【Java】自制查找工具
需求:查找后台代码中写的SQL是否包含拆分表,如果存在,则返回那些表名
Context.txt 粘贴我们找到的DAO层代码,因为所有方法封装的SQL都在DAO层里【就理解为筛查的字符串】
Dictionary.txt 存放了拆分表的名字,也就是字典
Output.log 输出日志
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.FileReader;
import java.io.FileWriter;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
import java.time.format.FormatStyle;
import java.util.*;
import java.util.logging.Logger; public class Main { private static Logger logger = Logger.getLogger(Main.class.getName()); // 当前程序所在路径
private static final String LOCAL_PATH = System.getProperty("user.dir");
private static final String CONTEXT_FILE_PATH = LOCAL_PATH + "\\Context.txt";
private static final String DICTIONARY_FILE_PATH = LOCAL_PATH + "\\Dictionary.txt";
private static final String OUTPUT_FILE_PATH = LOCAL_PATH + "\\Output.log"; public static void main(String[] args) throws Exception { FileReader contextFileReader = new FileReader(CONTEXT_FILE_PATH);
BufferedReader contextBufferedReader = new BufferedReader(contextFileReader); FileReader dictionaryFileReader = new FileReader(DICTIONARY_FILE_PATH);
BufferedReader dictionaryBufferedReader = new BufferedReader(dictionaryFileReader); FileWriter outputFileWriter = new FileWriter(OUTPUT_FILE_PATH);
BufferedWriter outputBufferedWriter = new BufferedWriter(outputFileWriter); // 加载字典
String dictString = dictionaryBufferedReader.readLine();
// 封装结构
List<String> dictList = Arrays.asList(dictString.split(",")); // 扫描的context行
String tempRow = ""; LinkedHashMap<String, Object> linkedHashMap = new LinkedHashMap();
linkedHashMap.put("flag", false); LinkedList linkedList = new LinkedList(); // 对context进行扫描
while (null != (tempRow = contextBufferedReader.readLine())) {
// 创建字典的迭代器
Iterator<String> iterator = dictList.iterator(); // 迭代扫描
while (iterator.hasNext()) {
String perDict = iterator.next(); // 遍历的每一个字典的字
// 判断context当前行是否包含这个字典
boolean contains = tempRow.toLowerCase().contains(perDict.trim());
int index = tempRow.indexOf(perDict + "_");
if (contains && index == -1) {
if (! linkedList.contains(perDict.trim())) {
linkedList.add(perDict.trim());
} if (contains && ! (Boolean) linkedHashMap.get("flag")) {
linkedHashMap.put("flag", true);
}
}
}
} linkedHashMap.put("containTable", linkedList); outputBufferedWriter.write(linkedHashMap.toString()); outputBufferedWriter.flush(); contextBufferedReader.close();
dictionaryBufferedReader.close();
outputBufferedWriter.close();
logger.info(DateTimeFormatter.ofLocalizedDate(FormatStyle.MEDIUM).format(LocalDateTime.now()) + linkedHashMap.toString()); }
}
封装成JAR 用CMD脚本跑程序【Run.cmd】:
java -jar (定义的jar包文件名) xxx.jar
pause
程序与读取的文件要放在同一个目录下:
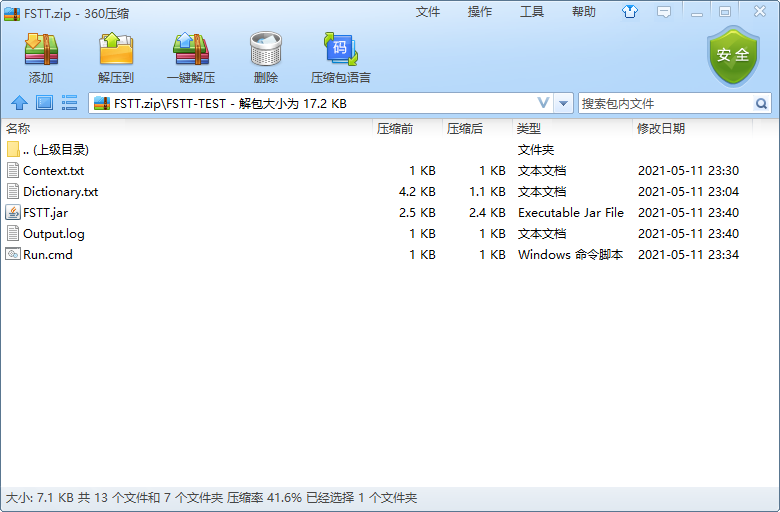
【Java】自制查找工具的更多相关文章
- Java 标准日志工具 Log4j 的使用(附源代码)
源代码下载 Log4j 是事实上的 Java 标准日志工具.会不会用 Log4j 在一定程度上可以说是衡量一个开发人员是否是一位合格的 Java 程序员的标准.如果你是一名 Java 程序员,如果你还 ...
