数仓OLAP技术
数据应用,是真正体现数仓价值的部分,包括且又不局限于 数据可视化、BI、OLAP、即席查询,实时大屏,用户画像,推荐系统,数据分析,数据挖掘,人脸识别,风控反欺诈,ABtest等等
OLAP(On-Line Analytical Processing):在线分析处理,主要用于支持企业决策管理分析。
OLAP分类
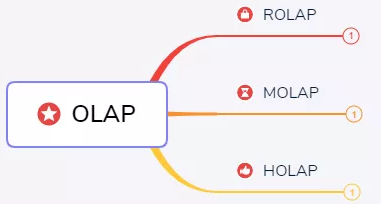
OLAP按存储器的数据存储格式分为:
1、ROLAP(Relational OLAP)
- 完全基于关系模型进行存储数据,不需要预计算,按需即时查询。
- 明细和汇总数据都保存在关系型数据库事实表中。
- 代表技术栈有Presto、impala with Kudu、ClickHouse等
2、MOLAP(Multi-dimensional OLAP)
- 基于多维数组的存储模型,也是OLAP最初的形态,特点是对数据进行预计算,以空间换效率,明细和聚合数据都保存在cube中,但生成cube需要大量时间和空间。
- 代表技术有Kylin、Druid
3、HOLAP(Hybrid OLAP)
- 相当于是ROLAP和MOLAP混合模型,其中:这种方式相对灵活,且更加高效。
- 细节数据以ROLAP存放
- 聚合数据以MOLAP存放
可按企业业务场景和数据粒度进行取舍,没有最好,只有最适合。
OLAP数据库技术
在大数据数仓架构中,最早的架构离线以Hive为主,实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,后起之秀Pulsar想要做出超越难度很大,Hbase、Redis和MySQL都在特定场景下有一席之地。唯独在OLAP领域,百家争鸣,各有所长。
OLAP引擎/工具/数据库,技术选型可有很多选择,传统公司大多以Congos、Oracle、MicroStrategy等OLAP产品,互联网公司则普遍强势拥抱开源,如:
- Presto,Druid ,Impala,SparkSQL,AnalyticDB,(Hbase)Phoenix,kudu, Kylin,Greenplum,Clickhouse, Hawq, Drill,ES等
在数据架构时,可以说目前没有一个引擎能在数据量,灵活程度和性能上(吞吐和并发)做到完美,用户需要根据自己的业务场景进行选型。
开源技术选型,MOLAP可选Kylin、Druid,ROLAP可选Presto、impala等
1、Presto
Presto 是由 Facebook 开源的大数据分布式 SQL 查询引擎,基于内存的低延迟高并发并行计算(MPP),适用于交互式分析查询。Preso特点:
- 本身并不存储数据,但是可以接入多种数据源,包括 Hive、RDBMS(Mysql、Oracle、Tidb等)、Kafka、MongoDB、Redis等
- 完全支持ANSI SQL标准,用户可以直接使用 ANSI SQL 进行数据查询和计算
- 可以混合多个catalog进行join查询和计算,支持跨数据源的级联查询
- 基于PipeLine进行设计的,流水管道式数据处理,支持数据规模GB~PB,计算中拿出一部分放在内存、计算、抛出、再拿。
- SQL on Hadoop:弥补Hive的效率性能和灵活性的不足,Presto和Spark SQL、Impala有很多异曲同工之处。
2、Druid
Druid是一个用于大数据实时查询和分析的高容错、高性能开源分布式系统,用于解决如何在大规模数据集下进行快速的、交互式的查询和分析。
数据可以实时摄入,进入到Druid后立即可查,同时数据是几乎是不可变。通常是基于时序的事实事件,事实发生后进入Druid,外部系统就可以对该事实进行查询。
Apache Druid 特点:
- 亚秒级 OLAP 查询,包括多维过滤、Ad-hoc 的属性分组、快速聚合数据等等。
- 实时的数据消费,真正做到数据摄入实时、查询结果实时。
- 高效的多租户能力,最高可以做到几千用户同时在线查询。
- 扩展性强,支持 PB 级数据、千亿级事件快速处理,支持每秒数千查询并发。
- 极高的高可用保障,支持滚动升级。
不适用的场景:
- 由于druid属于时间存储,删除操作比较繁琐,且不支持查询条件删除数据,只能根据时间范围删除数据。
- Druid能接受的数据的格式相对简单,比如不能处理嵌套结构的数据。
- 无 Join 操作:Druid 适合处理星型模型的数据,不支持关联操作。
- 数据没有 update 更新操作,只对 segment 粒度进行覆盖
- 由于时序化数据的特点,Druid 不支持数据的更新。
3、Clickhouse
Clickhouse是一个用于在线分析处理(OLAP)的列式数据库管理系统(DBMS)。
是由俄罗斯的Yandex公司为了Yandex Metrica网络分析服务而开发。它支持分析实时更新的数据,Clickhouse以高性能著称。

不适用的场景:

我以前是非常摒弃ROLAP的,因为实在是太慢了。ROLAP都是现算的,以前的套路基本都是生成一个巨复杂的sql扔到数据库里跑,那样能不慢么?但是这个ClickHouse却不一样,它最显著的特性就是快!这不科学啊!
