自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人

如今,大模型层出不穷,这为自然语言处理、计算机视觉、语音识别和其他领域的人工智能任务带来了重大的突破和进展。大模型通常指那些参数量庞大、层数深、拥有巨大的计算能力和数据训练集的模型。
但不能不承认的是,普通人使用大模型还是有一定门槛的,首先大模型通常需要大量的计算资源才能进行训练和推理。这包括高性能的图形处理单元(GPU)或者专用的张量处理单元(TPU),以及大内存和高速存储器。说白了,本地没N卡,就断了玩大模型的念想吧。
其次,大模型的性能往往受到模型调优和微调的影响。这需要对模型的超参数进行调整和优化,以适应特定任务或数据集。对大模型的调优需要一定的经验和专业知识,包括对深度学习原理和技术的理解。
那么,如果不具备相关专业知识,也没有专业的设备,同时也想开发属于自己的基于AI大模型的应用怎么办?本次我们使用在线的云雀大模型来打造属于自己的AI应用。
构建线上AI应用
首先访问扣子应用的官网:
https://www.coze.cn/home
注册成功之后,我们需要一个创意,也就是说我们到底想要做一个什么应用,这个应用的功能是什么,当然,关于创意AI是帮不了你的,需要自己想,比如笔者的代码水平令人不敢恭维,平时在CodeReView时,经常被同事嘲笑,没办法,有的人就是没有代码洁癖,为了避免此种情况经常发生,想要打造一款AI机器人能够在代码提交之前帮忙审核代码,检查语法的错误并给出修改意见和性能层面优化的方案。
此时点击创建Bot:
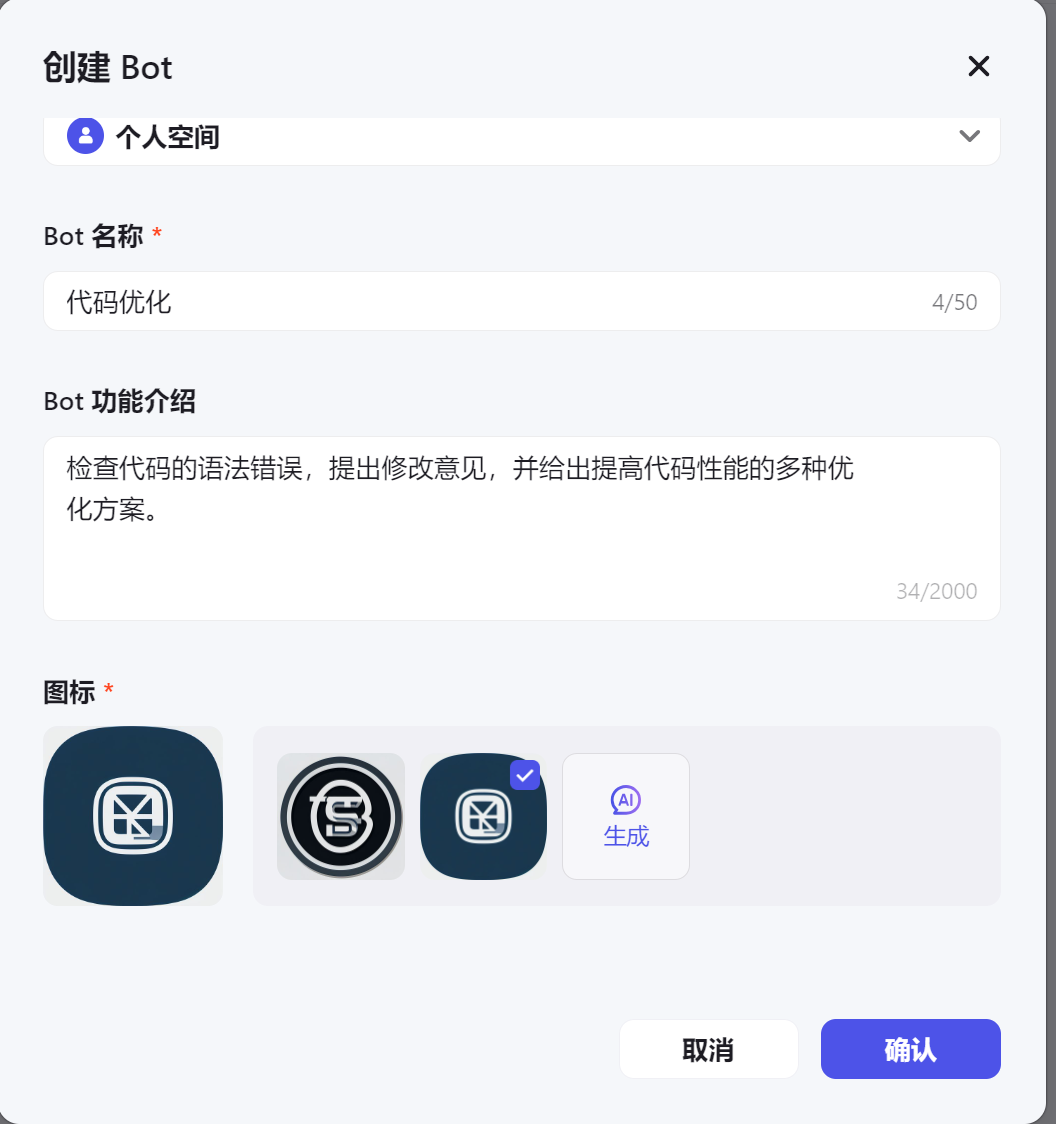
如上图所示,这里输入应用的名称和描述,至于应用图标,可以让AI生成一个。
工作流 WorkFlow
工作流指的是支持通过可视化的方式,对插件、大语言模型、代码块等功能进行组合,从而实现复杂、稳定的业务流程编排。
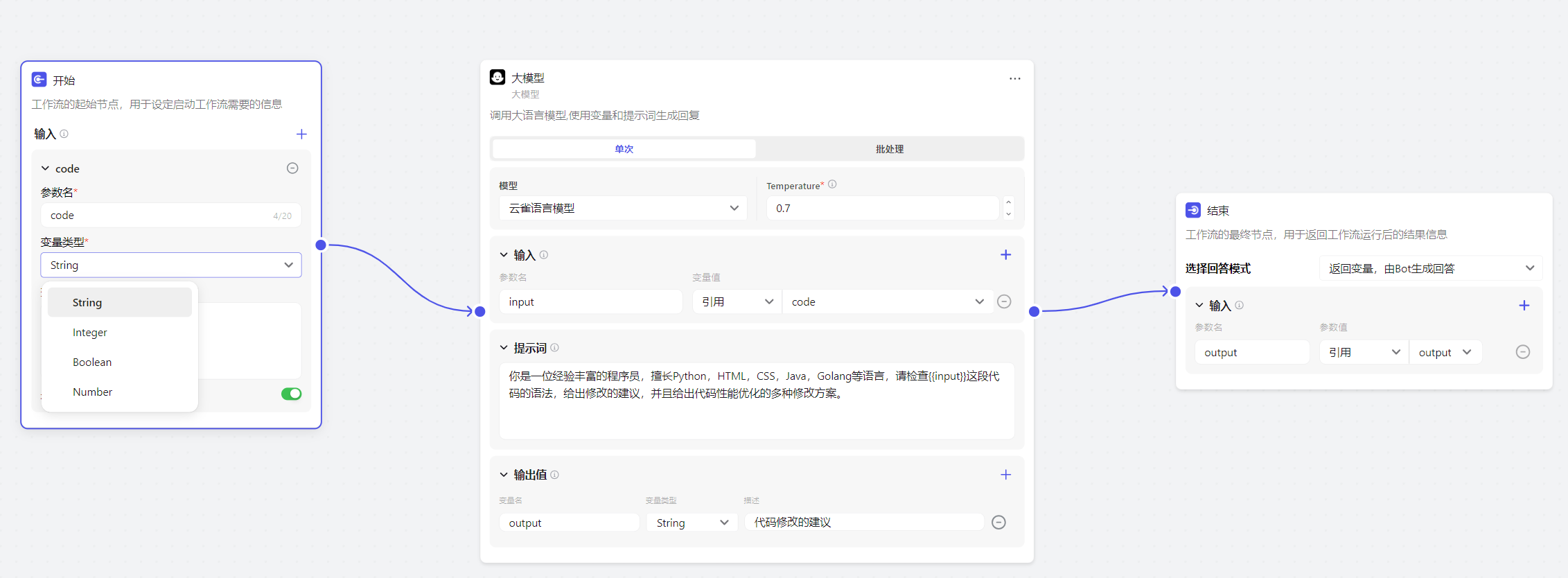
