深入分析Java中的PriorityQueue底层实现与源码
本文分享自华为云社区《滚雪球学Java(70):深入理解Java中的PriorityQueue底层实现与源码分析》,作者: bug菌。
环境说明:Windows 10 + IntelliJ IDEA 2021.3.2 + Jdk 1.8
@[toc]
前言
PriorityQueue是Java中一个非常常用的数据结构,它可以实现基于优先级的排序,常用于任务调度、事件处理等场景。本文将深入探讨Java中PriorityQueue的底层实现与源码分析,帮助读者更好地理解PriorityQueue的内部原理。
摘要
本文将从PriorityQueue的定义、特性入手,逐步分析其底层实现、源码解析以及应用场景案例、优缺点分析等方面,全面深入地理解PriorityQueue。
PriorityQueue
概述
PriorityQueue的定义与特性
在Java中,PriorityQueue是一个优先级队列,它是基于数组实现的,但是其中的元素不是按照插入顺序排列,而是按照元素的优先级进行排序。你可以将任意类型的对象插入PriorityQueue中,并且PriorityQueue会按照元素的自然顺序或者你自己定义的优先级顺序进行排序。
PriorityQueue是一个无界队列,即队列的容量可以无限扩充。它是线程不安全的,不支持null元素。默认情况下,PriorityQueue是自然排序,也就是小根堆,也可以通过Comparator接口来指定元素的排序方式。
PriorityQueue的底层实现
PriorityQueue是基于数组实现的,它的底层数据结构是一个小根堆。小根堆是一种完全二叉树,满足一个性质,即每个节点的值都小于或等于它的左右子节点的值。
在PriorityQueue中,数组的第一个元素是堆顶,也就是优先级最高的元素。每次插入一个元素时,PriorityQueue会先将元素添加到数组末尾,然后通过上浮操作来维护小根堆的性质。每次删除堆顶元素时,PriorityQueue会先将数组末尾元素移动到堆顶,然后通过下沉操作来维护小根堆的性质。
源代码解析
PriorityQueue的构造函数
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
public PriorityQueue(int initialCapacity, Comparator<? super E> comparator) {
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
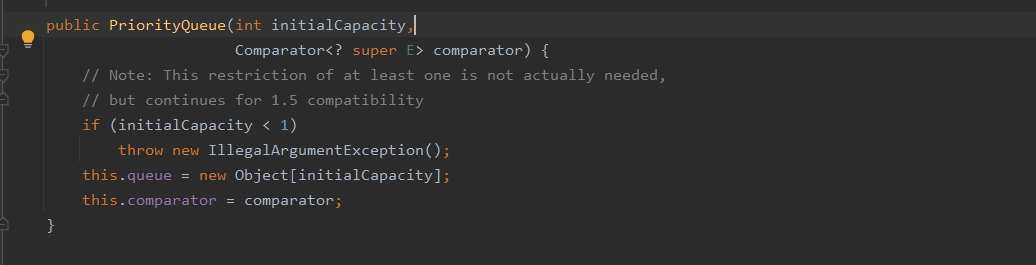
PriorityQueue有四个构造函数:默认构造函数、指定初始化容量的构造函数、指定Comparator的构造函数和同时指定初始化容量与Comparator的构造函数。
当不指定初始化容量和Comparator时,将会使用默认值。默认容量为11,Comparator为null。
如下是部分源码截图:
添加元素
public boolean add(E e) {
return offer(e);
}
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e);
return true;
}
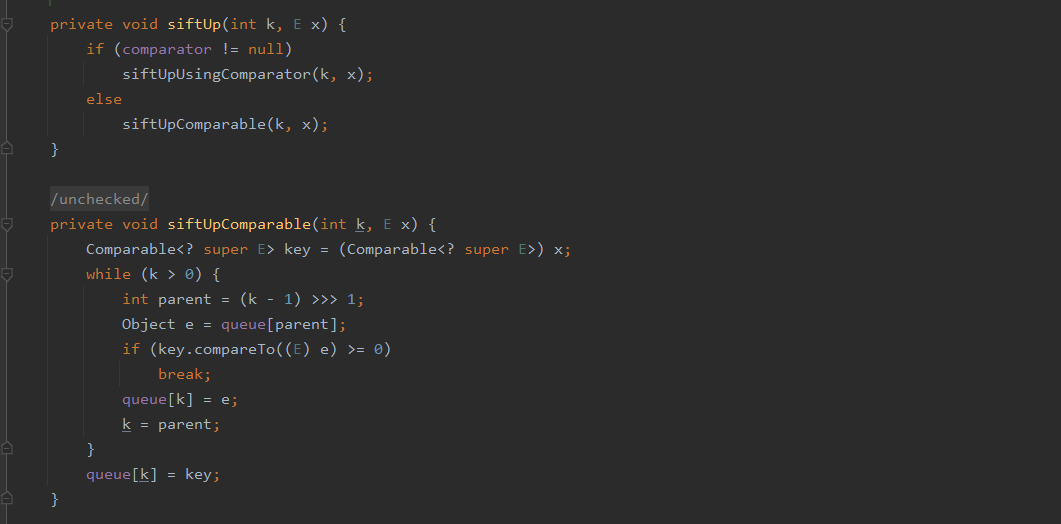
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
