菜鸟之路——机器学习之决策树个人理解及Python实现
最近开始学习机器学习,以下会记录我学习中遇到的问题以及我个人的理解
决策树算法,网上很多介绍,在这不复制粘贴。下面解释几个关键词就好。
信息熵(entropy):就是信息不确定性的多少 H(x)=-ΣP(x)log2[P(x)]。变量的不确定性越大,熵就越大。
信息获取量(Information Gain):这是ID3算法中定义的一个选择属性判断结点的算法。Gain(A)=H(D)-HA(D)。就是本的信息熵与下一级的信息熵之差。用来确定信息获取量的多少,信息获取量最多的即选择为本级的判断属性。就这样一层一层的算,一层一层的判断。
决策树的原理很简答,表达也很直观,Python中的sklearn库能够直接实现
from sklearn.feature_extraction import DictVectorizer
import csv
from sklearn import preprocessing
from sklearn import tree
from sklearn.externals.six import StringIO allElectronicsData=open (r'AllElectronics.csv','rt') #'rb'是读取二进制文件,'rt'是读取文本文件 r‘’是让字符串里面的转义字符失效
reader=csv.reader(allElectronicsData)
headers=next(reader) #读取下一行数据
print("headers:",headers) #将表格转化为特征向量字典列表和标签列表
FeatureList=[] #储存特征向量字典列表
LableList=[] #储存标签列表
for row in reader:
LableList.append(row[len(row)-1])
rowDict={}
for i in range(1,len(row)-1):
rowDict[headers[i]]=row[i]
FeatureList.append(rowDict)
print("LableList:",LableList)
print("FeatureList:",FeatureList) #将上述列表转化为sklearn可处理的形式。也就是每个属性每个元素都表示出来,有为1 ,没有为0
vec=DictVectorizer()
dummyX=vec.fit_transform(FeatureList) .toarray()#转化为矩阵
print("dummyX",dummyX)
print(vec.get_feature_names()) lb=preprocessing.LabelBinarizer()
dummyY = lb.fit_transform(LableList)
print("dummyY",dummyY) #直接利用sklearn里面的tree分类器进行创建model
clf=tree.DecisionTreeClassifier(criterion='entropy')#创建分类器,criterion是选取算法,entropy信息熵
clf=clf.fit(dummyX,dummyY)
print("clf:",clf) #保存为dot文件,可用graphviz画出决策树
with open("allElectronics.dot",'w') as f:
f=tree.export_graphviz(clf,feature_names=vec.get_feature_names(),out_file=f) #预测
newRowX=dummyX[0,:] #取一个之前数据的第一行 newRowX[0]=1
newRowX[2]=0 #修改第一个属性,也就是弄出来个新的数据,这的0,1,还是上面解释的,此属性有就是1,没有就是0 print("newRowX:",newRowX)
newRowX=[newRowX] #一定要注意这个,predict的输入必须是个二位数据
predictedY = clf.predict(newRowX)
print("predictedY: " + str(predictedY))
里面有我注解的解释,此源码来自于麦子学院课程视频。
运行之后的结果为:
headers: ['RID', 'age', 'income', 'student', 'credit_rating', 'class_buys_computer']
LableList: ['no', 'no', 'yes', 'yes', 'yes', 'no', 'yes', 'no', 'yes', 'yes', 'yes', 'yes', 'yes', 'no']
FeatureList: [{'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'high', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'low', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'youth', 'income': 'medium', 'student': 'no', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'low', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'youth', 'income': 'medium', 'student': 'yes', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}, {'age': 'middle_aged', 'income': 'high', 'student': 'yes', 'credit_rating': 'fair'}, {'age': 'senior', 'income': 'medium', 'student': 'no', 'credit_rating': 'excellent'}]
dummyX [[0. 0. 1. 0. 1. 1. 0. 0. 1. 0.]
[0. 0. 1. 1. 0. 1. 0. 0. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
[0. 1. 0. 0. 1. 0. 0. 1. 1. 0.]
[0. 1. 0. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 1. 0. 0. 1.]
[1. 0. 0. 1. 0. 0. 1. 0. 0. 1.]
[0. 0. 1. 0. 1. 0. 0. 1. 1. 0.]
[0. 0. 1. 0. 1. 0. 1. 0. 0. 1.]
[0. 1. 0. 0. 1. 0. 0. 1. 0. 1.]
[0. 0. 1. 1. 0. 0. 0. 1. 0. 1.]
[1. 0. 0. 1. 0. 0. 0. 1. 1. 0.]