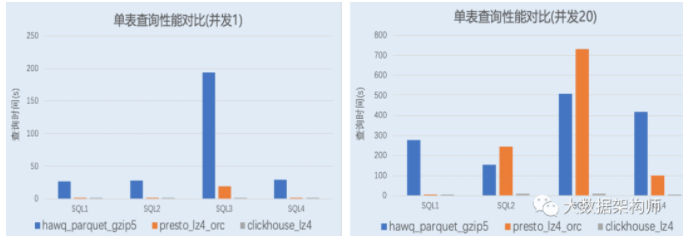
虽然各种测评都会选择偏向自己的指标,但是这也太悬殊了吧?ClickHouse的创始人yandex公司的同事出来解释过,有点让我失望,并不是一个非常牛的算法或者方案,而是从硬件开始向上一点一点的优化。是不是特别惊讶?
所以ClickHouse另外一个特性就是独立,不需要任何组件的依赖,貌似现在都有往这方面发展的趋势,比如Doris也是不需要依赖的。我们知道Kylin是需要依赖Hbase的。这就会引起各种各样的组件版本问题。想想就头大!
ClickHouse在运行的时候,会用掉服务器的所有资源,不仅仅是内存哦!甚至你查一个简单但是数据,都会吃掉50%以上的CPU!!!
另外,CK还有以下特性:
- PB级数据处理能力
- 列式数据存储
- 优秀的数据压缩
- 多核并行处理
- 多服务器分布式处理
- SQL支持(部分语句有点怪)
- 向量化引擎
- 支持实时数据更新
- 高吞吐写入
- 近似计算
- 少依赖,上手非常容易
对比:

对比图:
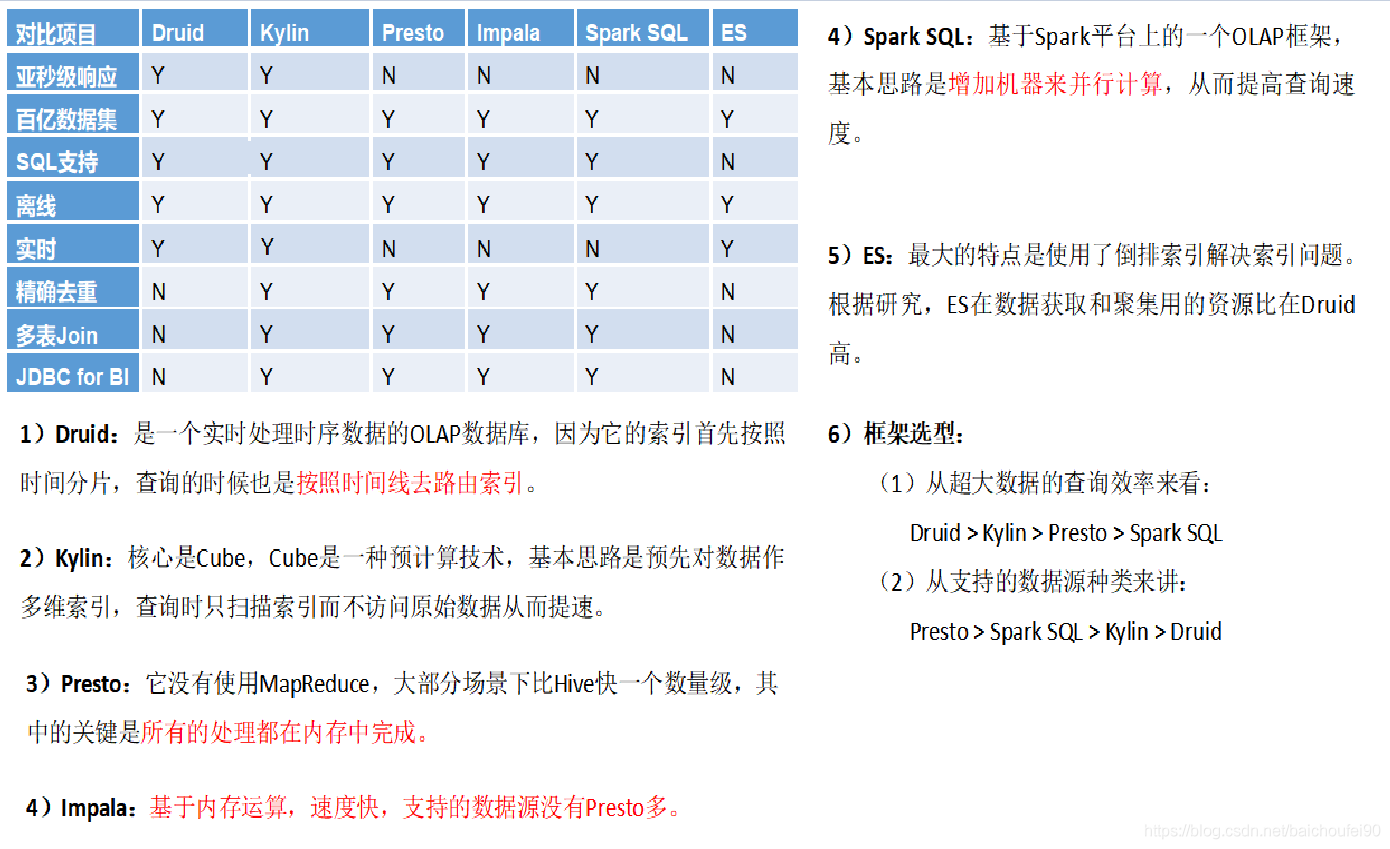
Flag:
- Impala、Presto 基于内存计算的引擎,没这么多高配的机器,不考虑
- Kylin:是我们把KMS的架构用坏了还是....? 没体现出来它的高性能
- clickhouse:关注引入。
参考
数仓OLAP技术的更多相关文章
- 解析数仓OLAP函数:ROLLUP、CUBE、GROUPING SETS