siftUpComparable(k, x);
}
添加元素时,会先判断队列是否已满,如果已满则通过grow()方法进行扩容。接着会将元素添加到数组末尾,然后通过siftUp()方法来维护小根堆的性质。
如果指定了Comparator,则通过siftUpUsingComparator()方法来维护小根堆的性质;否则通过siftUpComparable()方法维护小根堆的性质。这里的siftUp()方法还是比较关键的,它是用来上浮元素,维护小根堆的性质的。
删除元素
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);
return result;
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
删除元素时,会先判断队列是否为空。如果不为空,就将堆顶元素取出作为返回值,然后将数组末尾的元素移动到堆顶,通过siftDown()方法来维护小根堆的性质。
如果指定了Comparator,则通过siftDownUsingComparator()方法来维护小根堆的性质;否则通过siftDownComparable()方法维护小根堆的性质。
拓展:
这段代码是Java中PriorityQueue类中的poll()方法的实现。poll()方法用于从队列中取出并删除队列头部的元素,如果队列为空则返回null。
该方法首先检查队列是否为空,如果为空则返回null。否则,将队列中的元素个数减1,更新modCount属性表示这次操作改变了队列结构,将队列头部的元素用变量result存储。接着,将队列中最后一个元素用变量x存储,并将队列中最后一个元素置为null。若队列还有元素,调用siftDown()方法将变量x与队列中元素重新排序,确保队列满足小根堆的性质。最后,返回变量result,即队列中被删除的元素。
在siftDown()方法中,首先判断comparator是否为null。如果不为null,则调用siftDownUsingComparator()方法,否则调用siftDownComparable()方法。这两个方法都是用来重建小根堆的,不同的是,siftDownUsingComparator()方法通过比较器来实现排序,而siftDownComparable()方法则通过元素的自然顺序来实现排序。
应用场景案例
任务调度
假设我们需要实现一个任务调度器,能够按照任务的优先级来执行任务。我们可以将任务按照优先级添加到PriorityQueue中,然后按照队列中任务的顺序依次执行。
public class Task implements Comparable<Task> {
private int priority;
private Runnable runnable;
public Task(int priority, Runnable runnable) {
this.priority = priority;
this.runnable = runnable;
}
public void run() {
runnable.run();
}
@Override
public int compareTo(Task o) {
return Integer.compare(priority, o.priority);
}
}
public class MyTaskScheduler {
private PriorityQueue<Task> queue;
