【Hadoop报错】The directory item limit is exceeded: limit=1048576 items=1048576
问题描述:
调度系统执行hive任务失败,一直执行失败,报错如下:
java.io.IOException: java.net.ConnectException: Call From #HostName/#IP to #HostName:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
Caused by: java.net.ConnectException: Call From #HostName/#IP to #HostName:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
CONSOLE# Ended Job = job_1638255473937_0568 with exception 'java.io.IOException(java.net.ConnectException: Call From #HostName/#IP to #HostName:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused)
CONSOLE# FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. java.net.ConnectException: Call From #HostName/#IP to #HostName:10020 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
这个信息还看不出具体的问题所在,查看服务器上所有的日志,也没有看出问题,最后查看yarn的日志,看出问题所在。
根据调度系统,获取到ApplicationId:application_1638255473937_0568 , 然后从hdfs上查看对应的日志信息。
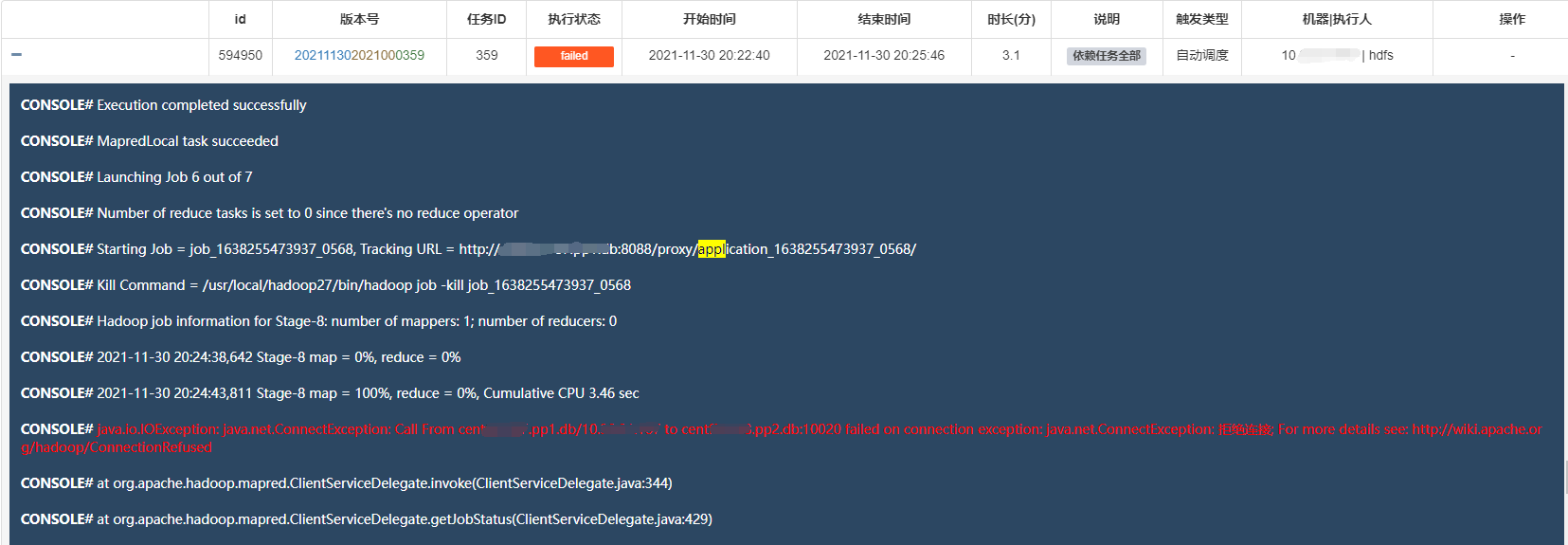
查看yarn日志信息:
[hdfs@centos hadoop27]$ yarn logs -applicationId application_1638255473937_0568
关键报错信息:
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.hdfs.protocol.FSLimitException$MaxDirectoryItemsExceededException): The directory item limit of /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs is exceeded: limit=1048576 items=1048576

报错原因:
hadoop单个目录下文件超1048576个,默认limit限制数为1048576,所以要调大limit限制数。