摘要:GaussDB(DWS) ROLLUP,CUBE,GROUPING SETS等OLAP函数的原理解析. 本文分享自华为云社区<GaussDB(DWS) OLAP函数浅析>,作者: D ...
- HAWQ取代传统数仓实践(十九)——OLAP
一.OLAP简介 1. 概念 OLAP是英文是On-Line Analytical Processing的缩写,意为联机分析处理.此概念最早由关系数据库之父E.F.Codd于1993年提出.OLAP允 ...
- 【云+社区极客说】新一代大数据技术:构建PB级云端数仓实践
本文来自腾讯云技术沙龙,本次沙龙主题为构建PB级云端数仓实践 在现代社会中,随着4G和光纤网络的普及.智能终端更清晰的摄像头和更灵敏的传感器.物联网设备入网等等而产生的数据,导致了PB级储存的需求加大 ...
- HAWQ取代传统数仓实践(十六)——事实表技术之迟到的事实
一.迟到的事实简介 数据仓库通常建立于一种理想的假设情况下,这就是数据仓库的度量(事实记录)与度量的环境(维度记录)同时出现在数据仓库中.当同时拥有事实记录和正确的当前维度行时,就能够从容地首先维护维 ...
- HAWQ取代传统数仓实践(十三)——事实表技术之周期快照
一.周期快照简介 周期快照事实表中的每行汇总了发生在某一标准周期,如一天.一周或一月的多个度量.其粒度是周期性的时间段,而不是单个事务.周期快照事实表通常包含许多数据的总计,因为任何与事实表时间范围一 ...
