数仓调优实战:GUC参数调优
本文分享自华为云社区《GaussDB(DWS)性能调优系列实战篇七:十八般武艺之GUC参数调优》,作者: 黎明的风。
1. 前言
- 适用版本:【8.1.1及以上】
GaussDB(DWS)性能调优系列专题文章,介绍了数据库性能调优的思路和总体策略。在系统级调优中数据库全局的GUC参数对整体性能的提升至关重要,而在语句级调优中GUC参数可以调整估算模型,选择查询计划中算子的类型,或者选择不同的执行计划。因此在SQL调优过程中合理的设置GUC参数十分重要。
2. 优化器GUC参数调优
在GaussDB(DWS)中,SQL语句的执行所需要经历的步骤如下图所示,其中红色部分为DBA可以介入实施调优的环节。
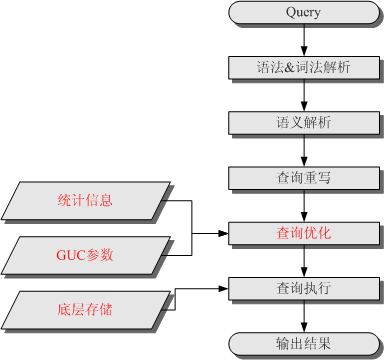
查询计划的生成是基于一定的模型和统计信息进行代码估算,在某些场景由于统计信息不准确或者代价估算有偏差时,就需要通过GUC参数设置的的方式选择更优的查询计划。
在GaussDB(DWS)中,和SQL执行性能相关的GUC参数主要有以下几个:
- best_agg_plan: 进行聚集计算模型的设置
- enable_sort: 控制优化器是否使用的排序,主要用于让优化器选择使用HashAgg来实现聚集操作
- enable_hashagg:控制优化器是否使用HashAgg来实现聚集操作
- enable_force_vector_engine:开启参数后强制生成向量化的执行计划
- query_dop:用户自定义的查询并行度
2.1 best_agg_plan参数
GaussDB(DWS)是分布式的数据库集群,数据计算尽量在各个DN上并行计算,可以得到最优的性能,在Stream框架下Agg操作可以分为两个场景。
Agg下层算子输出结果集的分布列是Group By列的子集。
这种场景,直接对下层结果集进行汇聚的结果就是正确的汇聚结果,生成算子直接使用即可。例如以下语句,lineitem的分布列是l_orderkey,它是Group By的列。
select
l_orderkey,
count(*) as count_order
from
lineitem
group by
l_orderkey;
查询计划如下:
Agg下层算子输出结果集的分布列不是Group By列的子集。
对于这种场景Stream下的聚集(Agg)操作,优化器可以生成以下三种形态的查询计划:
- hashagg+gather(redistribute)+hashagg
- redistribute+hashagg(+gather)
- hashagg+redistribute+hashagg(+gather)
通常优化器总会选择最优的执行计划,但是众所周知代价估算,尤其是中间结果集的代价估算有时会有比较大的偏差。这种比较大的偏差就可能会导致聚集(agg)的计算方式出现比较大的偏差,这时候就需要通过best_agg_plan参数进行聚集计算模型的干预。
以下通过TPC-H Q1语句分析三种形态的查询计划:
-- TPC-H Q1
select
l_returnflag,
l_linestatus,
sum(l_quantity) as sum_qty,
sum(l_extendedprice) as sum_base_price,
sum(l_extendedprice * (1 - l_discount)) as sum_disc_price,
sum(l_extendedprice * (1 - l_discount) * (1 + l_tax)) as sum_charge,
avg(l_quantity) as avg_qty,
avg(l_extendedprice) as avg_price,
avg(l_discount) as avg_disc,
count(*) as count_order
from
lineitem
where
l_shipdate <= date '1998-12-01' - interval '90' day (3)
group by
l_returnflag,
l_linestatus
order by
l_returnflag,
l_linestatus;
}
当best_agg_plan=1时,在DN上进行了一次聚集,然后结果通过GATHER算子汇总到CN上进行了二次聚集,对应的查询计划如下:
该方法适用于DN第一次聚集后结果集较少并且DN数较少的场景,在CN上进行第二次聚集时的结果集小,CN不会成为计算瓶颈。
当best_agg_plan=2时,在DN上先按照Group By的列进行数据重分布,然后在DN上进行聚集操作,将汇总的结果返回给CN,对应的查询计划如下:
