七,假如整行数据有重复,所有的列都相同(例如下表中的第5,6两行数据完全相同)。
按name分组取最大的两个(N个)val
复制代码代码如下:
/*
数据如下:
name val memo
a 2 a2(a的第二个值)
a 1 a1--a的第一个值
a 1 a1--a的第一个值
a 3 a3:a的第三个值
a 3 a3:a的第三个值
b 1 b1--b的第一个值
b 3 b3:b的第三个值
b 2 b2b2b2b2
b 4 b4b4
b 5 b5b5b5b5b5
*/
附:mysql “group by ”与"order by"的研究
这两天让一个数据查询难了。主要是对group by 理解的不够深入。才出现这样的情况
这种需求,我想很多人都遇到过。下面是我模拟我的内容表

我现在需要取出每个分类中最新的内容
select * from test group by category_id order by `date`
结果如下

明显。这不是我想要的数据,原因是msyql已经的执行顺序是
引用
写的顺序:select ... from... where.... group by... having... order by..
执行顺序:from... where...group by... having.... select ... order by...
所以在order by拿到的结果里已经是分组的完的最后结果。
由from到where的结果如下的内容。
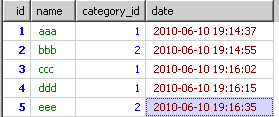
到group by时就得到了根据category_id分出来的多个小组


到了select的时候,只从上面的每个组里取第一条信息结果会如下

即使order by也只是从上面的结果里进行排序。并不是每个分类的最新信息。
回到我的目的上 --分类中最新的信息
根据上面的分析,group by到select时只取到分组里的第一条信息。有两个解决方法
1,where+group by(对小组进行排序)
2,从form返回的数据下手脚(即用子查询)
由where+group by的解决方法
对group by里的小组进行排序的函数我只查到group_concat()可以进行排序,但group_concat的作用是将小组里的字段里的值进行串联起来。
select group_concat(id order by `date` desc) from `test` group by category_id

再改进一下
select * from `test` where id in(select SUBSTRING_INDEX(group_concat(id order by `date` desc),',',1) from `test` group by category_id ) order by `date` desc

子查询解决方案
select * from (select * from `test` order by `date` desc) `temp` group by category_id order by `date` desc

mysql单列去重复group by分组取每组前几条记录加order by排序的更多相关文章
- mysql分组取每组前几条记录(排名)
1.创建表 create table tb( name varchar(10), val int, memo varchar(20) ); 2.插入数据 insert into tb values(' ...
- Mysql SQL分组取每组前几条记录
按name分组取最大的两个val: [比当前记录val大的条数]小于2条:即当前记录为为分组中的前两条 > (select count(*) from tb where name = a.nam ...
- mysql分组取每组前几条记录(排序)
首先来造一部分数据,表mygoods为商品表,cat_id为分类id,goods_id为商品id,status为商品当前的状态位(1:有效,0:无效). CREATE TABLE `mygoods` ...
- MYSQL 按某个字段分组,然后取每组前3条记录
先初始化一些数据,表名为 test ,字段及数据为: SQL执行结果为:每个 uid 都只有 3 条记录. SQL语句为: SELECT * FROM test main WHERE ...
- SQL分组取每组前一(或几)条记录(排名)
mysql分组取每组前几条记录(排名) 附group by与order by的研究 http://www.jb51.net/article/31590.htm --按某一字段分组取最大(小)值所在行的 ...
- MySQL 先按某字段分组,再取每组中前N条记录
按 gpcode每组 取每组 f4 最大的那条记录: 方法一: select * from calcgsdataflash a where gscode = 'LS_F' and ymd >= ...
- [mysql] 先按某字段分组再取每组中前N条记录
From: http://blog.chinaunix.net/uid-26729093-id-4294287.html 请参考:http://bbs.csdn.net/topics/33002126 ...
- MySQL 分组后取每组前N条数据
与oracle的 rownumber() over(partition by xxx order by xxx )语句类似,即:对表分组后排序 创建测试emp表 1 2 3 4 5 6 7 8 9 ...
- 记一次有意思的 SQL 实现 → 分组后取每组的第一条记录
开心一刻 今天,朋友气冲冲的走到我面前 朋友:我不是谈了个女朋友,谈了三个月嘛,昨天我偷看她手机,你猜她给我备注什么 我:备注什么? 朋友:舔狗 2 号! 我一听,气就上来了,说道:走,找她去,这婆娘 ...
随机推荐
- CornerStone的使用
俗话说:"工欲善其事必先利其器": 对于我们程序员来说,不管你是大神,还是小鱼小虾,进入公司之后,都用过源码管理工具,不然你就不是一个合格的程序员,现在各个公司用于源码管理工具通常 ...
- 设计模式--命令模式Command(对象行为型)
一.命令模式 将一个请求封装为一个对象,从而让你使用不同的请求把客户端参数化,对请求排队或者记录请求日志,可以提供命令的撤销和恢复功能. (1)Command类:是一个抽象类,类中对需要执行的命令进行 ...
- jquery Datatables 行数据删除、行上升、行下降功能演示
Datatables 是一款jquery表格插件.它是一个高度灵活的工具,可以将任何HTML表格添加高级的交互功能. 官方网站:http://www.datatables.net Datatables ...
- php中通过DOM操作XML
DOM文档在js里早就接触过,知道DOM不但可以操作html文档,还可以操作XHTML,XML等文档,有着极强的通用性,下面我们通过两个小例子,看看在PHP中是如何用DOM操作XML文档的,和js中差 ...
- 多Linux系统如何复用/home目录
Brief: 1./home单独分区:2.不同系统/home建立不同的用户名:3.不同系统/home对其他用户授权 Linux下/home文件夹可以通用吗?例如我机器上同时装了两个Linux系统,可以 ...
- Redis3重建Cluster
1.关闭cluster全部节点2.删除所有nodes.conf文件3.开启全部节点4.依次flushall5.重建集群即可 Share the post "Redis3重建Cluster&q ...
- 继承映射关系 TPH、TPT、TPC<EntityFramework6.0>
每个类型一张表[TPT] 声明方式 public class Business { [Key] public int BusinessId { get; protected set; } public ...
- HTTPS和HTTP的区别(转)
HTTPS和HTTP的区别 超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信 息.HTTP协议以明文方式发送内容,不提供任何方式的数据加密,如果攻击者截取了Web浏览器和网站服务器 ...
- 通过FileHandle获取FileObject对象
<div id="wrap"> <!-- google_ad_section_start --> NTSTATUS MyNtReadFile(<br& ...
- SPOJ - PLSQUARE Palin Squar(hash+回文串)
题意:给你一个n*n (n<=200)的字符串矩阵,问你每行每列都是回文串的最大的m*m的矩阵是多少 题解:首先答案不满足单调性,即m成立而m-1与m+1都却不一定成立,所以必须枚举答案确定现在 ...