- CarbonData:大数据融合数仓新一代引擎
[摘要] CarbonData将存储和计算逻辑分离,通过索引技术让存储和计算物理上更接近,提升CPU和IO效率,实现超高性能的大数据分析.以CarbonData为融合数仓的大数据解决方案,为金融转型打 ...
- 数仓day01
1. 该项目适用哪些行业? 主营业务在线上进行的一些公司,比如外卖公司,各类app(比如:下厨房,头条,安居客,斗鱼,每日优鲜,淘宝网等等) 这类公司通常要针对用户的线上访问行为.消费行为.业务操作行 ...
- 数仓建模—OneID
今天是我在上海租房的小区被封的第三天,由于我的大意,没有屯吃的,外卖今天完全点不到了,中午的时候我找到了一包快过期的肉松饼,才补充了1000焦耳的能量.但是中午去做核酸的时候,我感觉走路有点不稳,我看 ...
- 数仓1.4 |业务数仓搭建| 拉链表| Presto
电商业务及数据结构 SKU库存量,剩余多少SPU商品聚集的最小单位,,,这类商品的抽象,提取公共的内容 订单表:周期性状态变化(order_info) id 订单编号 total_amount 订单金 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
随机推荐
- AXI4的PL与PS联合设计
AXI4的PL与PS联合设计 1.实验原理 在前面的学习中,解决了如何利用一个缓冲寄存器控制另外一个寄存器的输入输出配置.接下来就是如何将PL设计直接导入到PS中实现资源互换.PS是可以通过AXI4总 ...
- NET Core使用Grpc通信(一):一元
gRPC是一个现代的开源高性能远程过程调用(RPC)框架,它可以高效地连接数据中心内和跨数据中心的服务,支持负载平衡.跟踪.运行状况检查和身份验证. gRPC通过使用 Protocol Buffers ...
- 鸿蒙HarmonyOS实战-ArkUI组件(Swiper)
一.Swiper 1.概述 Swiper可以实现手机.平板等移动端设备上的图片轮播效果,支持无缝轮播.自动播放.响应式布局等功能.Swiper轮播图具有使用简单.样式可定制.功能丰富.兼容性好等优点, ...
- Scala编译原理
1 package com.atguigu.chapter01; 2 /** 3 * 4 */ 5 //main 方法名 6 //小括号表示参数列表 7 // 参数声明方式: java -> 类 ...
- Python爬虫爬取爱奇艺、腾讯视频电影相关信息(改进版)---团队第一阶段冲刺
爱奇艺 1 import time 2 import traceback 3 import requests 4 from lxml import etree 5 import re 6 from b ...
- #Splay#洛谷 1486 [NOI2004]郁闷的出纳员
题目 分析 考虑加减工资直接打标记,查询第\(k\)多可以用平衡树, 删除有点恶心,这里考虑Splay,将需要删除的部分的后继splay到根节点并将左子树断边 代码 #include <cstd ...
- HMS Core Insights第九期直播预告——手语服务,助力沟通无障碍
[导读] 你知道吗?全球有超5%的人群正在遭受听力损失的折磨.这些听障群体由于沟通不便,在日常生活中面对着很多的困难与挑战,建立沟通无障碍环境的需求十分迫切.随着科技的发展,越来越多的人们享受到技术进 ...
- 超强阵容!HarmonyOS极客马拉松2023专家评审团来袭!
数十位重量级专家现身决赛现场,为参赛者提供多角度专业点评.12支队伍,46位选手,齐聚东莞·松山湖,围绕HarmonyOS技术特性,共同挑战36小时极限编程,谁将问鼎决赛之巅,8.3日-5日,我们拭 ...
- 新一期HarmonyOS认证正式发布,速来围观!
原文:https://mp.weixin.qq.com/s/mvXLnJM9VKTyq8mi9BfY1w,点击链接查看更多技术内容. 华为认证HarmonyOS应用开发高级工程师HCIP-Harm ...
- 在python中实现二叉树
二叉树设计 定义节点类 class Node: # 修改初始化方法 def init(self,value): self.value = value # 节点值 self.left = None # ...