TextIn文档树引擎,助力RAG知识库问答检索召回能力提升
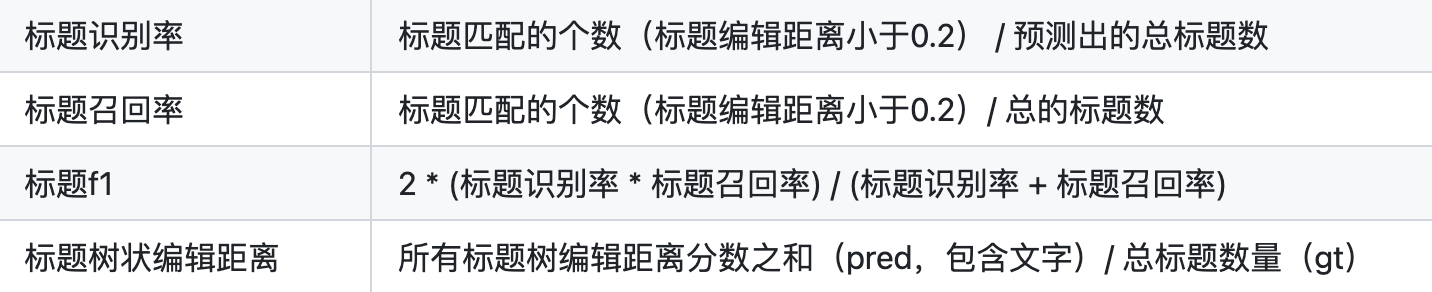
- 整份文档的段落内容,以序列化形式传入模型
- 提取当前段落的embedding值
- 预测每个段落和上一个段落的关系,分为子标题、子段落、合并、旁系、主标题、表格标题
- 如果是旁系类型,则再往上找父节点,并判断其层级关系,直到找到最终的父节点
- 基于每个段落的情况,构造该文档的文档树,并按 JSON 结构输出(右图中未渲染段落节点)
TextIn文档树引擎,助力RAG知识库问答检索召回能力提升的更多相关文章
- bs4--官文--搜索文档树
搜索文档树 Beautiful Soup定义了很多搜索方法,这里着重介绍2个: find() 和 find_all() .其它方法的参数和用法类似,请读者举一反三. 再以“爱丽丝”文档作为例子: ht ...
- bs4--官文--遍历文档树
遍历文档树 还拿”爱丽丝梦游仙境”的文档来做例子: html_doc = """ <html><head><title>The Dor ...
- bs4--官文--修改文档树
修改文档树 Beautiful Soup的强项是文档树的搜索,但同时也可以方便的修改文档树 修改tag的名称和属性 在 Attributes 的章节中已经介绍过这个功能,但是再看一遍也无妨. 重命名一 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- Python爬虫系列(六):搜索文档树
今天早上,写的东西掉了.这个烂知乎,有bug,说了自动保存草稿,其实并没有保存.无语 今晚,我们将继续讨论如何分析html文档. 1.字符串 #直接找元素soup.find_all('b') 2.正则 ...
- 使用requests爬取梨视频、bilibili视频、汽车之家,bs4遍历文档树、搜索文档树,css选择器
今日内容概要 使用requests爬取梨视频 requests+bs4爬取汽车之家 bs4遍历文档树 bs4搜索文档树 css选择器 内容详细 1.使用requests爬取梨视频 # 模拟发送http ...
- MaltReport2:通用文档生成引擎
UPDATED: 本文仅适用 MaltReport 2.x ,3.x 版本文档还在撰写当中,目前请参考项目中的 Samples. MaltReport 是我几年前写的开源单据.报表引擎,最近进行了较大 ...
- Linux 基础命令、文档树 和 bash
最近发现了一个总结得更好的:bash cheatsheet 本文只是我对 linux 基础学习的一个总结,可能仅适用于复习用.算是我的 Linux 备忘录. 最基础 tab 补全 * 通配符 ctrl ...
- [整理] ES5 词法约定文档树状图
将ES5 词法说明整理为了树状图,方便查阅,请自行点开小图看大图:
- smarty3.0中文手册文档API及使用指南
1.安装Smarty3.0一.什么是smarty?smarty是一个使用PHP写出来的模板PHP模板引擎,它提供了逻辑与外在内容的分离,简单的讲,目的就是要使用PHP程序员同美工分离,使用的程序员改变 ...
随机推荐
- SpringBoot+Mybatis整合出现org.apache.ibatis.binding.BindingException: Invalid bound statement (not found)的解决
在搭建自己的后台管理,遇到一个比较小问题,顺便记录了一下. 启动SpringBoot后台时,前端访问后台执行Mybatis时,出现了这样的报错: org.apache.ibatis.binding.B ...
- 《探索Python Requests中的代理应用与实践》
requests加代理 高匿API代理 此处使用的小象代理:1元100个,便宜,可以购买尝试加下代理 存活期1到2分钟 import time import requests from lxml im ...
- Python 潮流周刊第 2 季完结了,分享几项总结
我订阅了很多的周刊/Newsletter,但是发现它们都有一个共同的毛病:就是缺乏对往期内容的整理,它们很少会对内容数据作统计分析,更没有将内容整理成合集的习惯. 在自己开始连载周刊后,我就想别开生面 ...
- UE MultiLineTraceByChannel函数返回只有一个对象的问题
问题描述 MultiLineTraceByChannel,看函数名字是返回射线检测到的所有对象,实际使用过程中,发现返回的数组中只又一个对象. Multi Line Trace by Channel ...
- [oeasy]python0145_版本控制_git_备份还原
git版本控制 回忆上次内容 上次我们了解了 try 的完全体 try 尝试运行 except 发现异常时运行的代码块 else 没有发现异常时运行的代码块 finally 无论是否发现异 ...
- ComfyUI进阶:Comfyroll插件 (七)
前言: 学习ComfyUI是一场持久战,而Comfyroll 是一款功能强大的自定义节点集合,专为 ComfyUI 用户打造,旨在提供更加丰富和专业的图像生成与编辑工具.借助这些节点,用户可以在静态图 ...
- 修改PE文件来实现管理员权限
在Windows我们常用的方法就是给应用添加app.manifest清单文件,然后生成的Exe就会具有管理员权限. 近期我在使用Wix制作Exe安装包时,发现此方法不通,我在github上和Stack ...
- 【RabbitMQ】11 深入部分P4 延迟队列
一.延迟队列: 消息经过交换机分配到队列上之后,在到达指定的时间,才会被消费? 需求: 1.下单之后的30分钟,用户未支付,订单取消,回滚库存 2.新用户注册7天后,发送短信慰问,或者是用户生日发送短 ...
- 【Vue】12 VueRouter Part2 路由与传参
[编程式导航] 我们希望在路由跳转之前执行某一些功能... <template> <div id="app"> <h2>这是App.vue组件的 ...
- Jax框架 —— 如何在没有GPU和TPU的设备上debug代码 —— 在CPU上使用GPU仿真设置 —— Jax框架在多卡设备上的自动并行特性的仿真体验
Jax计算框架是Google用来取代Tensorflow的新一代计算框架,这个框架使用类似pytorch的技术,但是在pytorch技术之上加入了更加强大的技术,但是这也导致该框架使用起来要比pyto ...