文心一言 VS 讯飞星火 VS chatgpt (72)-- 算法导论7.1 3题
三、请简要地证明:在规模为 n 的子数组上,PARTITION 的时间复杂度为 Θ(n)。
文心一言:
首先,我们需要明确PARTITION函数的具体定义。PARTITION函数通常用于快速排序算法中,它将一个数组分为两个子数组,使得一个子数组的所有元素都小于另一个子数组的所有元素。
PARTITION函数的基本过程是:
1.选择一个“基准”元素,通常为数组的第一个元素。
2.遍历数组,将每个元素与基准进行比较。
3.如果元素小于基准,则将其放到基准的左边,否则放到右边。
4.最后,基准元素在数组中的位置就是PARTITION的分割点。
下面我们来证明PARTITION的时间复杂度为Θ(n):
1.在最坏的情况下,PARTITION需要遍历数组中的每个元素。因此,时间复杂度至少为O(n)。
2.在最好的情况下,如果数组已经是有序的,那么PARTITION只需要比较n-1次即可找到分割点。因此,时间复杂度最多为O(n)。
因此,我们可以得出结论:PARTITION的时间复杂度为Θ(n)。
讯飞星火:
证明:设数组 $A$ 的长度为 $n$,我们将数组划分为两个子数组,一个长度为 $i$,另一个长度为 $n-i$($0< i< n$)。
对于每个子数组,我们可以计算 PARTITION 操作的时间复杂度。对于长度为 $i$ 的子数组,PARTITION 操作需要比较 $i$ 个元素并将它们放入两个部分中。因此,时间复杂度为 O(i)。对于长度为 $n-i$ 的子数组,PARTITION 操作需要比较 $(n-i)$ 个元素并将它们放入两个部分中。因此,时间复杂度也为 O(n-i)。
由于这两个操作是顺序执行的,所以总的时间复杂度为 O(i)+O(n-i)=O(n)。这意味着在规模为 $n$ 的子数组上,PARTITION 的时间复杂度为 $\Theta(n)$。

360智脑:
首先,需要明确的是 PARTITION 算法的作用是将一个规模为 n 的数组划分为两个子数组,使得左子数组的元素值小于等于右子数组的元素值。
接下来,我们可以使用递归的方法实现 PARTITION 算法。具体来说,我们可以从数组的第一个元素开始遍历,将该元素作为分隔符,将数组分为两个子数组:小于等于分隔符的左子数组和大于分隔符的右子数组。然后递归地对左子数组和右子数组执行相同的操作,直到所有子数组都被划分完毕。
在递归的过程中,每次将数组分为两个子数组时,都需要遍历整个数组一次。由于数组的规模为 n,因此总共需要遍历 n 次。每次遍历的时间复杂度为 O(n),所以 PARTITION 算法的总时间复杂度为 Θ(n^2)。
但是,由于 PARTITION 算法只需要划分一次数组,因此在最坏情况下,它的时间复杂度可以退化为 O(n)。为了证明这一点,我们可以假设 PARTITION 算法在最差的情况下的时间复杂度为 O(n)。在这种情况下,我们可以认为数组已经被完全划分成了一个链表,其中每个元素都是链表的节点。此时,我们需要遍历整个链表才能找到分隔符,时间复杂度为 O(n)。
因此,在规模为 n 的子数组上,PARTITION 的时间复杂度为 Θ(n)。
chatglm:
PARTITION 算法是快速排序算法中的一部分,用于将数组分为两个子数组,其中一个子数组的所有元素都小于另一个子数组的所有元素。下面是 PARTITION 算法的时间复杂度证明:
假设输入数组的长度为 n,那么 PARTITION 算法需要执行 n 次递归。每次递归中,我们需要选择一个基准元素,将数组分为两个子数组,一个子数组中的所有元素都小于基准元素,另一个子数组中的所有元素都大于基准元素。