public MyTaskScheduler() {
queue = new PriorityQueue<>();
}
public void schedule(Task task) {
queue.offer(task);
}
public void run() {
while (!queue.isEmpty()) {
Task task = queue.poll();
task.run();
}
}
}
分析代码:
这段代码定义了一个Task类和一个MyTaskScheduler类,用于实现任务调度。Task类包含了一个优先级和一个Runnable对象,用于存储待执行的任务和它的优先级。MyTaskScheduler类包含了一个优先队列,用于存储所有的任务,并且包括了两个方法:schedule()方法用于将任务加入到队列中,run()方法则用于执行队列中的所有任务。
Task类实现了Comparable接口,重写了compareTo()方法,通过比较任务的优先级,来判断哪个任务先执行。MyTaskScheduler类使用了Java自带的PriorityQueue优先队列,保证了任务的执行顺序是按照优先级从高到低的顺序执行。在run()方法中,使用一个while循环,不断从队列中取出优先级最高的任务,直到队列为空。对于每个任务,调用它的run()方法来执行任务逻辑。
这段代码可以用于实现多个任务的调度,通过设置不同的优先级,来控制不同任务的执行顺序。同时,使用优先队列可以保证任务按照优先级的顺序执行,提高了任务执行的效率。
网络代理
假设我们需要实现一个网络代理,能够按照ip包的优先级来转发数据。我们可以将ip包按照优先级添加到PriorityQueue中,然后按照队列中ip包的顺序依次转发数据。
public class IpPacket implements Comparable<IpPacket> {
private int priority;
private byte[] data;
public IpPacket(int priority, byte[] data) {
this.priority = priority;
this.data = data;
}
public byte[] getData() {
return data;
}
@Override
public int compareTo(IpPacket o) {
return Integer.compare(priority, o.priority);
}
}
public class MyNetworkProxy {
private PriorityQueue<IpPacket> queue;
public MyNetworkProxy() {
queue = new PriorityQueue<>();
}
public void send(IpPacket packet) {
queue.offer(packet);
}
public void receive() {
while (!queue.isEmpty()) {
IpPacket packet = queue.poll();
// 转发数据
}
}
}
拓展:
上面是一个简单的网络代理程序,其中包含两个类:IpPacket和MyNetworkProxy。
IpPacket类表示一个IP数据包,包含数据的优先级和实际的数据。实现了Comparable接口,用于优先级的排序。
