Python分组数据并保存到单独的文件中
当处理大型数据集时,通常需要将数据分组,并将每个分组的数据保存到单独的文件中。下面是一个使用 Python 中的 pandas 库来实现这一目标的示例代码。
步骤 1: 导入所需的库
import os
import pandas as pd
步骤 2: 读取 Excel 数据
# 读取 Excel 数据
df = pd.read_excel("C:\\Users\\liuchunlin2\\Desktop\\新建XLSX 工作表.xlsx")
步骤 3: 根据指定字段分组数据
# 根据学校、班级、老师字段分组
grouped = df.groupby(['学校', '班级', '老师'])
步骤 4: 创建保存拆分数据的文件夹
# 新建文件夹路径
folder_path = "C:\\Users\\liuchunlin2\\Desktop\\拆分数据"
os.makedirs(folder_path, exist_ok=True) # 检查文件夹是否存在,若不存在则创建
步骤 5: 遍历分组数据并保存到不同的 Excel 文件中
# 遍历分组,并将每个分组的数据保存到不同的 Excel 文件中
for name, group in grouped:
school, grade, teacher = name
filename = f"{school}_{grade}_{teacher}.xlsx"
file_path = os.path.join(folder_path, filename)
group.to_excel(file_path, index=False)
创建一个简单的图形用户界面,用于选择 Excel 文件并指定分组列,然后将数据按照分组保存到不同的 Excel 文件中
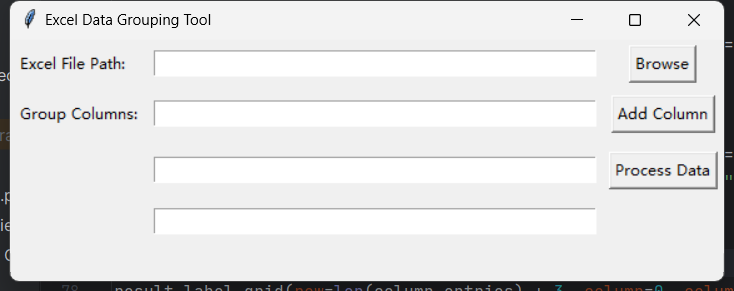
步骤 1: 导入所需的库
import tkinter as tk # 导入 tkinter 模块,用于创建图形用户界面
from tkinter import filedialog # 导入 filedialog 子模块,用于打开文件对话框
import pandas as pd # 导入 pandas 库,用于数据处理
import os # 导入 os 模块,用于文件和目录操作
步骤 2: 定义函数,用于打开文件对话框并选择 Excel 文件路径
def browse_file():
# 打开文件对话框,限定文件类型为 Excel 文件 (*.xlsx)
filepath = filedialog.askopenfilename(filetypes=[("Excel files", "*.xlsx")])
# 清空文件路径输入框,并将选定的文件路径插入到输入框中
file_entry.delete(0, tk.END)
file_entry.insert(0, filepath)
步骤 3: 定义函数,用于处理数据并将其按指定列分组保存为多个 Excel 文件
def process_data():
# 获取输入文件路径和需要分组的列名
input_file = file_entry.get()
group_columns = [column_entry.get() for column_entry in column_entries if column_entry.get()] # 检查输入是否完整
if not input_file or not group_columns:
result_label.config(text="Please provide input file path and group columns.")
return try:
# 读取 Excel 文件为 DataFrame,并按指定列进行分组
df = pd.read_excel(input_file)
grouped = df.groupby(group_columns) # 创建用于存储分组数据的文件夹
folder_name = "Splitted_Data"
if not os.path.exists(folder_name):
os.makedirs(folder_name) # 将每个分组的数据保存为单独的 Excel 文件
for name, group in grouped:
filename = f"{folder_name}/{'_'.join(name)}.xlsx"
group.to_excel(filename, index=False) result_label.config(text="Data processing completed successfully.")