解决方法1:
hdfs-site.xml配置文件添加配置参数:dfs.namenode.fs-limits.max-directory-items ,调大参数值。

将配置文件推送到hadoop集群所有节点,重启Hadoop服务。
解决方法2:
如果不方便修改配置重启hadoop集群服务。可以先删除该目录:/tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
然后重建目录即可。
hadoop fs -rm -r /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
hadoop fs -mkdir /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
造成这个目录文件数超上限,本质原因还是hadoop集群之前没有开启jobhistory server,没有清除历史job日志信息导致的。
参考文章:http://www.tracefact.net/tech/079.html
扩展信息:
一:如何查看yarn日志存放目录及日志详细信息
1:通过history server UI界面查看。(我这里是http://IP:8801/jobhistory)

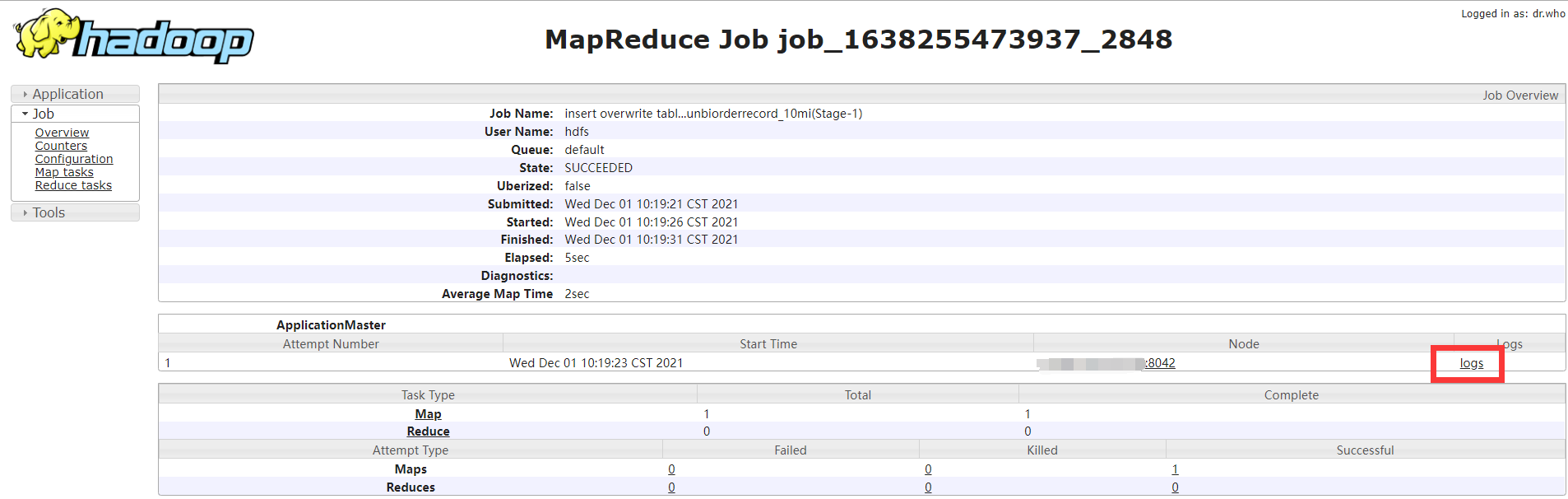
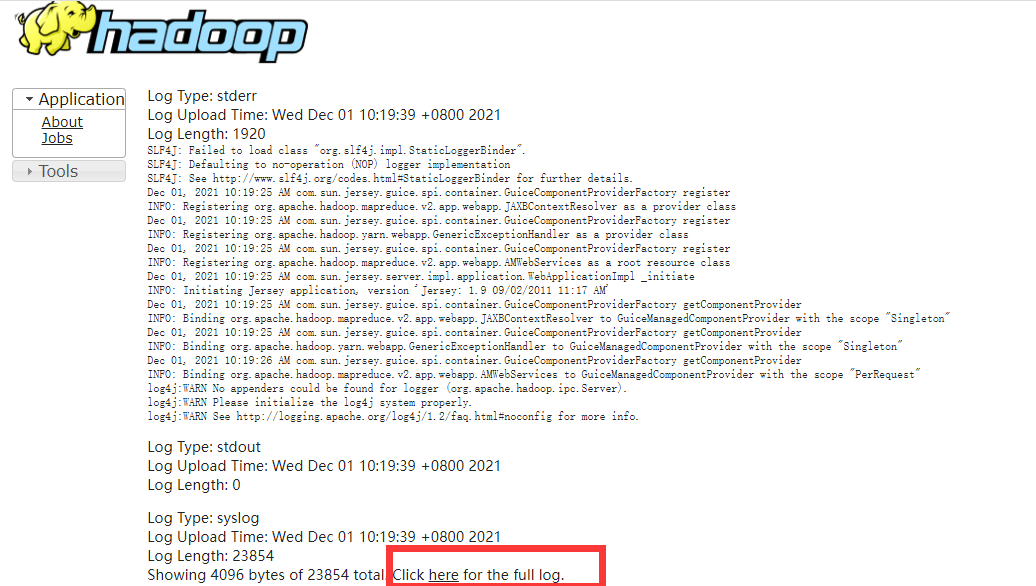
2:通过yarn命令查看(用户要和提交任务的用户一致)
2.1: yarn application -list -appStates ALL(这个不显示时间信息)
2.2: yarn logs -applicationId application_1638255473937_0568
3:直接查看hdfs路径的log (是存放在hdfs目录上的,不是存放在centos系统的自定义日志目录上)
3.1: 查看yarn-site.xml文件,确认log配置目录。
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/data1/hadoop27/logs</value>
</property>
3.2: 查看日志文件信息
[hdfs@centos hadoop]$ hdfs dfs -ls /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568
Found 1 items
-rw-r----- 2 hdfs hdfs 66188 2021-11-30 20:24 /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568/centos.pp1.db_46654
3.3: 查看日志详细信息
3.3.1: yarn logs -applicationId application_1638255473937_0568 (同2)