[1. 0. 0. 0. 1. 1. 0. 0. 0. 1.]
[0. 1. 0. 1. 0. 0. 0. 1. 1. 0.]]
['age=middle_aged', 'age=senior', 'age=youth', 'credit_rating=excellent', 'credit_rating=fair', 'income=high', 'income=low', 'income=medium', 'student=no', 'student=yes']
dummyY [[0]
[0]
[1]
[1]
[1]
[0]
[1]
[0]
[1]
[1]
[1]
[1]
[1]
[0]]
clf: DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, presort=False, random_state=None,
splitter='best')
newRowX: [1. 0. 0. 0. 1. 1. 0. 0. 1. 0.]
predictedY: [1]
此外可用Graphviz画出决策图。
这就用到了代码中生成的dot文件,在cmd命令中运行以下命令

主要是dot -T pdf input.dot -o output.pdf这个命令。(Graphviz的安装方法网上多的是,记得添加环境变量)
生成pdf 的截图为
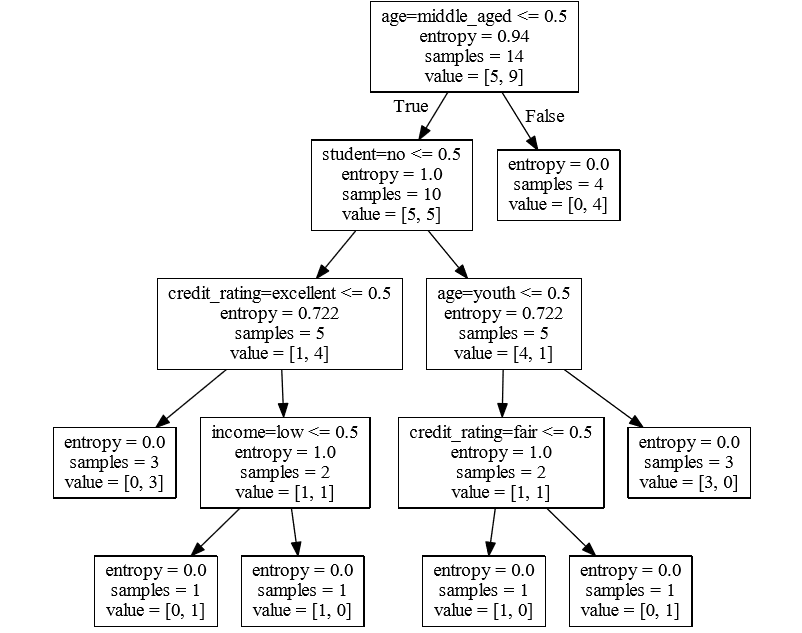
看着更直观
我编程过程中遇到几个问题,课程里面的源码不能直接运行。报错
ValueError: Expected 2D array, got 1D array instead:
array=[1. 0. 0. 0. 1. 1. 0. 0. 1. 0.].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
如果不要第50行,就是newRowX是一维数组,而predict方法的输入量必须是二维的数组。所以加上newRowX=[newRowX],将newRowX再用[]包括,使之变为二维的数组即可。
另外注意第七行'rb'和'rt'的区别,如果用'rb'就会报错
_csv.Error: iterator should return strings, not bytes (did you open the file in text mode?)
以上就是我学习过程中遇到的问题和个人理解了。
菜鸟之路——机器学习之决策树个人理解及Python实现的更多相关文章
- 菜鸟之路——机器学习之非线性回归个人理解及python实现
关键词: 梯度下降:就是让数据顺着梯度最大的方向,也就是函数导数最大的放下下降,使其快速的接近结果. Cost函数等公式太长,不在这打了.网上多得是. 这个非线性回归说白了就是缩小版的神经网络. py ...
- 菜鸟之路——机器学习之线性回归个人理解及Python实现
这一节很简单,都是高中讲过的东西 简单线性回归:y=b0+b1x+ε.b1=(Σ(xi-x–)(yi-y–))/Σ(xi-x–)ˆ2 b0=y--b1x- 其中ε取 为均值为0的正态 ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- 菜鸟之路——机器学习之KNN算法个人理解及Python实现
KNN(K Nearest Neighbor) 还是先记几个关键公式 距离:一般用Euclidean distance E(x,y)√∑(xi-yi)2 .名字这么高大上,就是初中学的两点间的距离 ...
