Python——第二章:文件操作
文件操作
1. 找到这个文件. 双击打开它
open(文件路径, mode="", encoding="")
文件路径:
1. 绝对路径
d:/test/xxxx.txt
2. 相对路径
相对于当前你的程序所在的文件夹
../ 上一层文件夹
mode:
r : read 读取
w : write 写
a : append 追加写入
b : 读写的是非文本文件 -> bytes
with: 上下文, 不需要手动去关闭一个文件
修改文件:
1. 从源文件中读取内容.
2. 在内存中进行调整(修改)
3. 把修改后的内容写入新文件中
4. 删除源文件. 将新文件重命名成源文件
5. 最后要执行f.close()——操作完成后,不要忘记关闭文件!
在Python中,当你打开一个文件进行读写操作时,操作系统会为这个文件分配一些资源(如内存空间)。如果文件使用完毕后不及时关闭,可能会导致资源浪费,甚至出现数据错误或丢失的情况。
因此,执行f.close()是为了在完成文件操作后及时关闭文件,释放系统资源,并确保数据的完整性和安全性。这是一种良好的编程习惯,也是Python中推荐的文件操作方式。
使用with语句可以更方便地处理文件关闭问题。with语句会自动管理文件对象的生命周期,在代码块执行完毕后自动关闭文件,无需手动调用f.close()方法。但是,在某些特殊情况下,比如需要提前结束文件操作时,手动调用f.close()也是可以的。打开文件:open("文件路径", mode="r", encoding="utf-8")
文件路径分为:绝对路径 or 相对路径:
绝对路径:
open ("/opt/db/abc.txt", mode="r", encoding="utf-8")相对路径:
#和程序同层级目录
open ("国产自拍.txt", mode="r", encoding="utf-8")
#在本程序上一层目录下的其他目录
open ("../葫芦娃.txt", mode="r", encoding="utf-8")
#上一层目录下的/代码/目录
open ("../01_初识python/代码/倚天屠龙记.txt", mode="r", encoding="utf-8")完整的打开格式open("国产自拍.txt", mode="r", encoding="utf-8")
f = open("国产自拍.txt", mode="r", encoding="utf-8")
content = f.read() # 全部读取
print(content)
f.close()
#运行结果
葫芦娃
葫芦娃
一根藤上七朵花
风吹雨打都不怕
啦啦啦啦啦.........*注意事项
- 在操作文本文档时,
encoding="utf-8"这条代码可以不写,但是建议写上,因为不写的时候根据你的操作系统默认标记.(MAC操作系统默认是utf-8,Windows中文版本默认是GBK) mode="r"可以被缩写成"r"如:open("国产自拍.txt", "r", encoding="utf-8")- 在读写非文本文件的时候要加上b,比如读取读取图片,非文本
mode="rb",并且图片在计算机里是二进制存储的(01010110),不能带encoding="utf-8"编码参数。 - 执行
f.read()或f.write()这类操作之前,必须先打开文件,要执行open - 执行
f.close()后文件关闭,也不能再执行读or写操作 - 使用with用法后,文件会自动关闭,with外也不能再执行读写操作,还需要执行open
- 在Python中,双引号
""和单引号''都用于表示字符串,它们在大多数情况下是可以互相替代的,没有本质的区别。你可以根据个人偏好或者特定的语境选择其中之一。
在不指定encoding参数的情况下,open函数会使用默认的系统编码。最好还是明确指定encoding="utf-8"参数,以确保正确处理文本文件。
- Windows 10英文版系统,它的默认编码通常是CP1252(Windows-1252)
- Windows 10中文版系统,它的默认编码通常是GBK(CP936)
- Windows 10台版本系统,它的默认编码通常是Big5-HKSCS 编码(Big5 字符集的扩展)
- MAC操作系统默认是UTF-8(中文&英文)
读取文件:r模式mode ="r"
执行读取的几种方法:
content = f.readable() 可以读取到内容content = f.read() 全部读取content = f.readlines() 把所有行都打印出来content = f.readline() 一行一行读取content = f.readline().strip() 去掉字符串左右两端的空白:空格, 换行, 制表符


为了方便解释,我们先执行content = f.readlines()这个操作是把原文的每一行都拿出来,然后放入列表里.