3.3.2: hdfs dfs -cat /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568/centos.pp1.db_46654 ## 通过-cat查看
3.3.3: hdfs dfs -cat /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568/centos.pp1.db_46654 > tmp.log ## 通过-cat把内容存到当前目录的tmp.log中。
3.3.4: hdfs dfs -get /data1/hadoop27/logs/hdfs/logs/application_1638255473937_0568/centos.pp1.db_46654 ## 通过get把hdfs文件下载到当前啊目录下,然后查看。
二: hdfs操作命令:
1.1: 查看hdfs的指定目录下有多少个文件夹和文件。
[hdfs@centos hadoop]$ hadoop fs -count /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
1 1048576 3253261451467 /tmp/hadoop-yarn/staging/history/done_intermediate/hdfs
第一个数值1表示该目录下有1个文件夹。
第二个数值1048576表示该目录下有1个文件。
第三个数值3253261451467表示该目录下所有文件总大小。
【Hadoop报错】The directory item limit is exceeded: limit=1048576 items=1048576的更多相关文章
- eclipse连接远程Hadoop报错,Caused by: java.io.IOException: 远程主机强迫关闭了一个现有的连接。
eclipse连接远程Hadoop报错,Caused by: java.io.IOException: 远程主机强迫关闭了一个现有的连接.全部报错信息如下: Exception in thread & ...
- 解决sqoop报错Invalid number; item = ITEM_UNICODE
报错栈: java.sql.SQLException: Invalid number; item = ITEM_UNICODE at com.intersys.jdbc.SysList.getInt( ...
- hadoop报错WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
19/06/14 10:44:58 WARN common.Util: Path /opt/hadoopdata/hdfs/name should be specified as a URI in c ...
- 解决windows下Eclipse连接远程Hadoop报错
Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.N ...
