MySql的数据查询
SELECT语句是最常用的查询语句,它的使用方式有些复杂,但功能却相当强大。SELECT语句的基本语法如下:
select selection_list//要查询的内容,选择哪些列
from数据表名//指定数据表
where primary_constraint//查询时需要满足的条件,行必须满足的条件
group by grouping_columns//如何对结果进行分组
order by sorting_cloumns//如何对结果进行排序
having secondary_constraint//查询时满足的第二条件
limit count//限定输出的查询结果
单表查询
like使用
LIKE属于较常用的比较运算符,通过它可以实现模糊查询。它有两种通配符:“%”和下划线“_”:
“%”可以匹配一个或多个字符,可以代表任意长度的字符串,长度可以为0。例如,“明%技”表示以“明”开头,以“技”结尾的任意长度的字符串。该字符串可以代表明日科技、明日编程科技、明日图书科技等字符串。
“_”只匹配一个字符。例如,m_n表示以m开头,以n结尾的3个字符。中间的“_”可以代表任意一个字符。
select * from tb_login where user like '%mr%';
distinct使用
使用distinct关键字可以去除查询结果中的重复记录
select distinct 字段名 from 表名;
group by使用
通过GROUP BY子句可以将数据划分到不同的组中,实现对记录的分组查询。在查询时,所查询的列必须包含在分组的列中,目的是使查询到的数据没有矛盾。
1.使用GROUP BY关键字来分组
单独使用GROUP BY关键字,查询结果只显示每组的一条记录。
2.GROUP BY关键字与GROUP_CONCAT()函数一起使用
使用GROUP BY关键字和GROUP_CONCAT()函数查询,可以将每个组中的所有字段值都显示出来。
SELECT group_concat(id,district), service_type FROM hotel_supporting_service group by service_type;
ps:后六位是district,前面的是id

3.按多个字段进行分组
使用GROUP BY关键字也可以按多个字段进行分组。
聚合函数查询
聚合函数的最大特点是能够根据一组数据求出一个值。聚合函数的结果值只根据选定行中非NULL的值进行计算,NULL值被忽略。
select count (*)from tb_login;
select sum (row) from tb_book;
select avg(row) from tb_book;
select max(row) from tb_book;
select min(row) from tb_book;
连接查询
内连接查询
内连接是最普遍的连接类型,而且是最匀称的,因为它们要求构成连接的每一部分的每个表都匹配,不匹配的行将被排除。
内连接的最常见的例子是相等连接,也就是连接后的表中的某个字段与每个表中的都相同。这种情况下,最后的结果集只包含参加连接的表中与指定字段相符的行。
select name, books from tb_login, tb_book where tb_login.user=tb_book.user;
外连接查询
与内连接不同,外连接是指使用OUTER JOIN关键字将两个表连接起来。外连接生成的结果集不仅包含符合连接条件的行数据,而且还包括左表(左外连接时的表)、右表(右外连接时的表)或两边连接表(全外连接时的表)中所有的数据行。语法格式如下:
SELECT 字段名称 FROM 表名1 LEFT|RIGHT JOIN 表名2 ON 表名1.字段名1=表名2.属性名2;
外连接分为左外连接(LEFT JOIN)、右外连接(RIGHT JOIN)和全外连接3种类型。
1.左外连接
左外连接(LEFT JOIN)是指将左表中的所有数据分别与右表中的每条数据进行连接组合,返回的结果除内连接的数据外,还包括左表中不符合条件的数据,并在右表的相应列中添加NULL值。
select h.id,h.hotel_id,hp.id,hp.hotel_id
from hotel_supporting_service as h
left join hotel_supporting_service_protocol
as hp on hp.src_id = h.id;
2.右外连接
右外连接(RIGHT JOIN)是指将右表中的所有数据分别与左表中的每条数据进行连接组合,返回的结果除内连接的数据外,还包括右表中不符合条件的数据,并在左表的相应列中添加NULL。
select h.id,h.hotel_id,hp.id,hp.hotel_id
from hotel_supporting_service as h
right join hotel_supporting_service_protocol