f = open("国产自拍.txt", mode="r", encoding="utf-8")
content = f.readlines() #把所有行都打印出来
print(content)
f.close()
#执行结果
['葫芦娃\n', '葫芦娃\n', '一根藤上七朵花\n', '风吹雨打都不怕\n', '啦啦啦啦啦.........']对比原文和content = f.readlines()我们可以看到,其实每个字段后面都是跟着\n的,\n其实就是换行。
对比来看content = f.readline() 这是一行一行读取的操作命令,并且每执行一次,程序的指针会自动换到下一行
f = open("国产自拍.txt", mode="r", encoding="utf-8")
line = f.readline()
print(line)
line = f.readline()
print(line)
line = f.readline()
print(line)
f.close()
#运行结果
葫芦娃
葫芦娃
一根藤上七朵花*这里需要解释一下,文本中本身就存在\n换行。再加上python程序每执行一次print(*)命令后,内部会默认执行一次end='\n'换行,因此会出现多1次换行的现象。

为此,需要增加content = f.readline().strip()命令来去掉字符串左右两端的空白。包括:空格,换行,制表符。这里程序本身的换行,是靠print(*)命令内部实现的。
f = open("国产自拍.txt", mode="r", encoding="utf-8")
line = f.readline().strip() # 去掉字符串左右两端的空白,包括(空格, 换行, 制表符)
print(line)
line = f.readline().strip()
print(line)
line = f.readline().strip()
print(line)
f.close()
#运行结果
葫芦娃
葫芦娃
一根藤上七朵花存在这些读取方式的区别是因为,如果文件足够大(10GB),那会严重影响程序的内存占用率,
因此这两种操作方式,都可能使内存占满
content = f.read() 全部读取content = f.readlines() 把所有行都打印出来
为此,应采取readline()的操作方式去使用,会更加安全
content = f.readline() 一行一行读取content = f.readline().strip() 去掉字符串左右两端的空白:空格, 换行, 制表符
但是为了便捷打印多行,python允许把f (open操作)加入循环
*最重要的一种文本读取方式(必须掌握)
f = open("国产自拍.txt", mode="r", encoding="utf-8")
for line in f: # 从f中读取到每一行数据
print(line.strip()) #必须加入.strip,不然会多换行
f.close() # 不要忘记关闭文件!这是一种很公用的,大多数的通用读取方案.
写入文件:w模式mode ="w"
w模式下. 如果文件不存在. 自动的创建一个文件
w模式下. 每一次open都会清空掉文件中的内容
f = open("嫩模.txt", mode="w", encoding="utf-8")
f.write("胡辣汤")
f.close() # 每次操作之后养成好习惯.要关闭链接准备一个列表.要求把列表中的每一项内容. 写入到文件中
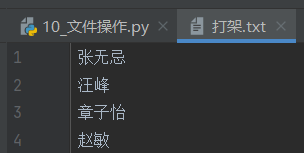
lst = ['张无忌', "汪峰", "章子怡", "赵敏"]
f = open("打架.txt", mode="w", encoding="utf-8") # 大多数情况下要把open写循环外面
for item in lst:
f.write(item)
f.write("\n")
f.close() # 不要忘记关闭文件!如果不加入"\n",就不会换行
写入文件:a模式mode ="a"——在末尾追加
f = open("打架.txt", mode="a", encoding="utf-8")
f.write("你好厉害")
f.close() # 不要忘记关闭文件!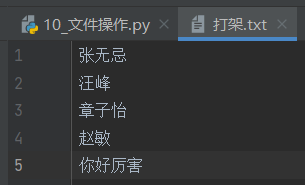
with用法: with open() as *:
它是一种上下文管理器,能够确保在这部分代码块执行完成后文件会被正确关闭,即便是后面的脚本发生了异常也没关系。with语句会在代码块执行前自动打开文件,并在代码块执行完毕后自动关闭文件。这样可以确保文件在使用完毕后被及时关闭,是一种更安全的文件处理方式。
不需要手动去关闭一个文件,但是with后要以冒号结束,并且下一行需要缩进排版,缩进的命令代表在with内部。如果命令和with并排,代表在with动作外。with执行完成后,文件会自动被关闭。
总之,推荐使用 with 语句,因为它能够提供更好的代码健壮性,确保资源在正确的时候被释放。
使用with语句的版本:
with open("国产自拍.txt", mode="r", encoding="utf-8") as f:
for line in f:
print(line.strip())这种写法就等效于使用open和close的版本:
f= open("国产自拍.txt", mode="r", encoding="utf-8")