MyNetworkProxy类表示一个网络代理,通过维护一个优先级队列来实现数据包的转发。send方法用于将数据包添加到队列中,receive方法用于从队列中取出优先级最高的数据包并进行转发。
在MyNetworkProxy中,当队列不为空时,每次从队列头取出优先级最高的数据包进行转发,直到队列为空。
这个程序中的优先级队列可以保证高优先级的数据包先被发送,以保证网络的效率和响应时间。
优缺点分析
优点
- PriorityQueue是一个非常高效的数据结构,它的插入和删除元素的时间复杂度都是O(log n)。
- PriorityQueue可以实现基于优先级的排序,适用于任务调度、事件处理等场景。
- PriorityQueue在扩容时可以节省空间,只需将数组容量增加一半即可。
- PriorityQueue支持自然排序和指定Comparator来定义元素的排序方式。
缺点
- PriorityQueue是线程不安全的,不适合在多线程环境下使用。如果需要在多线程环境下使用,可以使用PriorityBlockingQueue。
- PriorityQueue不支持随机访问元素,只能访问堆顶元素。如果需要随机访问元素,可以使用TreeSet。
类代码方法介绍
public
public class PriorityQueue<E> extends AbstractQueue<E> implements java.io.Serializable {
/**
* 序列化 ID
*/
private static final long serialVersionUID = -7720805057305804111L;
/**
* 默认初始容量
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 底层数组,用于存储堆元素
*/
transient Object[] queue;
/**
* 数组中元素的数量
*/
private int size = 0;
/**
* 比较器,用于确定堆中元素的顺序
*/
private final Comparator<? super E> comparator;
/**
* 修改次数,用于判断在迭代过程中堆是否发生了修改
*/
transient int modCount = 0;
/**
* 构造一个初始容量为11的PriorityQueue,元素顺序按照自然顺序排列
*/
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
/**
* 构造一个指定初始容量的PriorityQueue,元素顺序按照自然顺序排列
*/
public PriorityQueue(int initialCapacity) {
this(initialCapacity, null);
}
/**
* 构造一个初始容量为11的PriorityQueue,元素顺序按照指定比较器排列
*/
public PriorityQueue(Comparator<? super E> comparator) {
this(DEFAULT_INITIAL_CAPACITY, comparator);
}
/**
* 返回PriorityQueue的头部元素,如果队列为空,则返回null
*/
public E peek() {
if (size == 0) {
return null;
}
return (E) queue[0];
}
/**
* 返回PriorityQueue中元素的数量
*/
public int size() {
return size;