我们的工作流非常简单,第一步,用户输入代码,第二步,大模型检查代码,第三步,大模型返回修改意见。
点击创建工作流,输入的参数变量为code,数据类型可以选择四种,即字符串、整形、布尔和数字,这里代码显然选择字符串。
接着接入大模型,引导词这样填写:
你是一位经验丰富的程序员,擅长Python,HTML,CSS,Java,Golang等语言,请检查{{input}}这段代码的语法,给出修改的建议,并且给出代码性能优化的多种修改方案。
通过引导词来让大模型针对输入的代码进行检测。
最后返回大模型输入的修改意见。
如图所示:
随后可以运行整个工作流进行测试,大模型返回:
{
"output": "可优化项目与建议:\n- 建议使用 `try-except` 结构来捕获所有类型的异常,然后进行统一处理。\n- 建议添加代码注释,增强代码的可读性。\n\n优化后的代码如下所示:\n```python\ndef make_tran():\n \"\"\"\n 该函数用于将 video.srt 文件中的英文翻译成中文,并将翻译结果写入 two.srt 文件\n\n Returns:\n str: \"翻译完毕\",表示翻译过程已完成\n \"\"\"\n # 从预训练模型中加载 tokenizer 和 model\n tokenizer = AutoTokenizer.from_pretrained(\"Helsinki-NLP/opus-mt-en-zh\")\n model = AutoModelForSeq2SeqLM.from_pretrained(\"Helsinki-NLP/opus-mt-en-zh\")\n # 打开 video.srt 文件并读取其中的内容\n with open(\"./video.srt\", 'r', encoding=\"utf-8\") as file:\n gweight_data = file.read()\n # 将读取到的内容按换行符分割成多个段落,并存储在 result 列表中\n result = gweight_data.split(\"\\n\\n\")\n # 如果 two.srt 文件存在,则将其删除\n if os.path.exists(\"./two.srt\"):\n os.remove(\"./two.srt\")\n # 遍历 result 列表中的每个段落\n for res in result:\n # 将每个段落按换行符分割成多个句子,并存储在 line_srt 列表中\n line_srt = res.split(\"\\n\")\n # 尝试对每个句子进行翻译\n try:\n # 使用 tokenizer 对句子进行预处理,以便模型可以处理它们\n tokenized_text = tokenizer.prepare_seq2seq_batch([line_srt[2]], return_tensors='pt')\n # 使用模型进行翻译\n translation = model.generate(**tokenized_text)\n # 使用 tokenizer 将翻译结果解码为文本\n translated_text = tokenizer.batch_decode(translation, skip_special_tokens=False)[0]\n # 移除翻译结果中的填充字符和结束符号,并去除首尾的空格\n translated_text = translated_text.replace(\"<pad>\", \"\").replace(\"</s>\", \"\").strip()\n # 打印翻译结果\n print(translated_text)\n # 将翻译结果写入 two.srt 文件\n with open(\"./two.srt\", \"a\", encoding=\"utf-8\") as f:\n