该方法适用于DN第一次聚集后结果集缩减不明显的场景,因为这样可以省略DN上的第一次聚集操作。
当best_agg_plan=3时,在DN上进行一次聚集,然后将聚集结果按照Group By的列进行数据重分布,之后在DN上进行二次聚集得到结果,对应的查询计划如下:
该方法使用于DN第一次聚集后中间结果缩减明显,但最终结果行数比较大的场景。
GaussDB(DWS)中,以上三种方法的选择是根据代价来自动选择。在实际的SQL调优时,如果遇到有聚集方式不合理的场景,可以通过尝试设置best_agg_plan参数,选择最优的聚集方式。
2.2 enable_sort参数
GaussDB(DWS)中实现分组聚集操作有两种方法:
- HashAgg:使用Hash表对数据进行去重,并同时进行聚集操作,适用于聚集后行数缩减较多的场景。
- Sort + GroupAgg:首先对数据进行排序,然后遍历排序后的数据,完成去重和聚集操作,适用于聚集后行数缩减较少的场景。
以下面的SQL为例:
select
l_orderkey,
count(*) as count_order
from
lineitem
group by
l_orderkey;
如果使用Sort + GroupAgg的方式,在Sort排序算子里执行时间比较长,因为需要对大量数据进行排序操作。
以上这种场景,可以关闭enable_sort参数,选择使用HashAgg的方式来实现聚集操作,可以获得较好的执行性能。
2.3 enable_hashagg参数
GaussDB(DWS)中通过count distinct来统计多个列的数据时,通常会使用HashAgg来实现每一个列的统计聚集操作,然后将结果通过Join方式关联起来得到最终结果。
以下面的SQL为例:
select
l_orderkey,
count(distinct l_partkey) as count_partkey,
count(distinct l_suppkey) as count_suppkey,
count(distinct l_linenumber) as count_linenumber,
count(distinct l_returnflag) as count_returnflag,
count(distinct l_linestatus) as count_linestatus,
count(distinct l_shipmode) as count_shipmode
from
lineitem
group by
l_orderkey;
从查询计划来看,通过count distinct统计了lineitem表中的6列数据,是通过6个HashAgg操作来实现的,该SQL执行时消耗的资源相对较高。
如果关闭enable_hashagg参数,优化器会选择Sort + GroupAgg的方式,该SQL执行时消耗的资源相对较少。
在应用开发时,可以根据SQL并发和资源使用情况,通过设置enable_hashagg参数来选择合适的执行计划。
2.4 enable_force_vector_engine参数
GaussDB(DWS)支持行存储和列存储两种存储模型,用户可以根据应用场景,建表的时候选择行存储还是列存储表。向量化执行将传统的执行模式由一次一元组的模型修改为一次一批元组,配合列存特性,可以带来巨大的性能提升。
如果使用行存表或者是行列混存的场景,由于行存表默认走的是行存执行引擎,最终查询无法走向量化执行引擎。
以下面的SQL为例:
select
l_orderkey,
sum(l_extendedprice * (1 - l_discount)) as revenue,
o_orderdate,
o_shippriority
from
customer_row,
orders,
lineitem
where
c_mktsegment = 'BUILDING'
and c_custkey = o_custkey
and l_orderkey = o_orderkey
and o_orderdate < date '1995-03-15'
and l_shipdate > date '1995-03-15'
group by
l_orderkey,
o_orderdate,
o_shippriority
order by
revenue desc,
o_orderdate
limit 10;
SQL语句中的customer_row表为行存表,orders和lineitem为列存表,该场景在默认参数的情况下无法走向量化引擎,Row Adapter算子表示将列存数据转为行存数据,对应的查询计划为:
