RepVGG:VGG,永远的神! | CVPR 2021
RepVGG将训练推理网络结构进行独立设计,在训练时使用高精度的多分支网络学习权值,在推理时使用低延迟的单分支网络,然后通过结构重参数化将多分支网络的权值转移到单分支网络。RepVGG性能达到了SOTA,思路简单新颖,相信可以在上面做更多的工作来获得更好的性能。
来源:晓飞的算法工程笔记 公众号
论文: RepVGG: Making VGG-style ConvNets Great Again

Introduction
目前,卷积网络的研究主要集中在结构的设计。复杂的结构尽管能带来更高的准确率,但也会带来推理速度的减慢。影响推理速度的因素有很多,计算量FLOPs往往不能准确地代表模型的实际速度,计算量较低的模型不一定计算更快。因此,VGG和ResNet依然在很多应用中得到重用。
基于上述背景,论文提出了VGG风格的单分支网络结构RepVGG,能够比结构复杂的多分支网络更优秀,主要包含以下特点:
- 模型跟VGG类似,不包含任何分支,无需保存过多的中间结果,内存占用少。
- 模型仅包含\(3\times 3\)卷积和ReLU,计算速度快。
- 具体的网络结构(包括深度和宽度)不需要依靠自动搜索、人工调整以及复合缩放等复杂手段进行设计,十分灵活。
当然,想要直接训练简单的单分支网络来达到与多分支网络一样的精度是很难的。由于多分支网络中的各个分支在训练时的权重变化不定,所以多分支网络可看作是大量简单网络的合集,而且其能够避免训练时的梯度弥散问题。虽然如此,但多分支网络会损害速度,所以论文打算训练时采用多分支网络,而推理时仍然使用单分支网络,通过新颖的结构性重参数化(structural re-parameterization)将多分支网络的权值转移到简单网络中。
Building RepVGG via Structural Re-param
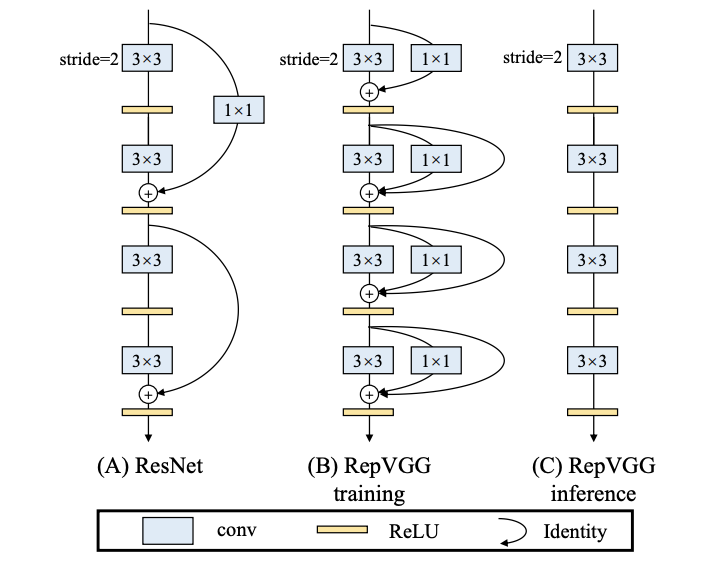
Training-time Multi-branch Architecture
由于多分支的存在,使得多分支网络相当于一个包含大量小网络的集合,但其推理速度会有较大影响,所以论文仅在训练时使用多分支进行训练,训练完成后将其权值转移到简单网络中。为了够包含大量更简单的模型,论文在\(3\times 3\)卷积的基础上添加ResNet-like的identity分支和\(1\times 1\)分支构成building block,然后堆叠成训练模型。假设多分支网络包含\(n\)个building block,则其可以表达\(3^n\)种简单网络结构。
Re-param for Plain Inference-time Model
在开始描述最重要的权值转换之前,先进行以下定义:
- 定义\(3\times 3\)卷积为\(W^{(3)}\in \mathbb{R}^{C_2\times C_1\times 3\times 3}\),\(1\times 1\)卷积为\(W^{(1)}\in \mathbb{R}^{C_2\times C_1}\)。
- 定义\(\mu^{(3)}\)、\(\sigma^{(3)}\)、\(\gamma^{(3)}\)和\(\beta^{(3)}\)为跟在\(3\times 3\)卷积后面的BN层的累计均值、标准差、学习到的缩放因子和偏置,跟在\(1\times 1\)卷积后面的BN层的参数为\(\mu^{(1)}\)、\(\sigma^{(1)}\)、\(\gamma^{(1)}\)和\(\beta^{(1)}\),跟在identity分支后面的BN层参数为\(\mu^{(0)}\)、\(\sigma^{(0)}\)、\(\gamma^{(0)}\)和\(\beta^{(0)}\)。
- 定义输入为\(M^{(1)}\in \mathbb{R}^{N\times C_1\times H_1\times W_1}\),输出为\(M^{(2)}\in \mathbb{R}^{N\times C_c\times H_2\times W_2}\)。
- 定义\(*\)为卷积操作。
假设\(C_1=C_2\)、\(H_1=H_2\)以及\(W_1=W_2\),则有:

若输入输出维度不相同,则去掉identity分支,即只包含前面两项。\(bn\)代表是推理时的BN函数,一般而言,对于\(\forall 1\leq i \leq C_2\),有:

权值转换的核心是将BN和其前面的卷积层转换成单个包含偏置向量的卷积层。假设\(\{W^{'}, b^{'}\}\)为从\(\{W, \mu, \sigma, \gamma, \beta\}\)转换得到的核权值和偏置,则有:

转换后的卷积操作与原本的卷积+BN操作是等价的,即:

上述的转换也可应用于identity分支,将identity mapping视作卷积核为单位矩阵的\(1\times 1\)卷积。

以上图为例,在\(C_2=C_1=2\)的情况下,将3个分支分别转换后得到1个\(3\times 3\)卷积和两个\(1\times 1\)卷积,最终的卷积偏置由3个卷积的偏置直接相加,而最终的卷积核则是将两个\(1\times 1\)卷积核加到\(3\times 3\)卷积核中心。需要注意的是,为了达到转换的目的,训练时的\(3\times 3\)卷积分支和\(1\times 1\)卷积分支需要有相同的步长,而\(1\times 1\)卷积的填充要比\(3\times 3\)卷积的小一个像素。
Architectural Specification

RepVGG是VGG风格的网络,主要依赖\(3\times 3\)卷积,但没有使用最大池化,而是使用步长为2的\(3\times 3\)卷积作为替换。RepVGG共包含5个阶段,每个阶段的首个卷积的步长为2。对于分类任务,使用最大池化和全连接层作为head,而其它任务则使用对应的head。

每个阶段的层数的设计如上表所示,除首尾两个阶段使用单层外,每个阶段的层数逐渐增加。而每个阶段的宽度则通过缩放因子\(a\)和\(b\)进行调整,通常\(b \gt a\),保证最后一个阶段能够提取更丰富的特征。为了避免第一阶段采用过大的卷积,进行了\(min(64, 64a)\)的设置。
为了进一步压缩参数,论文直接在特定的层加入分组卷积,从而达到速度和准确率之间的trade-off,比如RepVGG-A的3rd, 5th, 7th, ..., 21st层以及RepVGG-B的23rd, 25th和27th层。需要注意,这里没有对连续的层使用分组卷积,主要为了保证通道间的信息交流。
Experiment


SOTA分类在120epoch训练的性能对比。

200epoch带数据增强的分类性能对比。

对比多分支效果。

其它操作与结构重参数化的对比实验。

作为分割任务的主干网络的表现。
Conclusion
RepVGG将训练推理网络结构进行独立设计,在训练时使用高精度的多分支网络学习权值,在推理时使用低延迟的单分支网络,然后通过结构重参数化将多分支网络的权值转移到单分支网络。RepVGG性能达到了SOTA,思路简单新颖,相信可以在上面做更多的工作来获得更好的性能。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