- 菜鸟之路——机器学习之BP神经网络个人理解及Python实现
关键词: 输入层(Input layer).隐藏层(Hidden layer).输出层(Output layer) 理论上如果有足够多的隐藏层和足够大的训练集,神经网络可以模拟出任何方程.隐藏层多的时 ...
- 菜鸟之路——机器学习之SVM分类器学习理解以及Python实现
SVM分类器里面的东西好多呀,碾压前两个.怪不得称之为深度学习出现之前表现最好的算法. 今天学到的也应该只是冰山一角,懂了SVM的一些原理.还得继续深入学习理解呢. 一些关键词: 超平面(hyper ...
- 菜鸟之路——机器学习之HierarchicalClustering层次分析及个人理解
这个算法.我个人感觉有点鸡肋.最终的表达也不是特别清楚. 原理很简单,从所有的样本中选取Euclidean distance最近的两个样本,归为一类,取其平均值组成一个新样本,总样本数少1:不断的重复 ...
- 菜鸟之路——机器学习之Kmeans聚类个人理解及Python实现
一些概念 相关系数:衡量两组数据相关性 决定系数:(R2值)大概意思就是这个回归方程能解释百分之多少的真实值. Kmeans聚类大致就是选择K个中心点.不断遍历更新中心点的位置.离哪个中心点近就属于哪 ...
- 菜鸟之路——Linux基础::计算机网络基础,Linux常用系统命令,Linux用户与组权限
最近又重新安排了一下我的计划.准备跟着老男孩的教程继续学习,感觉这一套教程讲的很全面,很详细.比我上一套机器学习好的多了. 他的第一阶段是Python基础,第二阶段是高等数学基础,主要将机器学习和深度 ...
随机推荐
- 如果有人问你CAP理论是什么,就把这篇文章发给他。
绝对和你在网上看到的CAP定理介绍不一样. CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric B ...
- Notes 20180306 : 变量与常量
1.1 变量与常量 我们在开发中会经常听到常量和变量,那么常量和变量指的又是什么呢?顾名思义,在程序执行过程中,其值不能被改变的量称为常量,其值能被改变的量称为变量.变量与常量的命名都必须使用合法的标 ...
- 类似"音速启动"的原创工具简码"万能助手"在线用户数终于突破100了!
原本只是开发出来方便自己的一个小工具,看到群友也喜欢,就随手分享了, 经过1个多月的自然积累,在线用户数终于突破100了,这增长速度实在让人泪奔~ 博客园的朋友如果看到,喜欢的话就拿去用吧, 万能助手 ...
- ASP.NET Core获取微信订单数据
前几天对接了一波微信的订单,分享出来 1.生成签名 根据微信要求把appid.商户号.随机数.和订单号还有商户平台的密钥拼接成一个字符串然后进行MD5加密 2.拼接请求XML 然后用拼接好的XML向微 ...
- 导入/导出excel和PHPExcel基本使用
* PHPExcel基本使用 * PS:文章如果有误,请及时指出,给予修改 * 项目中导入PHPExcel * 可以去网上下载 github composer 都可以 * 为了方便下载,我将压缩包添加 ...
- 新系统设置 github 私钥
1.首先我得重新在git设置一下身份的名字和邮箱(因为当初都忘了设置啥了,因为遇到坑了)进入到需要提交的文件夹底下(因为直接打开git Bash,在没有路径的情况下,根本没!法!改!刚使用git时遇到 ...
- u-boot.2012.10makefile分析,良心博友汇总
声明:以下内容大部分来自网站博客文章,仅作学习之用1.uboot系列之-----顶层Makefile分析(一)1.u-boot.bin生成过程分析 2.make/makefile中的加号+,减号-和a ...
- UART学习之路(四)VerilogHDL实现的简单UART,VIVADO下完成仿真
用VerilogHDL实现UART并完成仿真就算是对UART整个技术有了全面的理解,同时也算是Verilog入门了.整个UART分为3部分完成,发送模块(Transmitter),接收模块(Recei ...
- 【blockly教程】第二章 Blockly编程基础
2.1 Blockly的数据类型 2.1.1 数据的含义 在计算机程序的世界里,程序的基本任务就是处理数据,无论是数值还是文字.图像.图形.声音.视频等信息,如果要在计算机中处理的话,就必须将它们转 ...
- vue跨域访问
第一次创建vue项目,画完静态页面一切顺利,准备和后台进行联调,问题来了,无论怎么调试使用Axios,jQuary还是使用原生的Ajax请求都访问不通(前提条件,另外一个人的电脑当成服务器,进行访问) ...