这种场景,可以选择开启enable_force_vector_engine参数,通过向量化执行引擎来执行,Vector Adapter算子表示将行存数据转换为列存数据,每个算子前面的Vector表示改算子为向量化引擎的执行器算子,对应的查询计划为:
从上述计划可以看出,向量化引擎相比行执行引擎,执行性能有数倍的提升效果。
2.5 query_dop参数
GaussDB(DWS)支持并行计算技术,当系统的CPU、内存、I/O和网络带宽等资源充足时,可以充分利用富余硬件资源,提升语句的执行速度。在GaussDB(DWS)中,通过query_dop参数,来控制语句的并行度,取值如下:
- query_dop=1,串行执行
- query_dop=[2…N],指定并行执行并行度
- query_dop=0,自适应调优,根据系统资源和语句复杂度情况自适应选择并行度
query_dop参数设置的一些原则:
- 对于短查询为主的TP类业务中,如果不能通过CN轻量化或下发语句进行业务的调优,则生成SMP计划的时间较长,建议设置query_dop=1。
- 对于AP类复杂语句的场景,建议设置query_dop=0。
- 计划并行执行之后必定会引起资源消耗的增加,当资源成为瓶颈的情况下,SMP无法提升性能,反而可能导致性能的劣化。出现资源瓶颈的情况下,建议关闭SMP,即设置query_dop=1。
设置query_dop=0可以实现自适应调优,在部分场景下语句执行的并行度没有达到最优,这种情况可以考虑通过query_dop参数设置并行度。
例如下面的SQL:
select count(*) from
(
select
l_orderkey,
count(*) as count_order
from
lineitem
group by
l_orderkey
);
在query_dop=0时使用的并行度为2。
设置query_dop=4时使用的并行度为4,执行时间相比并行度为2时有明显的提升。
3. 数据库全局GUC参数
在使用GaussDB(DWS)时,全局的GUC参数对集群整体性能影响很大,这里介绍一些常用参数以及推荐的配置。
3.1 数据内存参数
影响数据库性能的五大内存参数有:max_process_memory、shared_buffers、cstore_buffers、work_mem和maintenance_work_mem。
max_process_memory
max_process_memory是逻辑内存管理参数,主要功能是控制单个CN/DN上可用内存的最大峰值。
计算公式:max_process_memory=物理内存*0.665/(1+主DN个数)。
shared_buffers
设置DWS使用的共享内存大小。增加此参数的值会使DWS比系统默认设置需要更多的System V共享内存。
建议设置shared_buffers值为内存的40%以内。主要用于行存表scan。计算公式:shared_buffers=(单服务器内存/单服务器DN个数)0.40.25
cstore_buffers
设置列存和OBS、HDFS外表列存格式(orc、parquet、carbondata)所使用的共享缓冲区的大小。
计算公式可参考shared_buffers。
work_mem
设置内部排序操作和Hash表在开始写入临时磁盘文件之前使用的内存大小。
ORDER BY,DISTINCT和merge joins都要用到排序操作。Hash表在散列连接、散列为基础的聚集、散列为基础的IN子查询处理中都要用到。
对于复杂的查询,可能会同时并发运行好几个排序或者散列操作,每个都可以使用此参数所声明的内存量,不足时会使用临时文件。同样,好几个正在运行的会话可能会同时进行排序操作。因此使用的总内存可能是work_mem的好几倍。
计算公式:
对于串行无并发的复杂查询场景,平均每个查询有5-10关联操作,建议work_mem=50%内存/10。
对于串行无并发的简单查询场景,平均每个查询有2-5个关联操作,建议work_mem=50%内存/5。
对于并发场景,建议work_mem=串行下的work_mem/物理并发数。
maintenance_work_mem
maintenance_work_mem用来设置维护性操作(比如VACUUM、CREATE INDEX、ALTER TABLE ADD FOREIGN KEY等)中可使用的最大的内存。
当自动清理进程运行时,autovacuum_max_workers倍数的内存将会被分配,所以此时设置maintenance_work_mem的值应该不小于work_mem。
3.2 连接相关GUC参数