except Exception as e:
result_label.config(text=f"Error occurred: {str(e)}")
步骤 4: 创建 tkinter 窗口对象并设置标题
root = tk.Tk()
root.title("Excel Data Grouping Tool") # 设置窗口标题
步骤 5: 创建标签和输入框,用于显示和输入 Excel 文件路径
file_label = tk.Label(root, text="Excel File Path:")
file_label.grid(row=0, column=0, padx=5, pady=5, sticky="w")
file_entry = tk.Entry(root, width=50)
file_entry.grid(row=0, column=1, padx=5, pady=5, sticky="we")
browse_button = tk.Button(root, text="Browse", command=browse_file)
browse_button.grid(row=0, column=2, padx=5, pady=5)
步骤 6: 创建标签、输入框和按钮,用于指定分组列名
column_label = tk.Label(root, text="Group Columns:")
column_label.grid(row=1, column=0, padx=5, pady=5, sticky="w")
column_entry = tk.Entry(root, width=50)
column_entry.grid(row=1, column=1, padx=5, pady=5, sticky="we")
column_entries = [column_entry] add_column_button = tk.Button(root, text="Add Column", command=lambda: add_column_entry())
add_column_button.grid(row=1, column=2, padx=5, pady=5)
步骤 7: 创建函数,用于添加新的分组列输入框
def add_column_entry():
new_column_entry = tk.Entry(root, width=50)
new_column_entry.grid(row=len(column_entries) + 1, column=1, padx=5, pady=5, sticky="we")
column_entries.append(new_column_entry)
步骤 8: 创建按钮,用于处理数据
process_button = tk.Button(root, text="Process Data", command=process_data)
process_button.grid(row=2, column=2, padx=5, pady=10, sticky="e") # 调整位置至右侧
步骤 9: 创建标签,用于显示处理结果信息
result_label = tk.Label(root, text="")
result_label.grid(row=len(column_entries) + 3, column=0, columnspan=3, padx=5, pady=5)
步骤 10: 启动主事件循环
root.mainloop()
完整代码:
import tkinter as tk # 导入 tkinter 模块,用于创建图形用户界面
from tkinter import filedialog # 导入 filedialog 子模块,用于打开文件对话框
import pandas as pd # 导入 pandas 库,用于数据处理
import os # 导入 os 模块,用于文件和目录操作 # 定义函数,用于打开文件对话框并选择 Excel 文件路径
def browse_file():
# 打开文件对话框,限定文件类型为 Excel 文件 (*.xlsx)
filepath = filedialog.askopenfilename(filetypes=[("Excel files", "*.xlsx")])
# 清空文件路径输入框,并将选定的文件路径插入到输入框中
file_entry.delete(0, tk.END)
file_entry.insert(0, filepath) # 定义函数,用于处理数据并将其按指定列分组保存为多个 Excel 文件
def process_data():
# 获取输入文件路径和需要分组的列名
input_file = file_entry.get()
group_columns = [column_entry.get() for column_entry in column_entries if column_entry.get()] # 检查输入是否完整
if not input_file or not group_columns:
result_label.config(text="Please provide input file path and group columns.")
return try:
# 读取 Excel 文件为 DataFrame,并按指定列进行分组
df = pd.read_excel(input_file)
grouped = df.groupby(group_columns) # 创建用于存储分组数据的文件夹
folder_name = "Splitted_Data"
if not os.path.exists(folder_name):
os.makedirs(folder_name) # 将每个分组的数据保存为单独的 Excel 文件
for name, group in grouped:
filename = f"{folder_name}/{'_'.join(name)}.xlsx"
group.to_excel(filename, index=False) result_label.config(text="Data processing completed successfully.")
except Exception as e:
result_label.config(text=f"Error occurred: {str(e)}") # 创建 tkinter 窗口对象
root = tk.Tk()
root.title("Excel Data Grouping Tool") # 设置窗口标题 # 创建标签和输入框,用于显示和输入 Excel 文件路径
file_label = tk.Label(root, text="Excel File Path:")
file_label.grid(row=0, column=0, padx=5, pady=5, sticky="w")
file_entry = tk.Entry(root, width=50)
file_entry.grid(row=0, column=1, padx=5, pady=5, sticky="we")
browse_button = tk.Button(root, text="Browse", command=browse_file)
browse_button.grid(row=0, column=2, padx=5, pady=5) # 创建标签、输入框和按钮,用于指定分组列名
column_label = tk.Label(root, text="Group Columns:")
column_label.grid(row=1, column=0, padx=5, pady=5, sticky="w")
column_entry = tk.Entry(root, width=50)
column_entry.grid(row=1, column=1, padx=5, pady=5, sticky="we")
column_entries = [column_entry] add_column_button = tk.Button(root, text="Add Column", command=lambda: add_column_entry())
add_column_button.grid(row=1, column=2, padx=5, pady=5) # 创建函数,用于添加新的分组列输入框
def add_column_entry():
new_column_entry = tk.Entry(root, width=50)
new_column_entry.grid(row=len(column_entries) + 1, column=1, padx=5, pady=5, sticky="we")
column_entries.append(new_column_entry) # 创建按钮,用于处理数据
process_button = tk.Button(root, text="Process Data", command=process_data)
process_button.grid(row=2, column=2, padx=5, pady=10, sticky="e") # 调整位置至右侧 # 创建标签,用于显示处理结果信息
result_label = tk.Label(root, text="")
result_label.grid(row=len(column_entries) + 3, column=0, columnspan=3, padx=5, pady=5) # 启动主事件循环
root.mainloop()
Python分组数据并保存到单独的文件中的更多相关文章
- Flex4学习笔记2--代码保存在单独的文件中
1 <!--调用外部as文件--> <fx:Script> <![CDATA[ import mx.controls.Alert; import a.Test3; ]]& ...