- hadoop报错:java.io.IOException(java.net.ConnectException: Call From xxx/xxx to xxx:10020 failed on connection exception: java.net.ConnectException: 拒绝连接
任务一直报错 现象比较奇怪,部分任务可以正常跑,部分问题报错 报错信息如下: Ended Job = job_1527476268558_132947 with exception 'java.io. ...
- hadoop报错:could only be replicated to 0 nodes, instead of 1
错误 [root@hadoop test]# hadoop jar hadoop.jarcom.hadoop.hdfs.CopyToHDFS 14/01/26 10:20:00 WARN hdfs.D ...
- hadoop报错
19/11/24 08:29:08 INFO qlh.MyMapreduce: ================this is job================= 19/11/24 08:29: ...
- ubuntu环境下重启mysql服务报错“No directory, logging in with HOME=-”
前提:使用系统的环境 3.13.0-24-generic mysql的版本:5.6.33 错误描述: 首先用mysqld_safe启动报错如下: root@zabbix-forFunction:~# ...
- hadoop报错:hdfs.DFSClient: Exception in createBlockOutputStream
hadoop跑任务搞的好好的,后来把hadoop-dir移了一个位置,结果报错: java.io.EOFException: Premature EOF: no length prefix avail ...
- HADOOP报错Incompatible namespaceIDs
出现这个问题的原因是因为namespaceIDs导致的 解决方案1<推荐> 1. 进入链接不上的从机 stop-all.sh关闭hadoop 2. 编辑namespaceID,路径是< ...
随机推荐
- 【Python爬虫案例】用python爬1000条哔哩哔哩搜索结果
目录 一.爬取目标 二.讲解代码 三.同步讲解视频 四.完整源码 一.爬取目标 大家好,我是 @马哥python说 ,一名10年程序猿. 今天分享一期爬虫的案例,用python爬哔哩哔哩的搜索结果,也 ...
- 使用自定义lua解析管理器调用lua脚本中的table
[5] 使用自定义lua解析管理器调用table 访问数组类型的table CallLuaEntrance测试脚本中内容: //------------------------------------ ...
- 4G EPS 中的各种唯一标识
目录 文章目录 目录 电信运营商的唯一标识:PLMN.MCC 与 MNC 移动用户的唯一标识:IMSI.MSIN 与 MSISDN/MDN 移动用户的唯一临时标识:TMSI.GUTI 与 GUMMEI ...
- sass @extend(继承)指令详解
在设计网页的时候常常遇到这种情况:一个元素使用的样式与另一个元素完全相同,但又添加了额外的样式. 通常会在 HTML 中给元素定义两个 class,一个通用样式,一个特殊样式. 普通CSS的实现 接下 ...
- 为什么下载程序的时候会提示win-amd64.exe
- Django 视图views的基本使用
在 Django 中,视图函数是一个 Python 函数或者类,开发者主要通过编写视图函数来实现业务逻辑.视图函数首先接受来自浏览器或者客户端的请求,并最终返回响应,视图函数返回的响应可以是 HTML ...
- 鸿蒙HarmonyOS实战-Stage模型(线程模型)
前言 线程是计算机中的一种执行单元,是操作系统进行调度的最小单位.它是进程中的实际运行单位,每个进程可以包含多个线程.线程可以理解为进程中的一个执行流,它独立运行,拥有独立的栈和寄存器,但共享进程的资 ...
- mysql存储地理信息的方法
MySQL 存储地理信息通常使用 GEOMETRY 数据类型或其子类型(如 POINT, LINESTRING, POLYGON 等).为了支持这些数据类型,MySQL 提供了 SPATIAL 索引, ...
- Leetcode-916. Word Subsets-(Medium)
一.问题描述 We are given two arrays A and B of words. Each word is a string of lowercase letters. Now, s ...
- Cmockery学习
什么是cmockery? 是一个轻量级的C语言单元测试框架 什么是单元测试? 单元测试就是测试一个系统的最小实现单元,往往是函数 示例解析 #include <stdarg.h> #inc ...