如何处理分析Flink作业反压的问题?
摘要:反压是 Flink 应用运维中常见的问题,它不仅意味着性能瓶颈还可能导致作业的不稳定性。
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题。反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速。
问题场景
客户作业场景如下图所示,从DMS kafka通过DLI Flink将业务数据实时清洗存储到DWS。

其中,DMS Kafka 目标Topic 6个分区,DLI Flink作业配置taskmanager数量为12,并发数为1。
问题现象
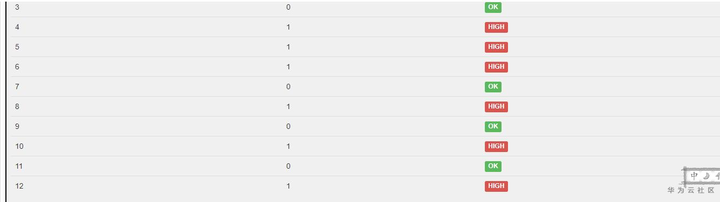
客户在DLI服务共有三个相同规格的队列,该作业在其中003号队列上运行正常,在001和002号队列上都存在严重的反压导致数据处理缓慢。作业列表显示如下图,可以看到Sink反压状态正常,Souce和Map反压状态为HIGH。

问题分析
根据反压情况分析,该作业的性能瓶颈在Sink,由于Sink处理数据缓慢导致上游反压严重。
该作业所定义的Sink类型为DwsCsvSink,该Sink的工作原理如下图所示:Sink将结果数据分片写入到OBS,每一分片写入完成后,调用DWS insert select sql将obs路径下该分片数据load到dws。
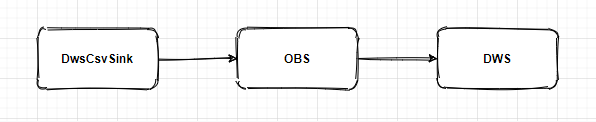
因此性能瓶颈出现在分片数据写入到OBS这一步。但问题来了,写同一个桶,为什么在不同队列上的表现不一致?
为此,我们排查了各个队列的CPU、内存和网络带宽情况,结果显示负载都很低。
这种情况下,只能继续分析FlinkUI和TaskManager日志。
数据倾斜?
然后我们在FlinkUI任务情况页面,看到如下情况:Map阶段的12个TaskManager并不是所有反压都很严重,而是只有一半是HIGH状态,难道有数据倾斜导致分配到不同TaskManager的数据不均匀?
然后看Source subTask详情,发现有两个TaskManager读取的数据量是其他几个的几十倍,这说明源端Kafka分区流入的数据量不均匀。难道就是这么简单的问题?
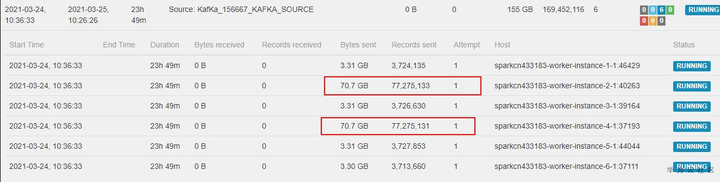
很不幸并不是,通过进一步分析源端数据我们发现Kafka 6个分区数据流入记录数相差并不大。这两个Task只是多消费了部分存量数据,接收数据增长的速度各TaskManager保持一致。
时钟同步
进一步分析TaskManager日志,我们发现单个分片数据写入OBS竟然耗费3min以上。这非常异常,要知道单个分片数据才500000条而已。
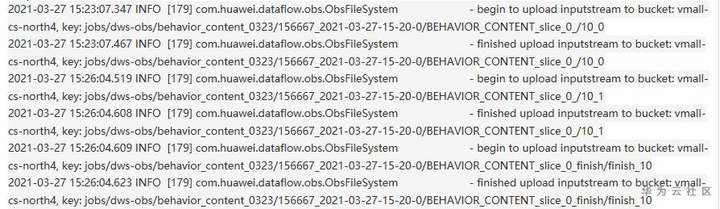
进一步通过分析代码发现如下问题:在写OBS数据时,其中一个taskmanager写分片目录后获取该目录的最后修改时间,作为处理该分片的开始时间,该时间为OBS服务端的时间。

后续其他taskmanager向该分片目录写数据时,会获取本地时间与分片开始时间对比,间隔大于所规定的转储周期才会写分片数据。
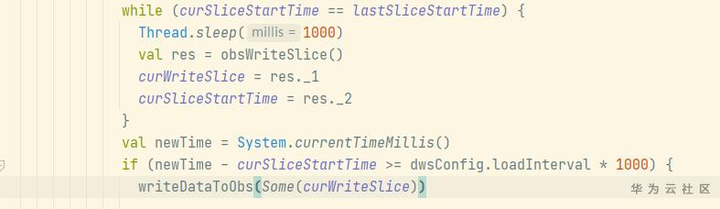
如果集群节点NTP时间与OBS服务端不同步,本地时间晚于OBS服务端时间,则会造成写入OBS等待。
后续排查集群节点,发现6个节点中一半时间同步有问题,这也和只有一半taskmanager反压严重的现象相对应。
问题修复
在集群节点上执行如下命令,强制时间同步。
systemctl stop ntp
ntpdate ntp.myhuaweicloud.com
systemctl start ntp
systemctl status ntp
date
NTP同步后,作业反压很快消失,故障恢复。