RepVGG:VGG,永远的神! | CVPR 2021的更多相关文章
- 使用 EPPlus 封装的 excel 表格导入功能 (二) delegate 委托 --永远滴神
使用 EPPlus 封装的 excel 表格导入功能 (二) delegate 委托 --永远滴神 前言 接上一篇 使用 EPPlus 封装的 excel 表格导入功能 (一) 前一篇的是大概能用但是 ...
- RepLKNet:不是大卷积不好,而是卷积不够大,31x31卷积了解一下 | CVPR 2022
论文提出引入少数超大卷积核层来有效地扩大有效感受域,拉近了CNN网络与ViT网络之间的差距,特别是下游任务中的性能.整篇论文阐述十分详细,而且也优化了实际运行的表现,值得读一读.试一试 来源:晓飞 ...
- ICCV 2021口罩人物身份鉴别全球挑战赛冠军方案分享
1. 引言 10月11-17日,万众期待的国际计算机视觉大会 ICCV 2021 (International Conference on Computer Vision) 在线上如期举行,受到全球计 ...
- 昇腾CANN论文上榜CVPR,全景图像生成算法交互性再增强!
摘要:近日,CVPR 2022放榜,基于CANN的AI论文<Interactive Image Synthesis with Panoptic Layout Generation>强势上榜 ...
- 转载:resNet论文笔记
<Deep Residual Learning for Image Recognition>是2016年 kaiming大神CVPR的最佳论文 原文:http://m.blog.csdn. ...
- 案例分析作业——VS和VS Code
项目 内容 这个作业属于哪个课程 2021春季软件工程(罗杰 任健) 这个作业的要求在哪里 案例分析作业 我在这个课程的目标是 认真完成课程要求并提高相应能力 这个作业在哪个具体方面帮助我实现目标 学 ...
- 中文NER的那些事儿4. 数据增强在NER的尝试
这一章我们不聊模型来聊聊数据,解决实际问题时90%的时间其实都是在和数据作斗争,于是无标注,弱标注,少标注,半标注对应的各类解决方案可谓是百花齐放.在第二章我们也尝试通过多目标对抗学习的方式引入额外的 ...
- PTA-德州扑克 题解
于2020/02/24记录. 德州扑克属实是个带难题.本题解简单易懂,命名合理,应该比较好理解. 题目如下: 最近,阿夸迷于德州扑克.所以她找到了很多人和她一起玩.由于人数众多,阿夸必须更改游戏规则: ...
- OI滚粗记
1) 第一次接触OI是在初一,现在算下都四年了,最开始还是用的Pascal,而现在,Pascal都快被淘汰了.四年的OI生涯让我领会了很多,虽然失去了很多,但是也收获了少,这场名叫OI的生活,我不后悔 ...
- 【Java】【设计模式 Design Pattern】单例模式 Singleton
什么是设计模式? 设计模式是在大量的实践中总结和理论化之后的最佳的类设计结构,编程风格,和解决问题的方式 设计模式已经帮助我们想好了所有可能的设计问题,总结在这些各种各样的设计模式当中,也成为GOF2 ...
随机推荐
- 探秘SuperCLUE-Safety:为中文大模型打造的多轮对抗安全新框架
探秘SuperCLUE-Safety:为中文大模型打造的多轮对抗安全新框架 进入2023年以来,ChatGPT的成功带动了国内大模型的快速发展,从通用大模型.垂直领域大模型到Agent智能体等多领域的 ...
- Java Base64编码使用介绍
Base64编码介绍 BASE64 编码是一种常用的字符编码,Base64编码本质上是一种将二进制数据转成文本数据的方案. 但base64不是安全领域下的加密解密算法.能起到安全作用的效果很差 ...
- centos7 安装vmware tool 遇到遇到 kernel-headers 问题修复
安装 vmware tool 步骤 1. cp VMwareTools-10.3.25-20206839.tar.gz 到 用户目录下 2. tar zxf VMwareTools-10.3.25-2 ...
- celery中异步延迟执行任务apply_anysc的用法
描述 首先说下异步任务执行delay()和apply_anysc()两者区别,其实两者都是执行异步任务的方法,delay是apply_anysc的简写.所以delay中传递的参数会比apply_any ...
- 华为云峰会2024,GaussDB扬帆出海,给世界一个更优选择
本文分享自华为云社区<华为云峰会2024,GaussDB扬帆出海,给世界一个更优选择>,作者:GaussDB 数据库. 2024年2月26~29日,由GSM协会主办的"2024年 ...
- Android内存优化—内存优化总结
内存优化总结 内存问题 内存抖动:导致GC导致卡顿 内存泄漏:导致频繁GC,可用内存减少 内存溢出:导致OOM 工具排查 AS中的Profiler查看内存情况,是否锯齿状,是否持续上升 MAT排查 L ...
- 图查询语言 nGQL 简明教程 vol.01 快速入门
本文旨在让新手快速了解 nGQL,掌握方向,之后可以脚踩在地上借助文档写出任何心中的 NebulaGraph 图查询. 视频 本教程的视频版在B站这里. 准备工作 在正式开始 nGQL 实操之前,记得 ...
- STL-string模拟实现
1 #pragma once 2 3 #include<iostream> 4 #include<string.h> 5 #include<assert.h> 6 ...
- Java 线程通信的应用:经典例题:生产者/消费者问题
1 package bytezero.threadcommunication; 2 3 /** 4 * 线程通信的应用:经典例题:生产者/消费者问题 5 * 6 * 7 * 8 * @author B ...
- Java 数组嵌套
1 public static void main(String[] args) 2 { 3 int[] arr = new int[] {8,6,3,1,9,5,4,7}; 4 int[] inde ...