as hp on hp.src_id = h.id;
复合条件连接查询
在连接查询时,也可以增加其他的限制条件。通过多个条件的复合查询,可以使查询结果更加准确。
select h.id,h.hotel_id,hp.id,hp.hotel_id
from hotel_supporting_service as h
left join hotel_supporting_service_protocol
as hp on hp.src_id = h.id where h.id>6;
ps: select h.id,h.hotel_id,hp.id,hp.hotel_id
from hotel_supporting_service as h
left join hotel_supporting_service_protocol
as hp on hp.src_id = h.id查出来后做过滤
子查询
子查询就是SELECT查询中的另一个查询的附属。可以嵌套多个查询,在外面一层的查询中使用里面一层查询产生的结果集。这样就不是执行两个(或者多个)独立的查询,而是执行包含一个(或者多个)子查询的单独查询。
当遇到这样的多层查询时,MySQL从最内层的查询开始,然后从它开始向外向上移动到外层(主)查询,在这个过程中每个查询产生的结果集都被赋给包围它的父查询,接着这个父查询被执行,它的结果也被指定给它的父查询。
除了结果集经常由包含一个或多个值的一列组成外,子查询和常规SELECT查询的执行方式一样。子查询可以用在任何可以使用表达式的地方,它必须由父查询包围,而且,如同常规的SELECT查询,它必须包含一个字段列表(这是一个单列列表)、一个具有一个或者多个表名字的FROM子句以及可选的WHERE、HAVING和GROUP BY子句。
select * from tb_login where user in (select user from tb_book);
select id, books, row from tb_book where row>= (select row from tb_row where id=1);
--查询如果tb_row表中存在name值为“优秀”的记录,则查询tb_book表中row字段大于等于90的记录。
select id, books, row from tb_book where row>=90 and exists (select*from tb_row where name='优秀'); (ps:使用EXISTS关键字时,内层查询语句不返回查询的记录。而是返回一个真假值。如果内层查询语句查询到满足条件的记录,就返回一个真值(true),否则,将返回一个假值(false)。当返回的值为true时,外层查询语句将进行查询;当返回的值为false时,外层查询语句不进行查询或者查询不出任何记录。)
select books, row from tb_book where row<ANY (select row from tb_row); (ps:ANY关键字表示满足其中任意一个条件。使用ANY关键字时,只要满足内层查询语句返回的结果中的任意一个,就可以通过该条件来执行外层查询语句。)
select books, row from tb_book where row>=ALL (select row from tb_row);(ps:ALL关键字表示满足所有条件。使用ALL关键字时,只有满足内层查询语句返回的所有结果,才可以执行外层查询语句。)
合并查询结果
合并查询结果是将多个SELECT语句的查询结果合并到一起。因为某种情况下,需要将几个SELECT语句查询出来的结果合并起来显示。合并查询结果使用UNION和UNION ALL关键字。UNION关键字是将所有的查询结果合并到一起,然后去除相同记录;而UNION ALL关键字则只是简单地将结果合并到一起。
select user from tb_book UNION select user from tb_login;
select user from tb_book UNION ALL select user from tb_login;
正则表达式查询
正则表达式是用某种模式去匹配一类字符串的一个方式。正则表达式的查询能力比通配字符的查询能力更强大,而且更加灵活。
在MySQL中,使用REGEXP关键字来匹配查询正则表达式。其基本形式如下:
字段名REGEXP'匹配方式'
“字段名”参数表示需要查询的字段名称;
“匹配方式”参数表示以哪种方式来进行匹配查询。
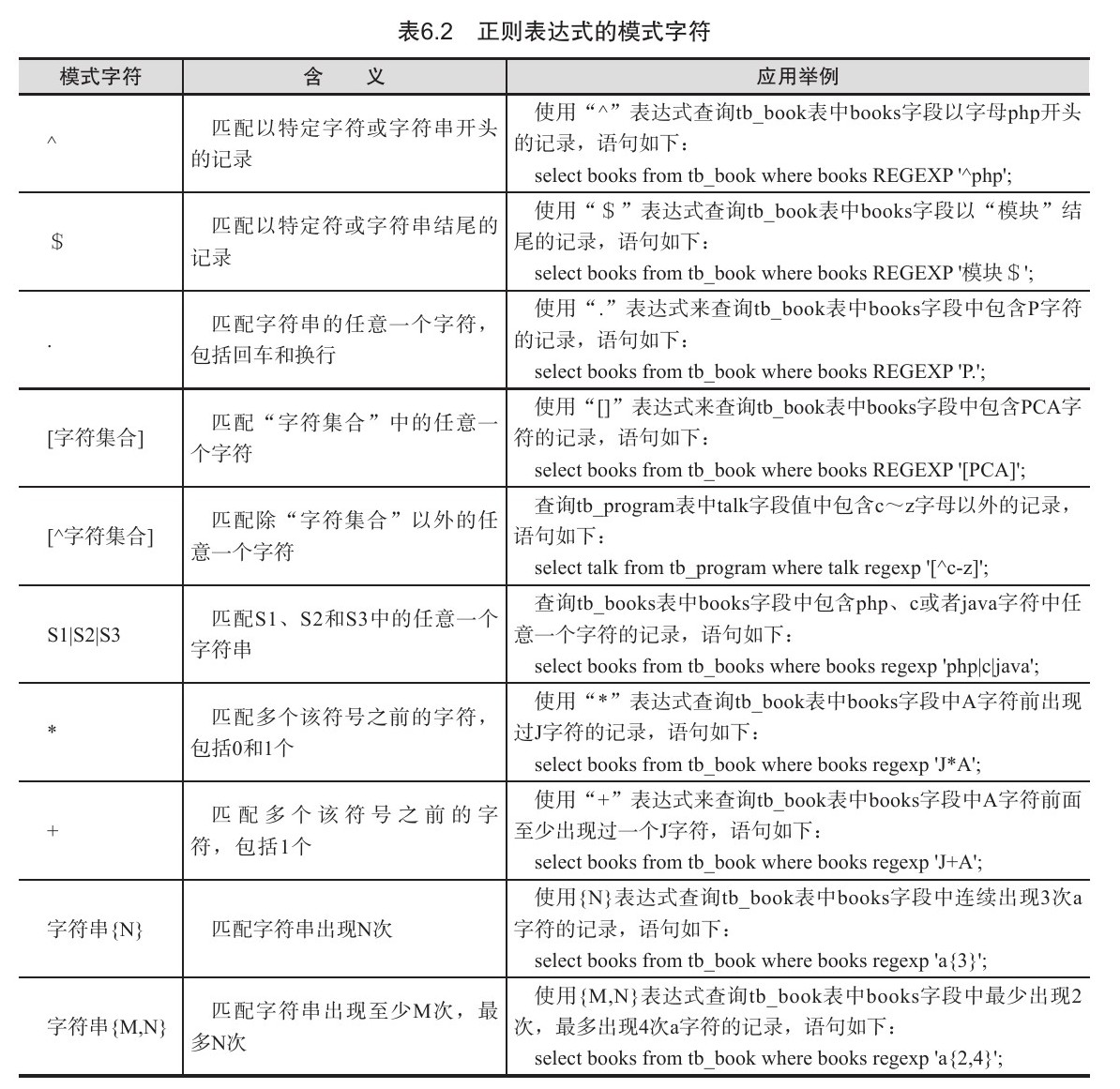
SELECT * FROM info WHERE name REGEXP '[ceo]';
SELECT * FROM info WHERE name REGEXP 'a*c';
SELECT * FROM info WHERE name REGEXP 'a+c';
MySql的数据查询的更多相关文章
- MySQL:数据查询
