无监督学习-K-means算法
无监督学习-K-means算法
1、 什么是无监督学习
- 一家广告平台需要根据相似的人口学特征和购买习惯将美国人口分成不同的小组,以便广告客户可以通过有关联的广告接触到他们的目标客户。
- Airbnb 需要将自己的房屋清单分组成不同的社区,以便用户能更轻松地查阅这些清单。
- 一个数据科学团队需要降低一个大型数据集的维度的数量,以便简化建模和降低文件大小。
我们可以怎样最有用地对其进行归纳和分组?我们可以怎样以一种压缩格式有效地表征数据?这都是无监督学习的目标,之所以称之为无监督,是因为这是从无标签的数据开始学习的。
2、 无监督学习包含算法
- 聚类
- K-means(K均值聚类)
- 降维
- PCA
3、 K-means原理
我们先来看一下一个K-means的聚类效果图
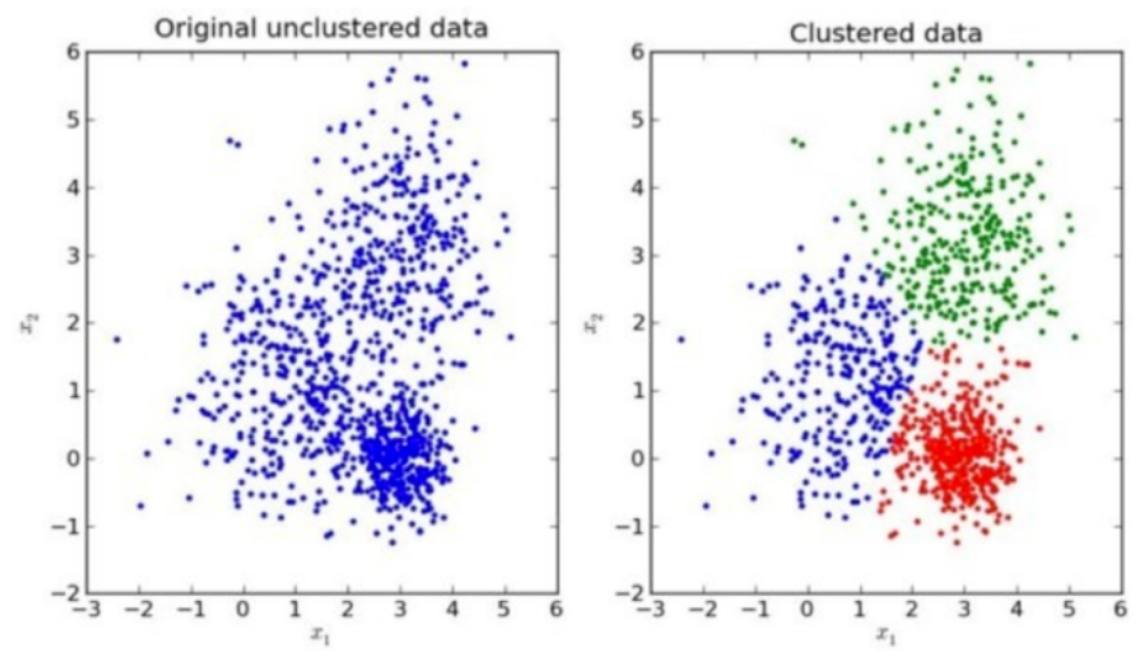
3.1 K-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样,那么结束,否则重新进行第二步过程
4、K-meansAPI
- sklearn.cluster.KMeans(n_clusters=8,init=‘k-means++’)
- k-means聚类
- n_clusters:开始的聚类中心数量 比如 n_clusters=4
- init:初始化方法,默认为'k-means ++’
- labels_:默认标记的类型,可以和真实值比较(不是值比较)
5、 案例:k-means对Instacart Market用户聚类
5.1 分析
- 1、降维之后的数据
- 2、k-means聚类
- 3、聚类结果显示
5.2 代码
# 取500个用户进行测试
# 如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
cust = data[:500]
km = KMeans(n_clusters=4)
km.fit(cust)
pre = km.predict(cust)
print(silhouette_score(cust, pre))
返回结果:
0.466014214896049
问题:如何去评估聚类的效果呢?