本文分享自华为云社区《一个Flink作业反压的问题分析》,原文作者:Yunz Bao 。
如何处理分析Flink作业反压的问题?的更多相关文章
- 如何分析及处理 Flink 反压?
反压(backpressure)是实时计算应用开发中,特别是流式计算中,十分常见的问题.反压意味着数据管道中某个节点成为瓶颈,处理速率跟不上上游发送数据的速率,而需要对上游进行限速.由于实时计算应用通 ...
- Flink中发送端反压以及Credit机制(源码分析)
上一篇<Flink接收端反压机制>说到因为Flink每个Task的接收端和发送端是共享一个bufferPool的,形成了天然的反压机制,当Task接收数据的时候,接收端会根据积压的数据量以 ...
- 一文搞懂 Flink 网络流控与反压机制
https://www.jianshu.com/p/2779e73abcb8 看完本文,你能get到以下知识 Flink 流处理为什么需要网络流控? Flink V1.5 版之前网络流控介绍 Flin ...
- 咱们从头到尾讲一次 Flink 网络流控和反压剖析
本文根据 Apache Flink 系列直播整理而成,由 Apache Flink Contributor.OPPO 大数据平台研发负责人张俊老师分享.主要内容如下: 网络流控的概念与背景 TCP的流 ...
- Flink 反压 浅入浅出
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- [转帖]实时流处理系统反压机制(BackPressure)综述
实时流处理系统反压机制(BackPressure)综述 https://blog.csdn.net/qq_21125183/article/details/80708142 2018-06-15 19 ...
- Flink中接收端反压以及Credit机制 (源码分析)
先上一张图整体了解Flink中的反压 可以看到每个task都会有自己对应的IG(inputgate)对接上游发送过来的数据和RS(resultPatation)对接往下游发送数据, 整个反压机制通 ...
- flink - 反压
http://wuchong.me/blog/2016/04/26/flink-internals-how-to-handle-backpressure/ https://ci.apache.org/ ...
- 1、flink介绍,反压原理
一.flink介绍 Apache Flink是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态计算. 可部署在各种集群环境,对各种大小的数据规模进行快速计算. 1.1.有界数据流和无界 ...
- flink反压的监控
反压在流式系统中是一种非常重要的机制,主要作用是当系统中下游算子的处理速度下降,导致数据处理速率低于数据接入的速率时,通过反向背压的方式让数据接入的速率下降,从而避免大量数据积压在flink系统中,最 ...
随机推荐
- 合唱队形(lgP1091)
思路: 先从左到右求一遍最长不下降子序列,再同样方法从右到左求一遍. 然后我们枚举分界点,则总人数就是左边一半加上右边一半的人数. 取最大值,输出答案. 见注释. #include<bits/s ...
- fread实现getchar(加速!!!)
fread实现的getchar代码: inline char get() { static char buf[100000], *p1 = buf, *p2 = buf; return p1 == p ...
- Electron原生菜单
.markdown-body { color: rgba(56, 56, 56, 1); font-size: 15px; line-height: 30px; letter-spacing: 2px ...
- C#操作Microsoft.Office.Interop.Word类库完整例子
使用Microsoft.Office.Interop.Word类库操作wor文档 一.准备工作 首先在工厂中,引用[Microsoft.Office.Interop.Word],本地安装了world, ...
- 为React Ant-Design Table增加字段设置
最近做的几个项目经常遇到这样的需求,要在表格上增加一个自定义表格字段设置的功能.就是用户可以自己控制那些列需要展示. 在几个项目里都实现了一遍,每个项目的需求又都有点儿不一样,迭代了很多版,所以抽时间 ...
- 大白话说Python+Flask入门(二)
写在前面 笔者技术真的很一般,也许只靠着笨鸟先飞的这种傻瓜坚持,才能在互联网行业侥幸的生存下来吧! 为什么这么说? 我曾不止一次在某群,看到说我写的东西一点技术含量都没有,而且很没营养,换作一年前的我 ...
- Webpack.devServer 配置项如何使用?附devServer完整示例
前言: 我们在平常本地开发时,可能经常需要与后端进行联调,或者调用一些api,但是由于浏览器跨域的限制.开发与生产环境的差异.http与https等问题经常让联调的过程不够顺畅.所以本文介绍一下web ...
- 【Javaweb】Servlet十 | HttpServletResponse类和HttpServletRequest类
HttpServletResponse类的作用 HttpServletResponse类和HttpServletRequest类一样.每次请求进来,Tomcat服务器都会创建一个Response对象传 ...
- .net中优秀依赖注入框架Autofac看一篇就够了
Autofac 是一个功能丰富的 .NET 依赖注入容器,用于管理对象的生命周期.解决依赖关系以及进行属性注入.本文将详细讲解 Autofac 的使用方法,包括多种不同的注册方式,属性注入,以及如何使 ...
- JavaWeb开发-CSS基础
2.CSS层叠样式表基本语法 层叠样式表,用来控制页面的样式 (1)CSS的三种引入方式 内部样式表:适合学习使用,将CSS代码写在style标签里面,style标签嵌套在title里 外部样式表:开 ...