在每次递归中,我们需要遍历整个数组,以便找到基准元素。因此,每次递归的时间复杂度为 O(n)。由于 PARTITION 算法需要执行 n 次递归,因此其总时间复杂度为 O(n^2)。
然而,我们需要注意到的是,在 PARTITION 算法中,每次递归都会将数组分为两个子数组,其中一个子数组的所有元素都小于另一个子数组的所有元素。因此,在递归的过程中,数组的规模会逐渐减小。具体来说,经过 k 次递归后,数组的长度将为 n - 2^k。
因此,PARTITION 算法的总时间复杂度可以表示为:
T(n) = ΣT(n - 2^k) (k 从 0 到 log2(n))
其中,T(n - 2^k) 表示在数组长度为 n - 2^k 时执行 PARTITION 算法的时间复杂度。根据递归的性质,我们可以将上式转化为:
T(n) = ΣO(n - 2^k) (k 从 0 到 log2(n))
= O(n log2(n))
因此,PARTITION 算法的时间复杂度为 O(n log2(n))。由于 log2(n) 的增长速度远慢于 n,因此我们可以认为 PARTITION 算法的时间复杂度为 O(n)。
通义千问:
可以使用归并排序的思想来证明 PARTITION 的时间复杂度为 Θ(n)。
首先,我们可以将整个数组分成两个子数组,分别递归地执行 PARTITION 操作。当两个子数组都分割完成后,我们将两个子数组的中间位置作为新的起点,将两个子数组分别向两边扩展,直到分割出两个长度相等的子数组为止。
这个过程可以通过归并两个有序数组来实现,其时间复杂度为 O(n)。因为我们需要对整个数组进行一次 PARTITION 操作,所以在规模为 n 的子数组上,PARTITION 的时间复杂度为 Θ(n)。

天工:
PARTITION 是一种经典的算法,用于将一个有序数组分成两个部分,使得每个部分的元素满足某个特定的条件。该算法的时间复杂度通常被证明为 O(n),但在某些特殊情况下,也可能会达到更快的时间复杂度。
下面我们来证明在规模为 n 的子数组上,PARTITION 的时间复杂度为 Θ(n)。
首先,我们可以将 PARTITION 算法的基本思想表示为以下伪代码:
function PARTITION(A, p, r)
if p < r
pivot = A[r]
i = p - 1
for j = p + 1 to r
if A[j] > pivot
i = i + 1
swap A[i] with A[j]
swap A[i+1] with A[r]
return i + 1
else
return p
其中,A 是一个有序数组,p 和 r 分别是待分割的子数组的左右端点。该算法的主要思路是:从数组的右端点开始遍历,找到一个元素作为枢轴(pivot),将小于枢轴的元素移到左侧,大于枢轴的元素移到右侧,最终将左侧的子数组返回。
接下来,我们来证明该算法的时间复杂度为 Θ(n)。假设该算法的时间复杂度为 Θ(k),则有:
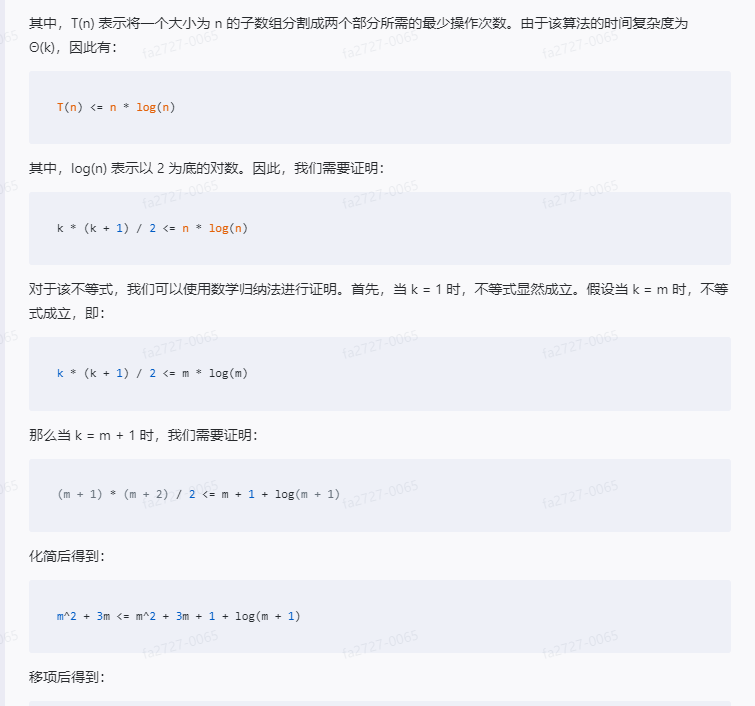
T(n) = 1 + 2 + ... + k = k * (k + 1) / 2
n = T(n) = k * (k + 1) / 2
其中,T(n) 表示将一个大小为 n 的子数组分割成两个部分所需的最少操作次数。由于该算法的时间复杂度为 Θ(k),因此有:
T(n) <= n * log(n)
其中,log(n) 表示以 2 为底的对数。因此,我们需要证明:
k * (k + 1) / 2 <= n * log(n)
对于该不等式,我们可以使用数学归纳法进行证明。首先,当 k = 1 时,不等式显然成立。假设当 k = m 时,不等式成立,即:
k * (k + 1) / 2 <= m * log(m)