f.write(f\"{line_srt[0]}\\n{line_srt[1]}\\n{line_srt[2]}\\n{translated_text}\\n\\n\")\n # 如果在翻译过程中发生任何异常,则打印异常信息,并跳过当前句子\n except Exception as e:\n print(str(e))\n # 返回 \"翻译完毕\",表示翻译过程已完成\n return \"翻译完毕\"\n```"
}
如此,就完成了一个代码检查和优化的工作流,说白了,就是给用户一个没有token限制并且无限次使用的大模型,并且跳过prompt环节,直接简单粗暴返回垂直内容的解决方案。
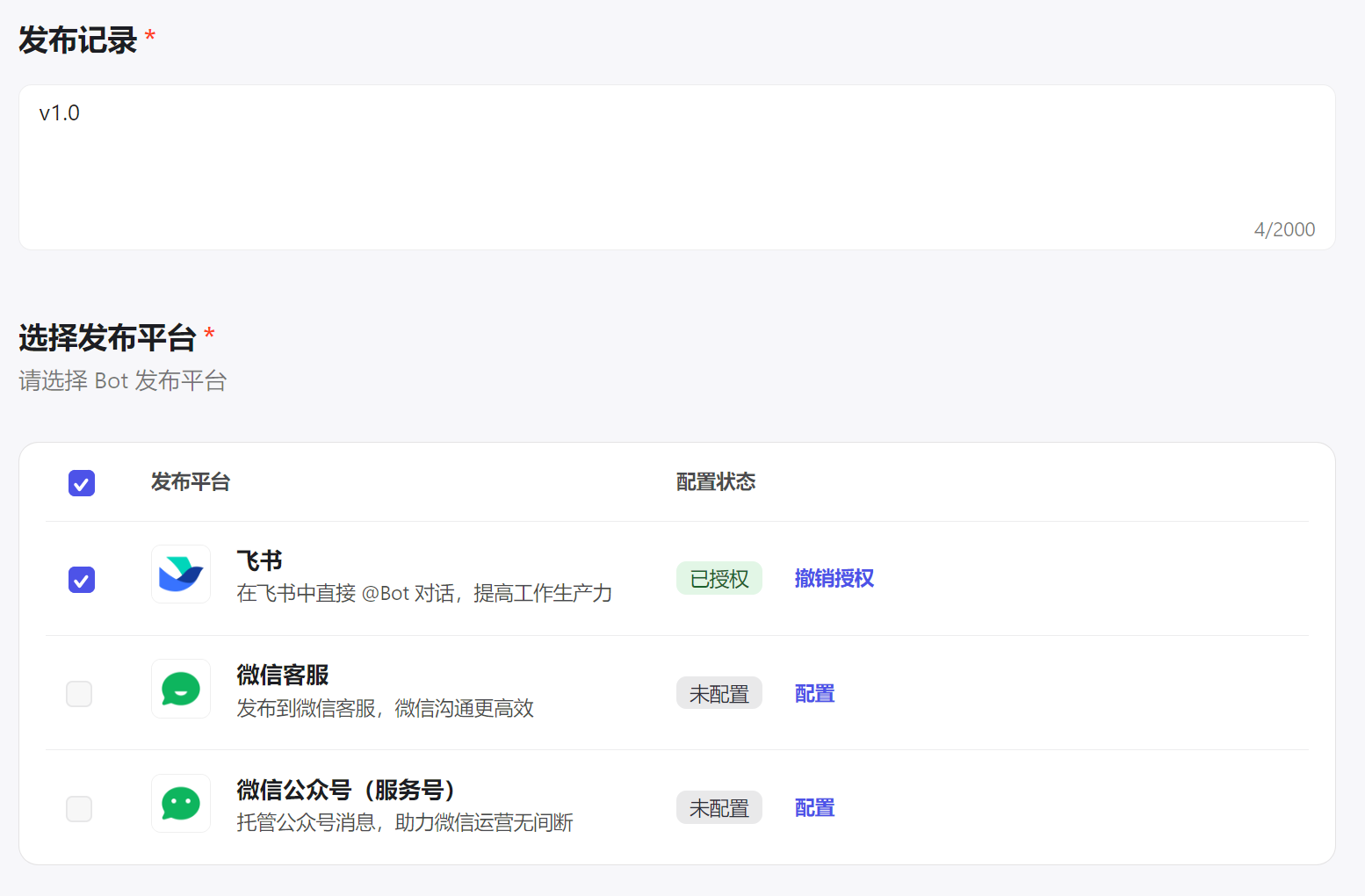
发布应用
构建好应用之后,我们可以在其他平台发布,让更多人使用该应用,这里以飞书为例子,飞书是一站式协同办公平台,为企业提供各种数字化办公解决方案,大部分公司都在使用。
随后在公司群里就可以直接调用自己的应用了:
结语
尽管使用大模型可能具有一些挑战,但随着技术的进步和资源的可用性,大模型的门槛正在逐渐降低。这为更多的普通人、无编程背景的爱好者提供了利用大模型来解决对于个人垂直领域相对复杂任务的机会。
自然语言开发AI应用,利用云雀大模型打造自己的专属AI机器人的更多相关文章
- 华为高级研究员谢凌曦:下一代AI将走向何方?盘古大模型探路之旅
摘要:为了更深入理解千亿参数的盘古大模型,华为云社区采访到了华为云EI盘古团队高级研究员谢凌曦.谢博士以非常通俗的方式为我们娓娓道来了盘古大模型研发的"前世今生",以及它背后的艰难 ...
- “体检医生”黑科技|让AI开发更精准,ModelArts更新模型诊断功能
摘要:华为云AI开发平台ModelArts黑科技加持AI研发,让模型开发更高效.更简单,降低AI在行业的落地门槛.全面的可视化评估以及智能诊断功能,使得开发者可以直观了解模型各方面性能,从而进行针对性 ...