for line in f:
print(line.strip())
f.close()这个版本手动调用了f.close()来关闭文件。虽然这样也可以正常工作,但是如果在文件操作过程中发生异常,可能导致文件没有被关闭,因为close语句可能不会被执行。因此,使用with语句可以更好地确保文件的正确关闭,尤其是在处理文件时可能发生异常的情况下。
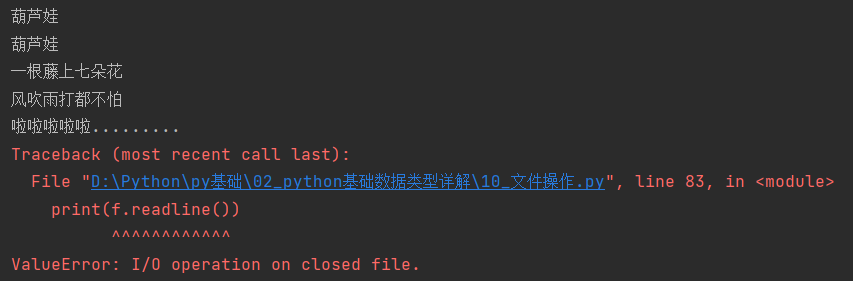
验证实验:在with外增加f.readline()这些读or写的操作,都会报错
with open("国产自拍.txt", mode="r", encoding="utf-8") as f:
for line in f:
print(line.strip())
print(f.readline())提示ValueError: I/O operation on closed file.文件关闭后不可以I/O输出
想要读取图片,在读写非文本文件的时候要加上b,比如读取非文本mode="rb",并且图片在计算机里是二进制存储的(01010110),不能带encoding="utf-8"编码参数。
with open("胡一菲.jpeg", mode="rb") as f:
for line in f:
print(line)想要完成文件的复制: 从源文件中读取内容. 写入到新路径去with open("源文件", mode="rb") as f1, open("新路径", mode="wb") as f2:
with open("胡一菲.jpeg", mode="rb") as f1, \
open("../01_初识python/胡二飞.jpeg", mode="wb") as f2:
for line in f1:
f2.write(line)这里需要注意,因为一行代码太长,刻意使用到了\符号,\代表转行(未完待续),实际代码等效为with open("胡一菲.jpeg", mode="rb") as f1, open("../01_初识python/胡二飞.jpeg", mode="wb") as f2:
文件修改:
第1步,把文件中开头以"周" -> "张",然后存入临时副本中。
with open("人名单.txt", mode="r", encoding="utf-8") as f1, \
open("人名单_副本.txt", mode="w", encoding="utf-8") as f2:
for line in f1:
line = line.strip() # 去掉换行/n
if line.startswith("周"):
line = line.replace("周", "张") # 字符串操作不可变,需要重新赋值
f2.write(line)
f2.write("\n")第2步,删除原始文件。把临时副本中的文件替换为原始文件。
import os # python要调用os操作系统相关的模块,要引用os
os.remove("人名单.txt") # 删除源文件
os.rename("人名单_副本.txt", "人名单.txt") # 把副本文件重命名成源文件运行此命令时,程序瞬间执行完成,让用户感知不到整改操作过程,以为是对源文件进行的操作替换.
为此我们可以加入时间概念,让程序等待3秒再执行,格式为:
import time # python要调用和时间相关的模块,要引用time
time.sleep(3) # 让程序休眠3秒钟因此整段代码应为:
import os
import time
with open("人名单.txt", mode="r", encoding="utf-8") as f1, \
open("人名单_副本.txt", mode="w", encoding="utf-8") as f2:
for line in f1:
line = line.strip() # 去掉换行
if line.startswith("周"):
line = line.replace("周", "张") # 重新赋值才可以替换
f2.write(line)
f2.write("\n")
time.sleep(3) # 让程序休眠3秒钟
os.remove("人名单.txt") # 删除源文件
time.sleep(3) # 让程序休眠3秒钟
os.rename("人名单_副本.txt", "人名单.txt") # 把副本文件重命名成源文件Python——第二章:文件操作的更多相关文章
- 简学Python第二章__巧学数据结构文件操作
#cnblogs_post_body h2 { background: linear-gradient(to bottom, #18c0ff 0%,#0c7eff 100%); color: #fff ...
- python os&shutil 文件操作
python os&shutil 文件操作 # os 模块 os.sep 可以取代操作系统特定的路径分隔符.windows下为 '\\' os.name 字符串指示你正在使用的平台.比如对于W ...
- python 历险记(三)— python 的常用文件操作
目录 前言 文件 什么是文件? 如何在 python 中打开文件? python 文件对象有哪些属性? 如何读文件? read() readline() 如何写文件? 如何操作文件和目录? 强大的 o ...
