欧奈尔的RPS指标如何使用到股票预测
前言

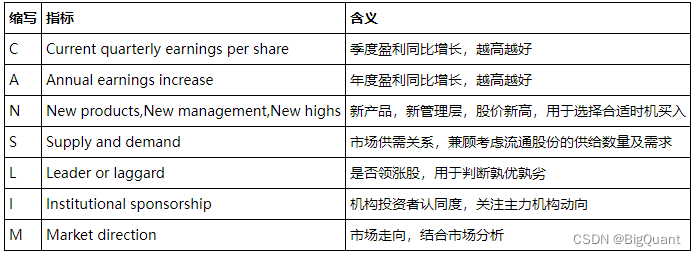
1988年,欧奈尔将他的投资理念写成了《笑傲股市How to Make Money in Stocks》。书中总结了选股模式CANSLIM模型,每一个字母都代表一种尚未发动大涨势的潜在优质股的特征。
视频讲解
如何结合欧奈尔的RPS指标开发策略
代码示例
# 回测引擎:初始化函数,只执行一次
def m19_initialize_bigquant_run(context):
# 加载预测数据
context.ranker_prediction = context.options['data'].read_df()
# 系统已经设置了默认的交易手续费和滑点,要修改手续费可使用如下函数
context.set_commission(PerOrder(buy_cost=0.0003, sell_cost=0.0013, min_cost=5))
# 预测数据,通过options传入进来,使用 read_df 函数,加载到内存 (DataFrame)
# 设置买入的股票数量,这里买入预测股票列表排名靠前的5只
stock_count = 5
# 每只的股票的权重,如下的权重分配会使得靠前的股票分配多一点的资金,[0.339160, 0.213986, 0.169580, ..]
context.stock_weights = T.norm([1 / math.log(i + 2) for i in range(0, stock_count)])
# 设置每只股票占用的最大资金比例
context.max_cash_per_instrument = 0.2
context.options['hold_days'] = 5
# 回测引擎:每日数据处理函数,每天执行一次
def m19_handle_data_bigquant_run(context, data):
# 按日期过滤得到今日的预测数据
today = data.current_dt.strftime('%Y-%m-%d')
ranker_prediction = context.ranker_prediction[
context.ranker_prediction.date == today]
# 1. 资金分配
# 平均持仓时间是hold_days,每日都将买入股票,每日预期使用 1/hold_days 的资金
# 实际操作中,会存在一定的买入误差,所以在前hold_days天,等量使用资金;之后,尽量使用剩余资金(这里设置最多用等量的1.5倍)
is_staging = context.trading_day_index < context.options['hold_days'] # 是否在建仓期间(前 hold_days 天)
cash_avg = context.portfolio.portfolio_value / context.options['hold_days']
cash_for_buy = min(context.portfolio.cash, (1 if is_staging else 1.5) * cash_avg)
cash_for_sell = cash_avg - (context.portfolio.cash - cash_for_buy)
positions = {e.symbol: p.amount * p.last_sale_price
for e, p in context.portfolio.positions.items()}
#--------------------------START:持有固定天数卖出(不含建仓期)-----------
current_stopdays_stock = []
positions_lastdate = {e.symbol:p.last_sale_date for e,p in context.portfolio.positions.items()}
# 不是建仓期(在前hold_days属于建仓期)
if not is_staging:
for instrument in positions.keys():
#使用交易天数
dt = pd.to_datetime(D.trading_days(end_date = today).iloc[-context.options['hold_days']].values[0])
if pd.to_datetime(positions_lastdate[instrument].strftime('%Y-%m-%d')) <= dt and data.can_trade(context.symbol(instrument)):
context.order_target_percent(context.symbol(instrument), 0)
cash_for_sell -= positions[instrument]
#------------------------- END:持有固定天数卖出-----------------------
# 2. 生成卖出订单:hold_days天之后才开始卖出;对持仓的股票,按机器学习算法预测的排序末位淘汰
if not is_staging and cash_for_sell > 0:
equities = {e.symbol: e for e, p in context.portfolio.positions.items()}
instruments = list(reversed(list(ranker_prediction.instrument[ranker_prediction.instrument.apply(
lambda x: x in equities)])))
for instrument in instruments:
context.order_target(context.symbol(instrument), 0)
cash_for_sell -= positions[instrument]
if cash_for_sell <= 0:
break
# 3. 生成买入订单:按机器学习算法预测的排序,买入前面的stock_count只股票
buy_cash_weights = context.stock_weights
buy_instruments = list(ranker_prediction.instrument[:len(buy_cash_weights)])
max_cash_per_instrument = context.portfolio.portfolio_value * context.max_cash_per_instrument
for i, instrument in enumerate(buy_instruments):
cash = cash_for_buy * buy_cash_weights[i]
if cash > max_cash_per_instrument - positions.get(instrument, 0):
# 确保股票持仓量不会超过每次股票最大的占用资金量
cash = max_cash_per_instrument - positions.get(instrument, 0)
if cash > 0:
context.order_value(context.symbol(instrument), cash)
# 回测引擎:准备数据,只执行一次
def m19_prepare_bigquant_run(context):
pass
m1 = M.instruments.v2(
start_date='2019-01-01',
end_date='2021-12-31',
market='CN_STOCK_A',
instrument_list='',
max_count=0
)
m2 = M.advanced_auto_labeler.v2(
instruments=m1.data,
label_expr="""# #号开始的表示注释