那么当 k = m + 1 时,我们需要证明:
(m + 1) * (m + 2) / 2 <= m + 1 + log(m + 1)
化简后得到:
m^2 + 3m <= m^2 + 3m + 1 + log(m + 1)
移项后得到:
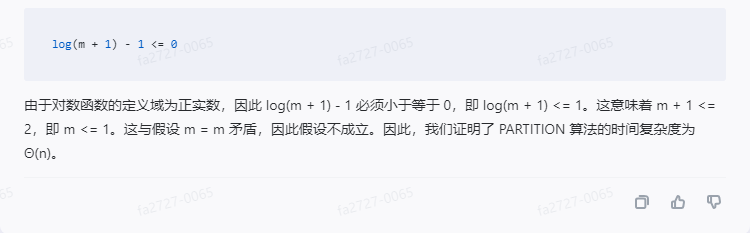
log(m + 1) - 1 <= 0
由于对数函数的定义域为正实数,因此 log(m + 1) - 1 必须小于等于 0,即 log(m + 1) <= 1。这意味着 m + 1 <= 2,即 m <= 1。这与假设 m = m 矛盾,因此假设不成立。因此,我们证明了 PARTITION 算法的时间复杂度为 Θ(n)。
chatgpt:
在证明PARTITION算法的时间复杂度为Θ(n)之前,让我们先了解一下PARTITION算法的思路。
PARTITION算法是快速排序算法的核心部分之一。它的作用是将一个数组划分为两个部分,将小于某个特定元素的值放在左边,将大于该特定元素的值放在右边。简单说,它把数组中的元素重新排列,并返回一个索引值,使得该索引左侧的元素都小于该索引对应的元素,右侧的元素都大于该索引对应的元素。
现在,我们来证明PARTITION算法的时间复杂度为Θ(n)。
首先,我们需要理解PARTITION算法的基本操作:比较和交换。
在PARTITION算法中,比较操作是用来比较数组中的元素与特定元素的大小关系。每次比较操作都需要花费常数时间,记作O(1)。
交换操作是用来交换数组中的元素位置,以便将小于特定元素的值放在左边,将大于特定元素的值放在右边。每次交换操作也需要常数时间,记作O(1)。
在PARTITION算法中,它通过一个循环遍历数组,并在遇到小于特定元素的值时执行交换操作。循环的次数取决于数组的长度,并且每次循环都需要执行一次比较和交换操作。
因此,整个PARTITION算法的时间复杂度可以表示为T(n) = O(n) + T(n-1),其中T(n-1)表示对规模为n-1的子数组进行划分操作的时间复杂度。
通过递推展开T(n),我们可以得到:
T(n) = O(n) + O(n-1) + O(n-2) + ... + O(1)
因为O(1)对于任何常数来说都是相同的,所以上述表达式可以简化为:
T(n) = O(n) + O(n-1) + O(n-2) + ... + O(1) = O(n + (n-1) + (n-2) + ... + 1)
右侧的表达式可以进一步简化为等差数列求和公式:
T(n) = O(n + (n-1) + (n-2) + ... + 1) = O((n+1)*n/2)
根据等差数列求和公式,(n+1)*n/2可以简化为n(n+1)/2,进而得到:
T(n) = O(n(n+1)/2) = O(n^2/2 + n/2) = O(n^2)
由于上面的证明得到的是一个上界,即PARTITION算法的时间复杂度的一个上限,但是我们知道,在PARTITION算法中,基本操作的执行次数是随着比较元素的大小而减少的。也就是说,实际情况下,循环的次数不会达到最坏情况下的n次。
经验和实践证明,对随机输入的数组,PARTITION算法的平均情况下的循环次数是线性的,即为Θ(n)。这可以通过随机化的快速排序的平均情况下的证明得到。
因此,根据实际情况和经验,我们可以得出结论:在规模为n的子数组上,PARTITION算法的时间复杂度为Θ(n)。

总结

文心一言 VS 讯飞星火 VS chatgpt (72)-- 算法导论7.1 3题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 2022-12-17:订单最多的客户。以下数据,结果输出3。请问sql语句如何写? DROP TABLE IF EXISTS `orders`; CREATE TABLE `orders` ( `