- Python的高级文件操作(shutil模块)
Python的高级文件操作(shutil模块) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 如果让我们用python的文件处理来进行文件拷贝,想必很多小伙伴的思路是:使用打开2个 ...
- Python入门篇-文件操作
Python入门篇-文件操作 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.文件IO常用操作 open:打开 read:读取 write:写入 close:关闭 readlin ...
- python基础篇(文件操作)
Python基础篇(文件操作) 一.初始文件操作 使用python来读写文件是非常简单的操作. 我们使用open()函数来打开一个文件, 获取到文件句柄. 然后通过文件句柄就可以进行各种各样的操作了. ...
- Python之常用文件操作
Python之常用文件操作
- Python学习笔记 -- 第六章 文件操作
I/O编程 在磁盘上读写文件的功能都是由操作系统提供的,现代操作系统不允许普通的程序直接操作磁盘,所以,读写文件就是请求操作系统打开一个文件对象(通常称为文件描述符),然后,通过操作系统提供的接口从这 ...
- 2 python第三章文件操作
1.三元运算 三元运算又称三目运算,是对简单的条件语句的简写,如: 简单条件语句: if 条件成立: val = 1 else: val = 2 改成三元运算: val = 1 if 条件成立 els ...
- 百万年薪python之路 -- 文件操作
1.文件操作: f = open("zcy.txt" , mode="r" , encoding="UTF-8") open() 打开 第一 ...
随机推荐
- 解决 wg-quick 在 Mac 上 bash 3 无法运行的问题
问题原因 我可以理解,开发人员不想使用苹果使用的旧bash v3.但从用户的帖子来看,安装一个较新的bash并不那么好 所以我看了wireguard的wg-quick.需要支持的唯一变化,两个bash ...
- MongoDB 中使用 explain 分析创建的索引是否合理
MongoDB 中如何使用 explain 分析查询计划 前言 查询计划 explain explain 1.queryPlanner 2.executionStats 3.allPlansExecu ...
- 四千行代码写的桌面操作系统GrapeOS完整代码开源了
简介 学习操作系统原理最好的方法是自己写一个简单的操作系统. GrapeOS是一个非常简单的x86多任务桌面操作系统,源代码只有四千行,非常适合用来学习操作系统原理. 源码地址:https://git ...
- 使用mtrace追踪JVM堆外内存泄露
原创:扣钉日记(微信公众号ID:codelogs),欢迎分享,非公众号转载保留此声明. 简介 在上篇文章中,介绍了使用tcmalloc或jemalloc定位native内存泄露的方法,但使用这个方法相 ...
- 8月Node服务的3场事故
有句话叫每一起严重事故的背后,必然有 29 次轻微事故和 300 起未遂先兆以及 1000 起事故隐患. 而我最近更是碰到了 3 起比较严重的线上事故,都是大意惹的祸. 一.数据库锁死 第一起事故发生 ...
- VS Code SSH
VS Code SSH 连接需要下载 VS Code Server,这是因为 VS Code Server 是在远程服务器上运行的,而不是在本地计算机上运行的.每次连接到不同的远程服务器时,都需要下载 ...
- [GXYCTF 2019]Ping Ping Ping
题目就是ping,而且这还有一个查询窗口,就随便查询试试 ping了一下本地,发现没有什么很大的作用,给出了提示是php可以执行系统函数这就感到神奇了,就还是上网搜了搜 发现可以在查询IP后面进行拼接 ...
- log4j2同步日志引发的性能问题
1 问题回顾 1.1 问题描述 在项目的性能测试中,相关的接口的随着并发数增加,接口的响应时间变长,接口吞吐不再增长,应用的CPU使用率较高. 1.2 分析思路 谁导致的CPU较高,阻塞接口TPS的增 ...
- 轻巧的批量图片压缩工具imgfast
现在的手机拍照动辄2M3M,还有7M8m的,如果要把这些文件上传到网上应用,浪费网络,占用资源 所以2022年中秋写了这个小工具,可以批量进行图片文件压缩,支持jpg和png. 文件下载链接https ...
- 给wordpress后台侧栏菜单添加自定义字段的方法
我们在使用wordpress做网站的时候,难免有一些需要在后台设置侧栏菜单下添加自定义字段的情况.下面就简单说说一下,如何在后台设置侧栏菜单下添加自定义字段? 在这里我们主要是使用wordpress的 ...