数据查询 一.基本查询语句 1.语法:写一行 select{*<字段列表>}//查询的字段,多个字段用逗号分开 from<表1>,<表2>…//数据表名 {//可选 ...
- mysql 大数据 查询方面的测试
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- SpringMVC+Mybatis实现的Mysql分页数据查询
周末这天手痒,正好没事干,想着写一个分页的例子出来给大家分享一下. 这个案例分前端和后台两部分,前端使用面向对象的方式写的,里面用到了一些回调函数和事件代理,有兴趣的朋友可以研究一下.后台的实现技术是 ...
- Python MySQL - 进行数据查询
#coding=utf-8 import mysql.connector import importlib import sys # reload(sys) # sys.setdefaultencod ...
- mysql重复数据查询
假设有表test mysql> select * from test; +----+------+------+ | id | name | sex | +----+------+------+ ...
- python之MySQL学习——数据查询
import pymysql as ps # 打开数据库连接 db = ps.connect(host='localhost', user='root', password='123456', dat ...
- Mysql重复数据查询置为空
前两天产品有个需求,相同的商品因为价格不同而分开展示,但是明细还是算一条明细,具体区分展示出商品的价格和数量信息,其他重复的商品信息要置空. 需求并不难,用程序代码循环处理就可以了.但是后面涉及到打印 ...
- 【nodejs】express框架+mysql后台数据查询
一 环境部署 1,首先安装nodejs,并配置好环境变量(看自己习惯), 2,安装Express npm install express -g //全局安装 npm install express-g ...
- MySQL大数据量分页查询
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
随机推荐
- Java Integer为代表的包装类
Java种的Integer是int的包装类型 1. Integer 是int的包装类型,数据类型是类,初值为null 2. 初始化时 int i = 1; Integer i = new Intege ...
- css 三彩loading
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> <title&g ...
- jsonp的使用记录
最近前端的同事说要写一个手机查看的html5页面,需要我提供数据. 这个很ok啊,立马写了个服务返回数据.但是对方调用不了,因为跨域了. 返回错误如下: Failed to load xxxxxx: ...
- Oracle彻底卸载
Oracle彻底卸载 卸载:oracle卸载1.删除注册表:打开注册表:regedit 打开路径: <找注册表 :开始->运行->regedit> HKEY_LOCAL_MAC ...
- docker : RabbitMQ ElasticSearch
docker 运行RabbitMQ容器 docker run -d -p 5672:5672 -p 15672:15672 --name 命名 CONTAINER ID 放出5672 / 156 ...
- cannot be resolved to a type (Java)
最近经常遇到cannot be resolved to a type (Java)报错,以下为在网上找到的解决方案: 1.先看看有没有引用相关jar包2.检查jar是否引用了多个相同的,或者多个jar ...
- C语言顺序结构和分支结构总结
1. 本章学习总结 1.1 思维导图 1.2 本章学习体会及代码量学习体会 1.2.1 学习体会 感觉学的内容比较基础,也是日后编程的基石.今后还应多加练习,能够更自如地运用,避免低级错误,一步步地提 ...
- S:List
描述 写一个程序完成以下命令:new id ——新建一个指定编号为id的序列(id<10000)add id num——向编号为id的序列加入整数nummerge id1 id2——合并序列id ...
- “全栈2019”Java第五十六章:多态与字段详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- luoguP3702 [SDOI2017]序列计数
https://www.luogu.org/problemnew/show/P3702 题目让我们在 $ [1, m] $ 从中选出 $ n $ 个数,当中要有 > $ 0 $ 个质数,和是 $ ...