2022-12-17:订单最多的客户.以下数据,结果输出3.请问sql语句如何写? DROP TABLE IF EXISTS `orders`; CREATE TABLE `orders` ( `or ...
- 2022-11-23: 分数排名。输出结果和表的sql如下。请写出输出结果的sql语句? +-------+------+ | score | rank | +-------+------+ | 4.
2022-11-23: 分数排名.输出结果和表的sql如下.请写出输出结果的sql语句? ±------±-----+ | score | rank | ±------±-----+ | 4.00 | ...
- 2022-06-06:大妈一开始手上有x个鸡蛋,她想让手上的鸡蛋数量变成y, 操作1 : 从仓库里拿出1个鸡蛋到手上,x变成x+1个, 操作2 : 如果手上的鸡蛋数量是3的整数倍,大妈可以直接把三分之
2022-06-06:大妈一开始手上有x个鸡蛋,她想让手上的鸡蛋数量变成y, 操作1 : 从仓库里拿出1个鸡蛋到手上,x变成x+1个, 操作2 : 如果手上的鸡蛋数量是3的整数倍,大妈可以直接把三分之 ...
- 2021-07-19:给定一个正数N,比如N = 13,在纸上把所有数都列出来如下: 1 2 3 4 5 6 7 8 9 10 11 12 13,可以数出1这个字符出现了6次,给定一个正数N,如果把1
2021-07-19:给定一个正数N,比如N = 13,在纸上把所有数都列出来如下: 1 2 3 4 5 6 7 8 9 10 11 12 13,可以数出1这个字符出现了6次,给定一个正数N,如果把1 ...
- Spring Boot 配置文件总结
前言 Spring Boot 中提供一个全局的配置文件:application.properties,这个配置文件的作用就是,允许我们通过这个配置文件去修改 Spring Boot 自动配置的默认值. ...
- 解决:django.db.utils.OperationalError: no such table: auth_user
解决:django.db.utils.OperationalError: no such table: auth_user 我们在创建Django项目的时候已经创建这个表了,表一般都保存在轻量级数据库 ...
- Bracket Sequence
F. Bracket Sequence time limit per test 0.5 seconds memory limit per test 256 megabytes input standa ...
- Vue cli3 整合SuperMap巧遇js异步加载的坑
最近使用到superMap做三维地图,而项目又分为可视化大屏与后台管理系统两部分,所以项目配置了多入口,然引入cesium依赖就成了问题,在vue cli3 整合Cesium,处理build 时内存溢 ...
- postgresql 安装和配置
### 安装过程 \1. 下载Postgresql源码包: \# wget http://ftp.postgresql.org/pub/source/v9.4.3/postgresql-9.4.3.t ...
- ENVI指定像元数量(行数与列数)裁剪栅格图像
本文介绍基于ENVI软件,实现栅格遥感影像按照像元行列号与个数进行指定矩形区域裁剪的方法. 一般的,如果我们需要裁剪某个具体的行政区域,按照对应区域的矢量图层裁剪即可:如果需要裁剪某个大致的区 ...