连接相关的参数有两个:max_connections和max_prepared_transactions
max_connections
允许和数据库连接的最大并发连接数。此参数会影响集群的并发能力。
设置建议:
CN中此参数建议保持默认值。DN中此参数建议设置为CN的个数乘以CN中此参数的值。
增大这个参数可能导致GaussDB(DWS)要求更多的System V共享内存或者信号量,可能超过操作系统缺省配置的最大值。这种情况下,请酌情对数值加以调整。
max_prepared_transactions
设置可以同时处于"预备"状态的事务的最大数目。增加此参数的值会使GaussDB(DWS)比系统默认设置需要更多的System V共享内存。
NOTICE:
max_connections取值的设置受max_prepared_transactions的影响,在设
max_connections之前,应确保max_prepared_transactions的值大于或等
max_connections的值,这样可确保每个会话都有一个等待中的预备事务。
3.3 并发控制GUC参数
max_active_statements
设置全局的最大并发数量。此参数只应用到CN,且针对一个CN上的执行作业。
需根据系统资源(如CPU资源、IO资源和内存资源)情况,调整此数值大小,使得系统支持最大限度的并发作业,且防止并发执行作业过多,引起系统崩溃。
当取值-1或者0时,不限制全局并发数。
在点查询的场景下,参数建议设置为100。
在分析类查询的场景下,参数的值设置为CPU的核数除以DN个数,一般可以设置5~8个。
3.4 其他GUC参数
bulk_write_ring_size
数据并行导入使用的环形缓冲区大小。
该参数主要影响入库性能,建议导入压力大的场景增加DN上的该参数配置。
checkpoint_completion_target
指定检查点完成的目标。
含义是每个checkpoint需要在checkpoints间隔时间的50%内完成。
默认值为0.5,为提高性能可改成0.9。
data_replicate_buffer_size
发送端与接收端传递数据页时,队列占用内存的大小。此参数会影响主备之间复制的缓冲大小。
默认值为128MB,若服务器内存为256G,可适当增大到512MB。
wal_receiver_buffer_size
备机与从备接收Xlog存放到内存缓冲区的大小。
默认值为64MB,若服务器内存为256G,可适当增大到128MB
4. 总结
本篇文章主要介绍了GaussDB(DWS)性能调优涉及到的优化器和系统级GUC参数,通过合理配置这些GUC参数,能够充分利用好CPU、内存、磁盘IO和网络IO等资源,提升语句的执行性能和GaussDB(DWS)集群的整体性能。
5. 参考文档
- GaussDB(DWS) SQL进阶之SQL操作之聚集函数 https://bbs.huaweicloud.com/blogs/293963
- PB级数仓GaussDB(DWS)性能黑科技之并行计算技术解密 https://bbs.huaweicloud.com/blogs/203426
- 常见性能参数调优设计 https://support.huaweicloud.com/performance-dws/dws_10_0068.html
数仓调优实战:GUC参数调优的更多相关文章
- 七、Hadoop学习笔记————调优之Hadoop参数调优
dfs.datanode.handler.count默认为3,大集群可以调整为10 传统MapReduce和yarn对比 如果服务器物理内存128G,则容器内存建议为100比较合理 配置总量时考虑系统 ...
- 【离线数仓】Day03-系统业务数据仓库:数仓表概念、搭建、数据导入、数据可视化、Azkaban全调度、拉链表的使用
一.电商业务与数据结构简介 1.业务流程 2.常识:SKU/SPU SKU=Stock Keeping Unit(库存量基本单位).现在已经被引申为产品统一编号的简称,每种产品均对应有唯一的SKU号. ...
- 2021升级版微服务教程7-OpenFeign实战开发和参数调优
2021升级版SpringCloud教程从入门到实战精通「H版&alibaba&链路追踪&日志&事务&锁」 教程全目录「含视频」:https://gitee.c ...
- 【JVM调优】Day03:GC参数、OOM出现方式、调优实战
一.常用GC参数(20个左右即可) 1.各种垃圾回收器的参数 PS + PO 常用的只有几十个 CMS的比较多,不建议使用 G1的常用参数简单 ZGC只有三个参数 二.OOM出现的方式 1.写一个让内 ...
