(原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml
在Linear Regression部分出现了一些新的名词,这些名词在后续课程中会频繁出现:
| Cost Function | Linear Regression | Gradient Descent | Normal Equation | Feature Scaling | Mean normalization |
| 损失函数 | 线性回归 | 梯度下降 | 正规方程 | 特征归一化 | 均值标准化 |
Model Representation
- m: number of training examples
- x(i): input (features) of ith training example
- xj(i): value of feature j in ith training example
- y(i): “output” variable / “target” variable of ith training example
- n: number of features
- θ: parameters
- Hypothesis: hθ(x) = θ0 + θ1x1 + θ2x2 + … +θnxn
Cost Function
IDEA: Choose θso that hθ(x) is close to y for our training examples (x, y).
A.Linear Regression with One Variable Cost Function
Cost Function: 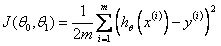
Goal: 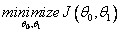
Contour Plot:
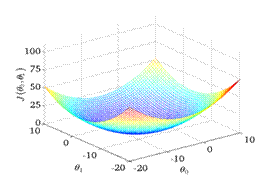
B.Linear Regression with Multiple Variable Cost Function
Cost Function: 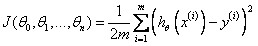
Goal: 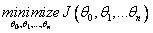
Gradient Descent
Outline

Gradient Descent Algorithm
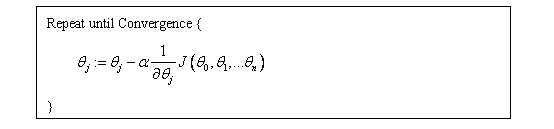
迭代过程收敛图可能如下:
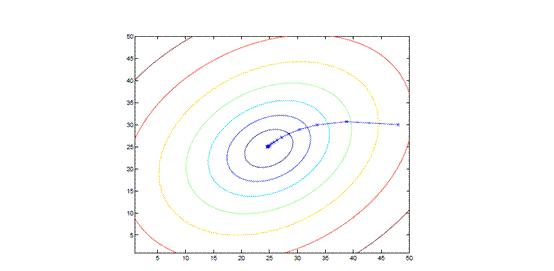
(此为等高线图,中间为最小值点,图中蓝色弧线为可能的收敛路径。)
Learning Rate α:
1) If α is too small, gradient descent can be slow to converge;
2) If α is too large, gradient descent may not decrease on every iteration or may not converge;
3) For sufficiently small α , J(θ) should decrease on every iteration;
Choose Learning Rate α: Debug, 0.001, 0.003, 0.006, 0.01, 0.03, 0.06, 0.1, 0.3, 0.6, 1.0;
“Batch” Gradient Descent: Each step of gradient descent uses all the training examples;
“Stochastic” gradient descent: Each step of gradient descent uses only one training examples.
Normal Equation
IDEA: Method to solve for θ analytically.
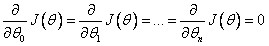 for every j, then
for every j, then 
Restriction: Normal Equation does not work when (XTX) is non-invertible.
PS: 当矩阵为满秩矩阵时,该矩阵可逆。列向量(feature)线性无关且行向量(样本)线性无关的个数大于列向量的个数(特征个数n).
Gradient Descent Algorithm VS. Normal Equation
Gradient Descent:
- Need to choose α;
- Needs many iterations;
- Works well even when n is large; (n > 1000 is appropriate)
Normal Equation:
- No need to choose α;
- Don’t need to iterate;
- Need to compute (XTX)-1 ;
- Slow if n is very large. (n < 1000 is OK)
Feature Scaling
IDEA: Make sure features are on a similar scale.
好处: 减少迭代次数,有利于快速收敛
Example: If we need to get every feature into approximately a -1 ≤ xi ≤ 1 range, feature values located in [-3, 3] or [-1/3, 1/3] fields are acceptable.