- Java 问题定位工具 -- jps
概览 最近老大布置的任务就是质量加固,偶然看到了一些对于 Java 性能分析的介绍,因此,有了此篇学习笔记. JDK本身提供了很多方便的JVM性能调优监控工具,除了集成式的VisualVM和jCons ...
- Java集合——Collections工具类
Java集合——Collections工具类 摘要:本文主要学习了Collections工具类的常用方法. 概述 Collections工具类主要用来操作集合类,比如List和Set. 常用操作 排序 ...
- Linux操作系统的文件查找工具locate和find命令常用参数介绍
Linux操作系统的文件查找工具locate和find命令常用参数介绍 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.非实时查找(数据库查找)locate工具 locate命 ...
- java命令--jstack 工具【转载】
一.介绍 jstack是java虚拟机自带的一种堆栈跟踪工具.jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项&qu ...
- linux文件查找工具——locate,find
一文件查找介绍 文件的查找就是在文件系统上查找符合条件的文件. 文件查找的方式:locate, find非实时查找也就是基于数据库查找的locate,效率特别高. 实时查找:find 二locate ...
- 细说Java主流日志工具库
概述 在项目开发中,为了跟踪代码的运行情况,常常要使用日志来记录信息. 在Java世界,有很多的日志工具库来实现日志功能,避免了我们重复造轮子. 我们先来逐一了解一下主流日志工具. java.util ...
- Java 性能分析工具 , 第 3 部分: Java Mission Control
引言 本文为 Java 性能分析工具系列文章第三篇,这里将介绍如何使用 Java 任务控制器 Java Mission Control 深入分析 Java 应用程序的性能,为程序开发人员在使用 Jav ...
- Java 性能分析工具 , 第 2 部分:Java 内置监控工具
引言 本文为 Java 性能分析工具系列文章第二篇,第一篇:操作系统工具.在本文中将介绍如何使用 Java 内置监控工具更加深入的了解 Java 应用程序和 JVM 本身.在 JDK 中有许多内置的工 ...
- HttpTool.java(在java tool util工具类中已存在) 暂保留
HttpTool.java 该类为java源生态的http 请求工具,不依赖第三方jar包 ,即插即用. package kingtool; import java.io.BufferedReader ...
随机推荐
- C#.NET 4.8 WEBP 转 GIF
C#.NET 4.8 WEBP 转 GIF 项目是.NET 4.8. nuget 引用 Magick.NET-Q16-AnyCPU ,版本:7.14.5.高版本,如:12.2 已经不支持.NET FR ...
- reids分片技术cluster篇
为什么学redis-cluster 前面两篇文章,主从复制和哨兵机制保障了高可用 就读写分离,而言虽然slave节点扩展了主从的读并发能力 但是写能力和存储能力是无法进行扩展,就只能是master节点 ...
- Vue学习:4.v-model使用
第一节算是对v-model的粗略了解,仅仅是将input的输入与Vue 实例的数据之间双向绑定.这一节将更详细的了解v-model在不同表单元素中的使用. v-model实例:找对象 实现功能: 使用 ...
- MySql 表数据的增、删、改、查
数据表的增.删.改.查 前言 在学习 MySql 一定少不了对数据表的增.删.改.查,下面将详细讲解如何操作数据表. 前面已经建好了表 customer 列表如下: 插入数据 插入数据可以使用 INS ...
- mongodb创建索引和删除索引和背景索引background
mongodb创建索引和删除索引和背景索引background MongoDB的背景索引允许在后台创建和重建索引,而不会对数据库的正常操作产生影响.背景索引的创建过程是非阻塞的,可以在业务运行时创建或 ...
- 新浪微博动态 RSA 分析图文+登录
Tips:当你看到这个提示的时候,说明当前的文章是由原emlog博客系统搬迁至此的,文章发布时间已过于久远,编排和内容不一定完整,还请谅解` 新浪微博动态 RSA 分析图文+登录 日期:2016-10 ...
- c++ win32 纤程
Win32纤程是一种轻量级的协程机制,它能够在同一个线程中实现多个线程执行的效果,从而提高了程序的并发性和可伸缩性. 在C++中,可以使用Win32 API中的fiber来实现纤程.以下是一个使用纤程 ...
- Ajax分析与爬取实战
Ajax 分析与爬取实战 准备工作 安装好 Python3 了解 Python HTTP 请求库 requests 的基本用法 了解 Ajax 基础知识和分析 Ajax 的基本方法 爬取目标 以一个示 ...
- Linux 内核:设备树中的特殊节点
Linux 内核:设备树中的特殊节点 背景 在解析设备树dtb格式的时候,发现了这个,学习一下. 参考: https://blog.csdn.net/weixin_45309916/article/d ...
- 关于kubesphere集群calico网络组件报错的修复
最近公司的项目用到了Kubesphere,于是自己先在虚拟机上测试了一番,遇到了很多的问题,现将遇到的有关calico的问题记录一下 上一篇介绍了如何离线安装kubesphere v3.0,安装之后我 ...