}
/**
* 对元素进行排序,排序的规则由比较器决定
*/
private void heapify() {
for (int i = (size >>> 1) - 1; i >= 0; i--) {
siftDown(i, (E) queue[i]);
}
}
/**
* 返回一个包含PriorityQueue中所有元素的数组
*/
@Override
public Object[] toArray() {
return Arrays.copyOf(queue, size);
}
以上是Java中PriorityQueue类的部分源码。PriorityQueue是一个堆,可以存储任意类型的元素,但是需要这些元素是可比较的,可以按照一定的顺序进行排序。PriorityQueue实现了Queue接口,因此可以像队列一样进行添加和删除元素,并且堆的性质保证了每次返回的元素都是最优的。
如下是部分源码截图:
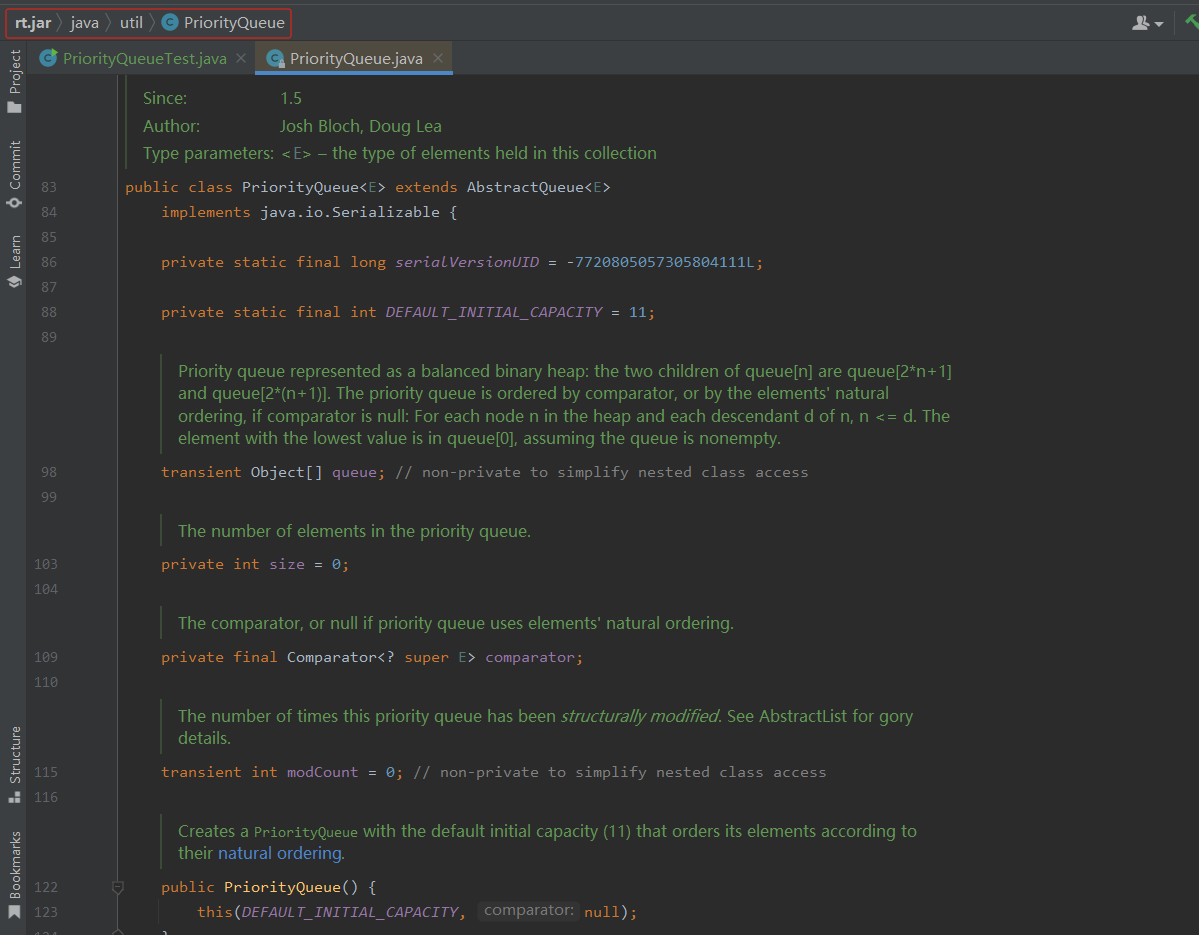
具体分析如下:
PriorityQueue类是一个泛型类,使用类名后面的<E>表示。
类中定义了一个序列化ID,一个底层数组用于存储堆元素,一个记录数组中元素数量的变量,一个记录堆发生修改次数的变量,以及一个比较器。其中比较器用于判断堆中元素的顺序。
类中定义了多个构造方法,可以创建一个初始容量为11的PriorityQueue,也可以指定初始容量和比较器。
PriorityQueue类实现了Queue接口中的offer、peek和poll方法。其中offer方法用于将元素添加到PriorityQueue中,peek方法用于返回PriorityQueue的头部元素,如果队列为空,则返回null,poll方法用于删除PriorityQueue的头部元素,并返回该元素,如果队列为空,则返回null。
类中还定义了一个size方法,用于返回PriorityQueue中元素的数量。
PriorityQueue类实现了Iterable接口,因此可以迭代PriorityQueue中的元素。在此基础上,类中定义了一个Itr迭代器类,用于遍历PriorityQueue中的元素。其中,由于堆不保证元素的顺序,因此元素的顺序是不确定的。
类中还实现了一个使用指定的Collection构造PriorityQueue的方法,用于将一个Collection中的元素添加到PriorityQueue中。
heapify方法用于对元素进行排序,排序的规则由比较器决定。
toArray方法用于返回一个包含PriorityQueue中所有元素的数组。其中,使用Arrays类的copyOf方法对底层数组进行复制和截取,以保证只返回PriorityQueue中的有效元素。
测试用例
下面是一个简单的示例main函数,使用Java中的PriorityQueue实现一个整数优先级队列,并添加一些元素并打印结果:
测试代码演示
package com.demo.javase.day70; import java.util.PriorityQueue; /**
* @Author bug菌
* @Date 2023-11-06 16:08
*/
public class PriorityQueueTest { public static void main(String[] args) {
PriorityQueue<Integer> pq = new PriorityQueue<>();
pq.add(5);
pq.add(1);
pq.add(10);