- 无插件的大模型浏览器Autodesk Viewer开发培训-武汉-2014年8月28日 9:00 – 12:00
武汉附近的同学们有福了,这是全球第一次关于Autodesk viewer的教室培训. :) 你可能已经在各种场合听过或看过Autodesk最新推出的大模型浏览器,这是无需插件的浏览器模型,支持几十种数 ...
- AI大模型学习了解
# 百度文心 上线时间:2019年3月 官方介绍:https://wenxin.baidu.com/ 发布地点: 参考资料: 2600亿!全球最大中文单体模型鹏城-百度·文心发布 # 华为盘古 上线时 ...
- AI 影评家:用 Hugging Face 模型打造一个电影评分机器人
本文为社区成员 Jun Chen 为 百姓 AI 和 Hugging Face 联合举办的黑客松所撰写的教程文档,欢迎你阅读今天的第二条推送了解和参加本次黑客松活动.文内含有较多链接,我们不再一一贴出 ...
- DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍
DeepSpeed Chat: 一键式RLHF训练,让你的类ChatGPT千亿大模型提速省钱15倍 1. 概述 近日来,ChatGPT及类似模型引发了人工智能(AI)领域的一场风潮. 这场风潮对数字世 ...
- PowerDesigner 学习:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- PowerDesigner 15学习笔记:十大模型及五大分类
个人认为PowerDesigner 最大的特点和优势就是1)提供了一整套的解决方案,面向了不同的人员提供不同的模型工具,比如有针对企业架构师的模型,有针对需求分析师的模型,有针对系统分析师和软件架构师 ...
- Journal of Proteomics Research | 利用混合蛋白质组模型对MBR算法中错误转移鉴定率的评估
题目:Evaluating False Transfer Rates from the Match-between-Runs Algorithm with a Two-Proteome Model 期 ...
- 千亿参数开源大模型 BLOOM 背后的技术
假设你现在有了数据,也搞到了预算,一切就绪,准备开始训练一个大模型,一显身手了,"一朝看尽长安花"似乎近在眼前 -- 且慢!训练可不仅仅像这两个字的发音那么简单,看看 BLOOM ...
随机推荐
- d3生成器--line,area,diagonal
https://blog.csdn.net/qq_31396185/article/details/78147612
- Python实现PowerPoint(PPT/PPTX)到PDF的批量转换
如果需要处理大量的PPT转PDF的工作,一个个打开并另存为PDF是非常费时的做法.我们可以利用Python编程语言的强大的工具来自动化这个过程,使得批量转换变得简单而高效.本文将介绍如何使用Pytho ...
- C#查找算法1:二分查找
二分查找也称折半查找(Binary Search),它是一种效率较高的查找方法.但是,折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列. 原理:将n个元素分成个数大致相同的两半,取 ...
- docker容器常用操作
1.查看运行容器 docker ps: 2.查看所有容器 docker ps -a: 3.查看容器的日志 docker logs 容器名称/容器ID: 4.运行镜像 docker run --na ...
- Transformer的应用
Transformer 写在前面 本学期学习了NLP的课程,本小菜鸡结合做的课设(基于Transformer的英文文档摘要系统的设计与实现),来写一下有关于Transformer的相关内容吧,有问题之 ...
- 在Python中使用Process创建子进程遇到的问题
假如使用Process创建子进程,那么在最后的函数调用时需要加上if __name__ == "__main__":语句,否则会报错. 未使用该语句 代码示例 from multi ...
- Keep English Level-01
state -- 声称,宣称,国家,政府 state-owned -- 国有的 He stated that "hell will break loose,politically and m ...
- 常见的IE布局兼容问题
(1) div 中内容在IE和火狐中居中问题: (2)高度的问题,div出现重叠 (3)浮动引发的问题如外围DIV无法框住内部元素: (4)IE浮动margin产生双倍距离-display:inli ...
- file-loader返回object Module 路径的问题
新版本的 file-loader生成使用ES模块语法的JS模块,所以它加载的文件,不再返回路径,而是返回一个对象,通过对象.default属性,可以取得路径 所以第一种方法,可以修改路径 <i ...
- [转帖]Redis重大版本整理(Redis2.6-Redis7.0)
Redis借鉴了Linux操做系统对于版本号的命名规则:node 版本号第二位若是是奇数,则为非稳定版本(例如2.7.2.9.3.1),若是是偶数,则为稳定版本(例如2.6.2.8.3.0.3.2). ...