6、Kmeans性能评估指标
6.1 轮廓系数
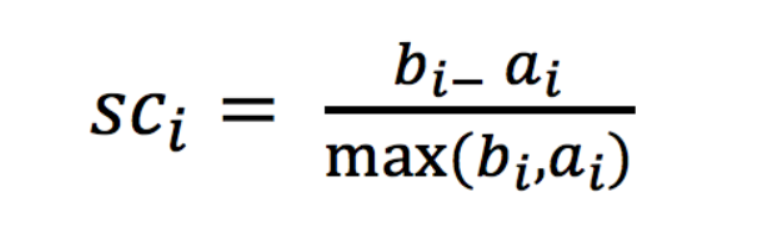
注:对于每个点i 为已聚类数据中的样本 ,b_i 为i 到其它族群的所有样本的距离最小值,a_i 为i 到本身簇的距离平均值。最终计算出所有的样本点的轮廓系数平均值
6.2 轮廓系数值分析
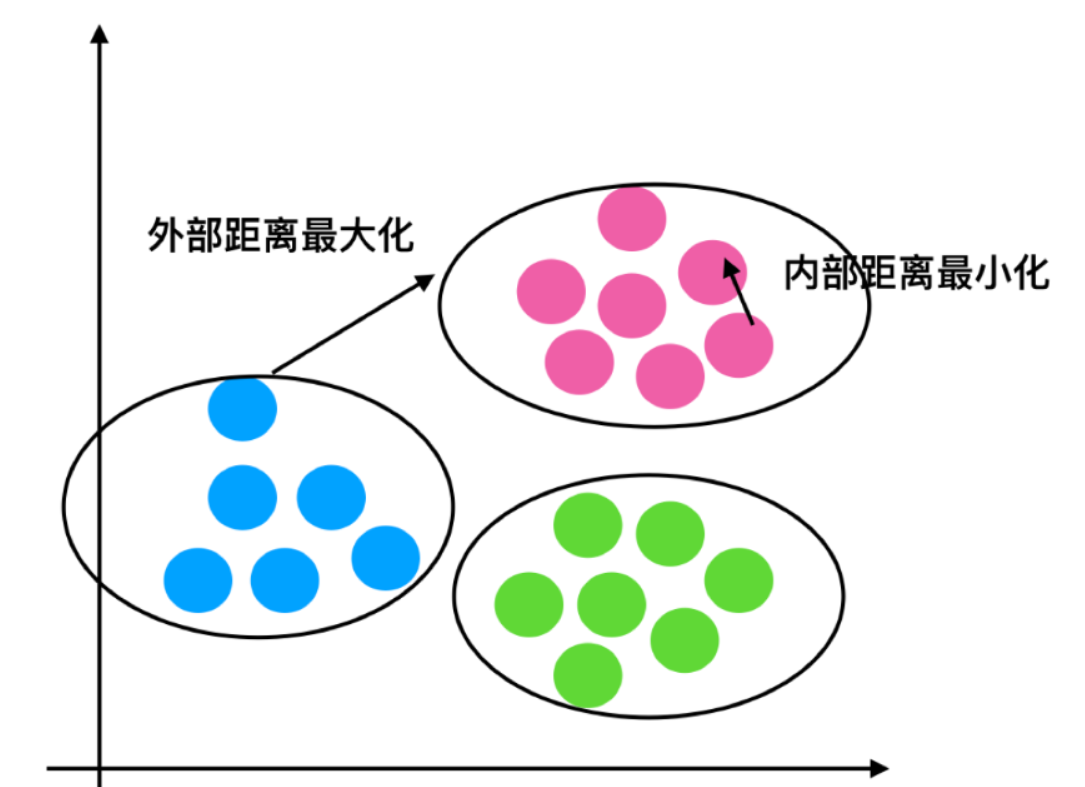
- 分析过程(我们以一个蓝1点为例)
- 1、计算出蓝1离本身族群所有点的距离的平均值a_i
- 2、蓝1到其它两个族群的距离计算出平均值红平均,绿平均,取最小的那个距离作为b_i
- 根据公式:极端值考虑:如果b_i >>a_i: 那么公式结果趋近于1;如果a_i>>>b_i: 那么公式结果趋近于-1
6.3 结论
如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
6.4 轮廓系数API
- sklearn.metrics.silhouette_score(X, labels)
- 计算所有样本的平均轮廓系数
- X:特征值
- labels:被聚类标记的目标值
6.5 用户聚类结果评估
silhouette_score(cust, pre)
7、K-means总结
- 特点分析:采用迭代式算法,直观易懂并且非常实用
- 缺点:容易收敛到局部最优解(多次聚类)
注意:聚类一般做在分类之前
案例:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
# 1、获取数据集
# ·商品信息- products.csv:
# Fields:product_id, product_name, aisle_id, department_id
# ·订单与商品信息- order_products__prior.csv:
# Fields:order_id, product_id, add_to_cart_order, reordered
# ·用户的订单信息- orders.csv:
# Fields:order_id, user_id,eval_set, order_number,order_dow, order_hour_of_day, days_since_prior_order
# ·商品所属具体物品类别- aisles.csv:
# Fields:aisle_id, aisle
from sklearn.metrics import silhouette_score
products = pd.read_csv("../instacart/products.csv")
order_products = pd.read_csv("../instacart/order_products__prior.csv")
orders = pd.read_csv("../instacart/orders.csv")
aisles = pd.read_csv("../instacart/aisles.csv")