pq.add(3);
pq.add(2); System.out.println("队列中的元素(从小到大):");
while (!pq.isEmpty()) {
System.out.print(pq.poll() + " ");
}
}
}
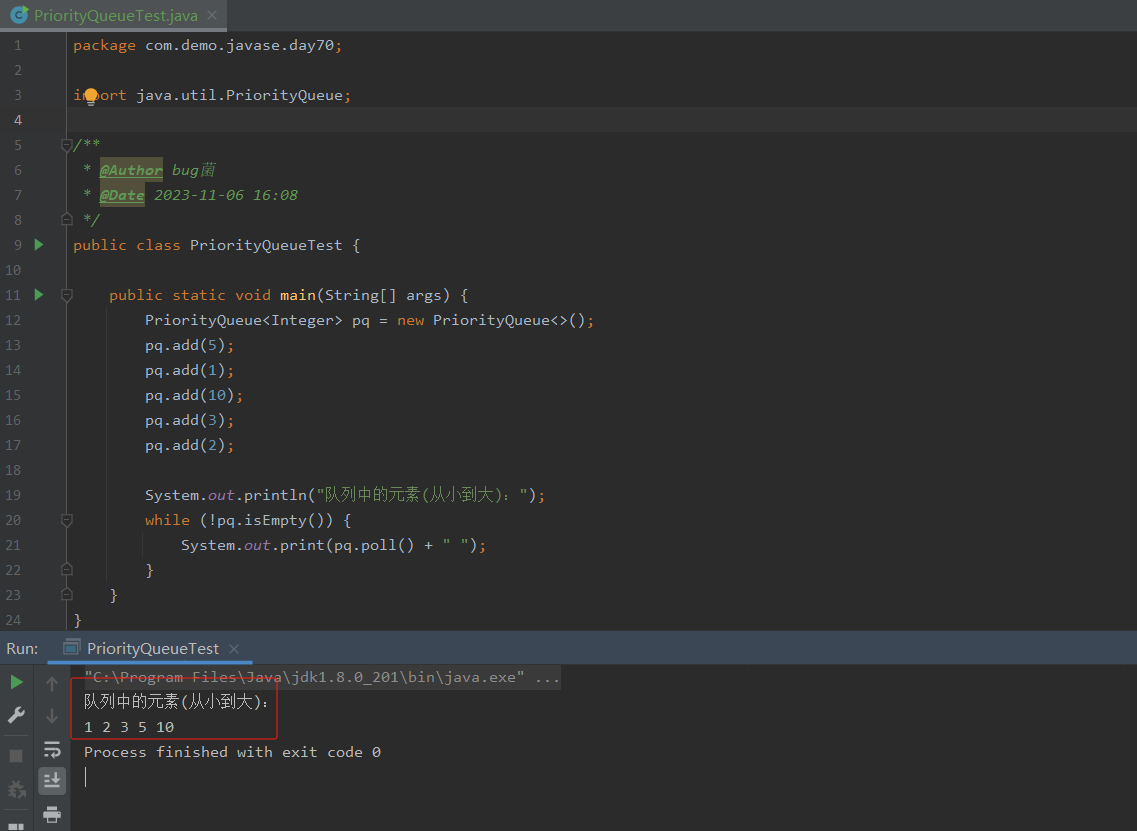
测试结果
根据如上测试用例,本地测试结果如下,仅供参考,你们也可以自行修改测试用例或者添加更多的测试数据或测试方法,进行熟练学习以此加深理解。
输出结果:
队列中的元素(从小到大):
1 2 3 5 10
在这个示例中,我们创建了一个PriorityQueue对象pq,并添加了5个整数元素。然后,我们使用poll()方法按照优先级顺序逐个弹出元素,并打印结果。注意,PriorityQueue默认使用自然顺序(从小到大),因此我们不需要指定比较器。
实际执行结果如下:
测试代码分析
根据如上测试用例,在此我给大家进行深入详细的解读一下测试代码,以便于更多的同学能够理解并加深印象。
如上测试用例演示了Java中的PriorityQueue(优先队列)的用法。在主方法中,先创建了一个PriorityQueue对象pq,并向其中添加了五个整数元素(5,1,10,3,2)。然后通过while循环,从队列中取出元素并打印,因为PriorityQueue默认是小根堆,所以打印出来的元素是从小到大排列的。最终输出结果为:队列中的元素(从小到大):1 2 3 5 10
小结
本文通过对Java中PriorityQueue的定义、特性、底层实现及源码解析进行详细分析,深入探讨了PriorityQueue的内部原理。PriorityQueue是一种基于数组实现的堆,它可以按照元素的优先级进行排序,常用于任务调度、事件处理等场景。PriorityQueue底层是一个小根堆,在元素添加和删除时,会通过上浮和下沉操作来维护小根堆的性质。同时,本文也介绍了PriorityQueue的应用场景案例以及优缺点分析,帮助读者更好地理解PriorityQueue。
总之,PriorityQueue作为Java集合框架中的一个重要组成部分,对于Java开发者来说,是必不可少的知识点。读者可以通过学习本文,加深对PriorityQueue的理解,从而更好地应用于实际开发中。
总结
本文从PriorityQueue的定义、特性和底层实现入手,深入剖析了Java中PriorityQueue的源码和应用场景案例,并对其进行了优缺点分析。PriorityQueue是一种非常高效的数据结构,可以实现基于优先级的排序,适用于任务调度、事件处理等场景。但是需要注意的是,它是线程不安全的,不支持随机访问元素。在使用PriorityQueue时,需要根据实际情况选择适合的数据结构和算法来解决问题。
深入分析Java中的PriorityQueue底层实现与源码的更多相关文章
- java中的==、equals()、hashCode()源码分析(转载)
在java编程或者面试中经常会遇到 == .equals()的比较.自己看了看源码,结合实际的编程总结一下. 1. == java中的==是比较两个对象在JVM中的地址.比较好理解.看下面的代码: ...
- java中Comparator比较器顺序问题,源码分析
提示: 分析过程是个人的一些理解,如有不对的地方,还请大家见谅,指出错误,共同学习. 源码分析过程中由于我写的注释比较啰嗦.比较多,导致文中源代码不清晰,还请一遍参照源代码,一遍参照本文进行阅读. 原 ...