Mean normalization: 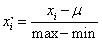
HOMEWORK
好了,既然看完了视频课程,就来做一下作业吧,下面是Linear Regression部分作业的核心代码:
1.computeCost.m/computeCostMulti.m
J=/(*m)*sum((theta'*X'-y').^2);
2.gradientDescent.m/gradientDescentMulti.m
h=X*theta-y;
v=X'*h;
v=v*alpha/m;
theta1=theta;
theta=theta-v;
(原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Linear Regression的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 3) Logistic Regression & Regularization
coursera上面Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 我曾经使用Logistic Regressio ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 10) Large Scale Machine Learning & Application Example
本栏目来源于Andrew NG老师讲解的Machine Learning课程,主要介绍大规模机器学习以及其应用.包括随机梯度下降法.维批量梯度下降法.梯度下降法的收敛.在线学习.map reduce以 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 8) Clustering & Dimensionality Reduction
本周主要介绍了聚类算法和特征降维方法,聚类算法包括K-means的相关概念.优化目标.聚类中心等内容:特征降维包括降维的缘由.算法描述.压缩重建等内容.coursera上面Andrew NG的Mach ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 7) Support Vector Machines
本栏目内容来源于Andrew NG老师讲解的SVM部分,包括SVM的优化目标.最大判定边界.核函数.SVM使用方法.多分类问题等,Machine learning课程地址为:https://www.c ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 9) Anomaly Detection&Recommender Systems
这部分内容来源于Andrew NG老师讲解的 machine learning课程,包括异常检测算法以及推荐系统设计.异常检测是一个非监督学习算法,用于发现系统中的异常数据.推荐系统在生活中也是随处可 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 4) Neural Networks Representation
Andrew NG的Machine learning课程地址为:https://www.coursera.org/course/ml 神经网络一直被认为是比较难懂的问题,NG将神经网络部分的课程分为了 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 5) Neural Networks Learning
本栏目内容来自Andrew NG老师的公开课:https://class.coursera.org/ml/class/index 一般而言, 人工神经网络与经典计算方法相比并非优越, 只有当常规方法解 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
随机推荐
- 制作Solaris系统的USB启动盘
制作方法: 1. wget http://192.168.2.5/surefiler-installer/2011-12-09/devel-2011.12.9.tgz 2. cd /root tar ...
- js中的true和false
1.false undefined.NaN.0.null和空字符串''均被视为false 2.true 除上述以外的其它情况一律被视作true
- Java常用开发思想与知识点小记(一)
1. 子类在覆盖父类的方法时,不能抛出比父类更多的异常(儿子不能比父亲干更多的坏事),所以只能捕捉异常,通常在web层捕获异常,给用户一个友好提示. 2.Java内存模型与并发编程三个特性 htt ...
- Python第三方库matplotlib(2D绘图库)入门与进阶
Matplotlib 一 简介: 二 相关文档: 三 入门与进阶案例 1- 简单图形绘制 2- figure的简单使用 3- 设置坐标轴 4- 设置legend图例 5- 添加注解和绘制点以及在图形上 ...
- GBK UTF-16 UTF-8 编码表
GBK UTF-16 UTF-8 ================== D2BB 4E00 E4 B8 80 一 B6A1 4E01 E4 B8 81 丁 C6DF 4E03 E4 ...
- C++转换构造函数和隐式转换函数 ~ 转载
原文地址: C++转换构造函数和隐式转换函数 用转换构造函数可以将一个指定类型的数据转换为类的对象.但是不能反过来将一个类的对象转换为一个其他类型的数据(例如将一个Complex类对象转换成doubl ...
- python中BeautifulSoup模块
BeautifulSoup模块是干嘛的? 答:通过html标签去快速匹配标签中的内容.效率相对比正则会好的多.效率跟xpath模块应该差不多. 一:解析器: BeautifulSoup(html,&q ...
- fork与printf缓冲问题
printf输出条件: (1) 调用fflush: (2) 缓冲区满了: (3) 遇到\n \r这些字符 (4) 遇到scanf这些要取缓冲区的: (5) 线程或者进程退出: fork之后会拷贝父进程 ...
- shell 智能获取历史记录功能
vim ~/.inputrc 文件内容: "\e[A": history-search-backward"\e[B": history-search-forwa ...
- hadoop中setOutputKeyClass和setOutputValueClass里类型
初学mapreduce programing,纠结一天的问题如下: job.setOutputKeyClass和job.setOutputValueClas在默认情况下是同时设置map阶段和reduc ...