- Apache Pulsar 在 BIGO 的性能调优实战(上)
背景 在人工智能技术的支持下,BIGO 基于视频的产品和服务受到广泛欢迎,在 150 多个国家/地区拥有用户,其中包括 Bigo Live(直播)和 Likee(短视频).Bigo Live 在 15 ...
- JVM调优实战
JVM调优实战 文档修订记录 版本 日期 撰写人 审核人 批准人 变更摘要 & 修订位置 ...
- 数据库MySQL调优实战经验总结<转>
数据库MySQL调优实战经验总结 MySQL 数据库的使用是非常的广泛,稳定性和安全性也非常好,经历了无数大小公司的验证.仅能够安装使用是远远不够的,MySQL 在使用中需要进行不断的调整参数或优化设 ...
- 类加载机制+JVM调优实战+代码优化
类加载机制 Java源代码经过编译器编译成字节码之后,最终都需要加载到虚拟机之后才能运行.虚拟机把描述类的数据从 Class 文件加载到内存,并对数据进行校验.转换解析和初始化,最终形成可以被虚拟机直 ...
- 高性能 Java 计算服务的性能调优实战
作者:vivo 互联网服务器团队- Chen Dongxing.Li Haoxuan.Chen Jinxia 随着业务的日渐复杂,性能优化俨然成为了每一位技术人的必修课.性能优化从何着手?如何从问题表 ...
- Hive详解(06) - Hive调优实战
Hive详解(06) - Hive调优实战 执行计划(Explain) 基本语法 EXPLAIN [EXTENDED | DEPENDENCY | AUTHORIZATION] query 案例实操 ...
随机推荐
- 数据分析day01
数据分析三剑客 numpy pandas(重点) matplotlib numpy模块 NumPy(Numerical Python)是Python语言中做科学计算的基础库.重在于数值计算,也是大部分 ...
- React 组件之属性
如果你想要实现自己的梦想,就必须先拥有勇气去追求它. 1. React Props 属性 props 主要解决两个问题:复用性问题以及可以让组件之间通信. 属性 props 正常是外部传入的,组件内部 ...
- windows下的批处理bat文件和Linux下的shell文件的含义
原文:https://www.cnblogs.com/caiguodong/p/10308255.html shell(Linux.Solaris) bat(windows) 含义 # rem 注释行 ...
- pip相关知识
正常安装语法 # 安装单个 pip install some-package # 安装指定版本 pip install some-package==版本号 # 查看当前模块版本号 pip instal ...
- 第一百零四篇:DOM事件流
好家伙,JS基础接着学, 1.事件流 页面哪个部分拥有特定的事件? 可以把页面想象成一个同心圆, 当你戳了其中的一点,其实你同时戳中了很多个圆 当你点击一个页面中的按钮,实际上你同时点击了这个 ...
- DataX 离线跨网场景的实施配置
配置仅限于跨不同网情况,网络互通情况方案和配置会更简单一点 内网A:MySql数据转换成Csv { "job": { "setting": { "sp ...
- 视觉slam十四讲CH5 ---相机与图像
视觉slam十四讲 ---CH5 相机与图像 视觉slam中,作为主要传感器的相机自然起到着重要的作用,而相机拍摄的图像及其处理也是我们要做的工作之一. 1. 相机模型 单目相机的针孔模型 上图中的模 ...
- masscode.io snippets 和 vscode 联动 代码片段
https://masscode.io/ 软件作用 代码片段 vscode 可以联动使用 下载不行 慢的话, 下载 fastgithub,打开后再下载
- k8s创建Pod的流程
Kubernetes(k8s)中Pod的创建过程是一个涉及多个组件协作的复杂流程,下面将详细描述这个过程,确保内容的详尽性和深度. 一.用户提交创建请求 Pod的创建始于用户通过kubectl命令行工 ...
- 基于2.4G私有协议的无线取餐系统设及实现
前记 最近在使用TLSR8355做几个小产品.正好赶上有客户需要一个无线取餐系统解决方案.笔者分析了一下需求.该芯片有充足的按键,LED灯,GPIO接口等.做这一款产品是顺道的事情. 需求梳理 功 ...