- python 合并两个文件并将合并内容保存在另一个文件中
简单地文件合并方法 思路如下: 分别读取两个文件中的内容,并将其保存在一个列表中,将列表通过join()函数转为字符,并将新字符保存在新的文件中. 其中,test1.txt中的内容为: test2.t ...
- MATLAB实例:新建文件夹,保存.mat文件并保存数据到.txt文件中
MATLAB实例:新建文件夹,保存.mat文件并保存数据到.txt文件中 作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 用MATLAB实现:指定路径下 ...
- python数据可视化-matplotlib入门(6)-从文件中加载数据
前几篇都是手动录入或随机函数产生的数据.实际有许多类型的文件,以及许多方法,用它们从文件中提取数据来图形化. 比如之前python基础(12)介绍打开文件的方式,可直接读取文件中的数据,扩大了我们的数 ...
- 保存文件名至txt文件中,不含后缀
准备深度学习的训练数据时,可能会用到将图片文件名保存到txt文件中,所以用python实现了该功能.输入参数只设了两个,图片存放路径,和输出的txt文件名. 代码里写死了只识别.jpg格式,并不进行目 ...
- java web 通过前台输入的数据(name-value)保存到后台 xml文件中
一:项目需求,前端有一个页面,页面中可以手动输入一些参数数据,通过点击前端的按钮,使输入的数据保存到后台生成的.xml文件中 二:我在前端使用的是easyui的propertygrid,这个能通过da ...
- 将Json数据保存在静态脚本文件中读取
一些常用的数据例如一些网站的区域信息被改变的可能性不大,一般不通过请求获取,于是我们选择存在静态文件中,例如以下Demo: 1.动态加载Json数据显示到前台 [HttpPost] public Ac ...
- 吴裕雄--天生自然python学习笔记:python文档操作批量替换 Word 文件中的文字
我们经常会遇到在不同的 Word 文件中的需要做相同的文字替换,若是一个一个 文件操作,会花费大量时间 . 本节案例可以找出指定目录中的所有 Word 文件(包含 子目录),并对每一个文件进行指定的文 ...
- 合并csv文件保存到一个csv文件中-保留表头
主要实现功能: 在同一文件夹下的所有csv文件全部合并到同一个csv文件中,并将csv文件的表头保留 1 import os 2 import pandas as pd 3 path = os.get ...
- Log4j分级别保存日志到单个文件中,并记录IP和用户信息
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE log4j:configuration S ...
随机推荐
- Python2升级到Python3
操作系统环境:CentOS Linux release 7.4.1708 (Core). 系统默认Python版本为2.7. 升级前的版本信息: [root@cch-spider-web1 ~]# l ...
- cookie和服务器Session的区别
cookie和服务器Session的区别 cookie和服务器Session都可用来存储用户信息,cookie存放于客户端,Session存放于web服务器端. 因为cookie存放于客户端有可能被窃 ...
- 对find命令结果进行操作
# find匹配到一些文件后,可能希望对其进行一些操作,这时就可以使用-exec选项,exec选项后面跟着所要执行的命令,然后是一对{},一个空格和一个\,最后是一个分号; find . -type ...
- 【会员题】253. 会议室 II
会议室II 给定一个会议时间安排的数组,每个会议时间都会包括开始和结束的时间s1,e1,s2,e2]..](si<ei) ,为避免会议冲突,同时要考虑充分 利用会议室资源,请你计算至少需要多少间 ...
- 如何在矩池云复现开源对话语言模型 ChatGLM
ChatGLM-6B 是一个开源的.支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数.结合模型量化技术,用户可以在消费级的显卡上进行 ...
- github.com/json-iterator/go 详细教程
最近接触到了 github.com/json-iterator/go , 是由滴滴开源的第三方json编码库,它同时提供Go和Java两个版本. 文中大量内容来自 github 上的 wiki 文档, ...
- 【Azure Developer】Java代码访问Key Vault Secret时候的认证问题,使用 DefaultAzureCredentialBuilder 或者 ClientSecretCredentialBuilder
问题描述 使用Java SDK获取Key Vault Secret机密信息时,需要获取授权.通常是使用AAD的注册应用(Client ID, Tenant ID, Client Secret)来获取 ...
- 【Azure 环境】 介绍两种常规的方法来监视Window系统的CPU高时的进程信息: Performance Monitor 和 Powershell Get-Counter
问题描述 部署在Azure上的VM资源,偶尔CPU飙高,但是发现的时候已经恢复,无法判断当时High CPU原因. 在Windows系统中,有什么方式能记录CPU被进程占用情况,查找出当时是排名前列的 ...
- 使用OpenFeign远程调用时请求头处理报错问题
1. 错误信息 basic.result.exception.OtherException: feign error:系统异常:Content type 'multipart/form-data;bo ...
- 使用python连接hive数仓
1 版本参数 查看hadoop和hive的版本号 ls -l /opt # 总用量 3 # drwxr-xr-x 11 root root 227 1月 26 19:23 hadoop-3.3.6 # ...