- java中的==、equals()、hashCode()源码分析
转载自:http://www.cnblogs.com/xudong-bupt/p/3960177.html 在Java编程或者面试中经常会遇到 == .equals()的比较.自己看了看源码,结合实际 ...
- 深入分析 Java 中的中文编码问题
登录 (或注册) 中文 IBM 技术主题 软件下载 社区 技术讲座 打印本页面 用电子邮件发送本页面 新浪微博 人人网 腾讯微博 搜狐微博 网易微博 Digg Facebook Twitter Del ...
- [转]深入分析 Java 中的中文编码问题
收益匪浅,所以转发至此 原文链接: http://www.ibm.com/developerworks/cn/java/j-lo-chinesecoding/ 深入分析 Java 中的中文编码问题 编 ...
- Java中正负数的存储方式-正码 反码和补码
Java中正负数的存储方式-正码 反码和补码 正码 我们以int 为例,一个int占用4个byte,32bits 0 存在内存上为 00000000 00000000 00000000 0000000 ...
- Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析
Java生鲜电商平台-SpringCloud微服务架构中网络请求性能优化与源码解析 说明:Java生鲜电商平台中,由于服务进行了拆分,很多的业务服务导致了请求的网络延迟与性能消耗,对应的这些问题,我们 ...
- Spring中AOP相关的API及源码解析
Spring中AOP相关的API及源码解析 本系列文章: 读源码,我们可以从第一行读起 你知道Spring是怎么解析配置类的吗? 配置类为什么要添加@Configuration注解? 谈谈Spring ...
- PriorityQueue原理分析——基于源码
在业务场景中,处理一个任务队列,可能需要依照某种优先级顺序,这时,Java中的PriorityQueue(优先队列)便可以派上用场.优先队列的原理与堆排序密不可分,可以参考我之前的一篇博客: 堆排序总 ...
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- Build 和 Compile 区别
- 端口碰撞Port Knocking和单数据包授权SPA
端口碰撞技术 Port knocking 从网络安全的角度,服务器开启的端口越多就越不安全,因此系统安全加固服务中最常用的方式,就是先关闭无用端口,再对提供服务的端口做访问控制.而作为远程管理与维护的 ...
- 【Unity3D】空间和变换
1 空间 1.1 左右手坐标系及其法则 1.1.1 左右手坐标系 左手坐标系与右手坐标系 Unity 局部空间.世界空间.裁剪空间.屏幕空间都采用左手坐标系,只有观察空间采用右手坐标系. 左右 ...
- 优先队列(PriorityQueue)常用方法及简单案例
1 前言 PriorityQueue是一种特殊的队列,满足队列的"队尾进.队头出"条件,但是每次插入或删除元素后,都对队列进行调整,使得队列始终构成最小堆(或最大堆).具体调整如下 ...
- HTTP协议发展历程
HTTP协议发展历程 HTTP超文本传输协议是一个用于传输超文本文档的应用层协议,它是为Web浏览器与Web服务器之间的通信而设计的,HTTP协议到目前为止全部的版本可以分为HTTP 0.9.HTTP ...
- od命令
od命令 od命令会读取所指定的文件的内容,并将其内容以八进制字节码呈现出来. 语法 od [OPTION]... [FILE]... od [-abcdfilosx]... [FILE] [[+]O ...
- 我的小程序之旅五:微信公众号扫码登录PC端网页
代码仓库:https://gitee.com/wlovet/gzh-qrlogin 一.准备材料 1.已认证的公众号(必须为服务号,订阅号没有该接口的权限) 2.一个网址,用于微信回调,推荐一个内网穿 ...
- Redis服务端事件处理流程分析
一.事件处理 1.1 什么是事件 Redis 为什么运行得比较快? 原因之一就是它的服务端处理程序用了事件驱动的处理方式. 那什么叫事件处理?就是把处理程序当成一个一个的事件处理.比如我前面文章:服务 ...
- day04---系统重要文件
系统重要的文件 /etc的重要文件 1./etc/sysconfig/network-scripts/ifcfg-eth0 [root@localhost ~]# cat /etc/sysconfig ...
- celery正常启动后能接收任务但不执行(已解决)
错误截图:celery接收到任务却不执行(多出在windows系统中) 解决方法1 添加–pool=solo参数 celery -A celery_tasks.main worker --pool=s ...