# 2、合并表,将user_id和aisle放在一张表上
# 1)合并orders和order_products on=order_id tab1:order_id, product_id, user_id
tab1 = pd.merge(orders, order_products, on=["order_id", "order_id"])
# 2)合并tab1和products on=product_id tab2:aisle_id
tab2 = pd.merge(tab1, products, on=["product_id", "product_id"])
# 3)合并tab2和aisles on=aisle_id tab3:user_id, aisle
tab3 = pd.merge(tab2, aisles, on=["aisle_id", "aisle_id"])
# 3、交叉表处理,把user_id和aisle进行分组
table = pd.crosstab(tab3["user_id"], tab3["aisle"])
# 4、主成分分析的方法进行降维
# 1)实例化一个转换器类PCA
transfer = PCA(n_components=0.95)
# 2)fit_transform
data = transfer.fit_transform(table)
print(data.shape)
# 取500个用户进行测试
# 如果b_i>>a_i:趋近于1效果越好, b_i<<a_i:趋近于-1,效果不好。轮廓系数的值是介于 [-1,1] ,越趋近于1代表内聚度和分离度都相对较优。
cust = data[:500]
km = KMeans(n_clusters=4)
km.fit(cust)
pre = km.predict(cust)
print(silhouette_score(cust, pre))
返回结果:
(206209, 44)
0.466014214896049
几个问题:
1、线性回归的参数求解的方法是什么?
答案: 正规方程和梯度下降
2、什么是过拟合? 原因有哪些?
答案: 过拟合就是训练误差很小,但是测试误差很大
原因有: 样本偏差, 模型过于复杂
3、分类问题, 回归问题, 聚类问题的评估方法分别是什么?
答案: 分类问题的评估方法是准确率, 精确率和召回率
回归问题的评估方法是均方差
聚类问题的评估方法是轮廓系数
无监督学习-K-means算法的更多相关文章
- 监督学习——K邻近算法及数字识别实践
1. KNN 算法 K-近邻(k-Nearest Neighbor,KNN)是分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似( ...
- KNN 与 K - Means 算法比较
KNN K-Means 1.分类算法 聚类算法 2.监督学习 非监督学习 3.数据类型:喂给它的数据集是带label的数据,已经是完全正确的数据 喂给它的数据集是无label的数据,是杂乱无章的,经过 ...
- 5.无监督学习-DBSCAN聚类算法及应用
DBSCAN方法及应用 1.DBSCAN密度聚类简介 DBSCAN 算法是一种基于密度的聚类算法: 1.聚类的时候不需要预先指定簇的个数 2.最终的簇的个数不确定DBSCAN算法将数据点分为三类: 1 ...
- 监督学习--k近邻算法
2017-07-20 15:18:25 k近邻(k-Nearest Neighbour, 简称kNN)学习是一种常用的监督学习方法,其工作机制非常简单,对某个给定的测试样本,基于某种距离度量找出训练集 ...
- 无监督学习——K-均值聚类算法对未标注数据分组
无监督学习 和监督学习不同的是,在无监督学习中数据并没有标签(分类).无监督学习需要通过算法找到这些数据内在的规律,将他们分类.(如下图中的数据,并没有标签,大概可以看出数据集可以分为三类,它就是一个 ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- 机器学习基础——简单易懂的K邻近算法,根据邻居“找自己”
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天的文章给大家分享机器学习领域非常简单的模型--KNN,也就是K Nearest Neighbours算法,翻译过来很简单,就是K最近邻居 ...
- 监督学习 VS 无监督学习
监督学习 就是人们常说的分类,通过已有的训练样本(即已知数据以及其对应的输出)去训练得到一个最优模型(这个模型属于某个函数的集合,最优则表示在某个评价准则下是最佳的),再利用这个模型将所有的输入映射为 ...
- K-means算法
K-means算法很简单,它属于无监督学习算法中的聚类算法中的一种方法吧,利用欧式距离进行聚合啦. 解决的问题如图所示哈:有一堆没有标签的训练样本,并且它们可以潜在地分为K类,我们怎么把它们划分呢? ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
随机推荐
- spring boot整合spring security自定义登录跳转地址
说明 在博客用户登录后我想跳转到各自用户的博客首页,我们知道这个地址是动态的. 例如: http://localhost:8080/blog/zhangsan, 每个用户地址不一样.这时候我就用到了自 ...
- Spring源码之spring事务
目录 Spring事务 事务自定义标签 自定义标签 解析标签 bean 的初始化 InfrastructureAdvisorAutoProxyCreator 获取增强方法 获取所有增强中内适用于当前方 ...
- QT - Day 5
1 event事件 用途:用于事件的分发 也可以做拦截操作,不建议 bool event( QEvent * e); 返回值 如果是true 代表用户处理这个事件,不向下分发了 e->ty ...
- Git 分支管理参考模型
一个值得参考的Git分支管理模型如下: master 生产主分支,发布到生产环境使用这个分支,由hotfix或者release分支合并过来,不直接提交代码. release 预发布分支, 基于feat ...
- Feign入门介绍
Feign入门介绍 基本概述 除Feign之外,在Java中经常使用的HTTP客户端组件主要有3个,如下: (1)HttpURLConnection,JDK自带 (2)Apache HttpClien ...
- 2021-07-30 JavaScript中常用数据的判断
为什么要判断一个变量的常用数据? 实际业务场景里,一个变量的数据是否合法或符合预期,会影响到项目中用到的UI组件库特定组件的运行.比如element-ui中的el-select组件,单选时绑定的数据不 ...
- 图书管理系统---基于ajax删除数据
book_list.html代码 {% load static %} <!DOCTYPE html> <html lang="en"> <head&g ...
- eclipse c++ 安装
eclipse及其插件安装 对于我这种被VS惯坏了的人来说,make file 非常不友好的,最近要在redhat 下面去编译c++动态库和应用程序,原有的工程是在window下面的,要到linux下 ...
- 【Azure 应用服务】App Service 配置 Application Settings 访问Storage Account得到 could not be resolved: '*.file.core.windows.net'的报错。没有解析成对应中国区 Storage Account地址 *.file.core.chinacloudapi.cn
问题描述 App Service 配置 Application Settings 访问Storage Account.如下: { "name": "WEBSITE_CON ...
- 【代码更新】SPI时序——AD数模数转换
[代码更新]SPI时序--AD数模数转换 AD芯片手册:https://www.ti.com.cn/cn/lit/ds/symlink/ads8558.pdf?ts=1709473143911& ...