# 0. 每行一个,顺序执行,从第二个开始,可以使用label字段
# 1. 可用数据字段见 https://bigquant.com/docs/develop/datasource/deprecated/history_data.html
# 添加benchmark_前缀,可使用对应的benchmark数据
# 2. 可用操作符和函数见 `表达式引擎 <https://bigquant.com/docs/develop/bigexpr/usage.html>`_
# 计算收益:5日收盘价(作为卖出价格)除以明日开盘价(作为买入价格)
shift(close, -5) / shift(open, -1)
# 极值处理:用1%和99%分位的值做clip
clip(label, all_quantile(label, 0.01), all_quantile(label, 0.99))
# 将分数映射到分类,这里使用20个分类
all_wbins(label, 20)
# 过滤掉一字涨停的情况 (设置label为NaN,在后续处理和训练中会忽略NaN的label)
where(shift(high, -1) == shift(low, -1), NaN, label)
""",
start_date='',
end_date='',
benchmark='000300.HIX',
drop_na_label=True,
cast_label_int=True
)
m3 = M.input_features.v1(
features="""# #号开始的表示注释
# 多个特征,每行一个,可以包含基础特征和衍生特征
return_5
return_10
return_20
avg_amount_0/avg_amount_5
avg_amount_5/avg_amount_20
rank_avg_amount_0/rank_avg_amount_5
rank_avg_amount_5/rank_avg_amount_10
rank_return_0
rank_return_5
rank_return_10
rank_return_0/rank_return_5
rank_return_5/rank_return_10
pe_ttm_0
"""
)
m4 = M.input_features.v1(
features_ds=m3.data,
features="""# _PRS250=(close_0-shift(close_0,250))/shift(close_0,250)
# PRS250=rank(_PRS250)
# _PRS120=(close_0-shift(close_0,120))/shift(close_0,120)
# PRS120=rank(_PRS120)
# t1=where(PRS250<0.1,1,0)
# t2=where(PRS120<0.1,1,0)
# flag=where(max(t1,t2)==1,1,0)
PRS10=rank(return_10)
PRS20=rank(return_20)
PRS60=rank(return_60)
t1=where(PRS10<0.1,1,0)
t2=where(PRS20<0.1,1,0)
t3=where(PRS60<0.1,1,0)
flag=where(max(t1,t2,t3)==1,1,0)
rank_fs_roe_ttm_0"""
)
m15 = M.general_feature_extractor.v7(
instruments=m1.data,
features=m3.data,
start_date='',
end_date='',
before_start_days=90
)
m16 = M.derived_feature_extractor.v3(
input_data=m15.data,
features=m3.data,
date_col='date',
instrument_col='instrument',
drop_na=False,
remove_extra_columns=False
)
m7 = M.join.v3(
data1=m2.data,
data2=m16.data,
on='date,instrument',
how='inner',
sort=False
)
m13 = M.dropnan.v1(
input_data=m7.data
)
m6 = M.stock_ranker_train.v6(
training_ds=m13.data,
features=m3.data,
learning_algorithm='排序',
number_of_leaves=30,
minimum_docs_per_leaf=1000,
number_of_trees=20,
learning_rate=0.1,
max_bins=1023,
feature_fraction=1,
data_row_fraction=1,
plot_charts=True,
ndcg_discount_base=1,
m_lazy_run=False
)
m9 = M.instruments.v2(
start_date=T.live_run_param('trading_date', '2022-01-01'),
end_date=T.live_run_param('trading_date', '2022-11-02'),
market='CN_STOCK_A',
instrument_list='',
max_count=0
)
m17 = M.general_feature_extractor.v7(
instruments=m9.data,
features=m4.data,
start_date='',
end_date='',
before_start_days=400
)
m18 = M.derived_feature_extractor.v3(
input_data=m17.data,
features=m4.data,
date_col='date',
instrument_col='instrument',
drop_na=False,
remove_extra_columns=False
)
m10 = M.filter.v3(
input_data=m18.data,
expr='flag!=1 and rank_fs_roe_ttm_0>0.1',
output_left_data=False
)
m14 = M.dropnan.v1(
input_data=m10.data
)
m8 = M.stock_ranker_predict.v5(
model=m6.model,
data=m14.data,
m_lazy_run=False
)
m19 = M.trade.v4(
instruments=m9.data,
options_data=m8.predictions,
start_date='',
end_date='',
initialize=m19_initialize_bigquant_run,
handle_data=m19_handle_data_bigquant_run,
prepare=m19_prepare_bigquant_run,
volume_limit=0.025,
order_price_field_buy='open',
order_price_field_sell='close',
capital_base=1000000,
auto_cancel_non_tradable_orders=True,
data_frequency='daily',
price_type='真实价格',
product_type='股票',
plot_charts=True,
backtest_only=False,
benchmark='000300.HIX'
可直接拷贝到BigQuant平台上运行
欧奈尔的RPS指标如何使用到股票预测的更多相关文章
- <欧奈尔制胜法则—如何在股市中赚钱>读书笔记
在选择个股建仓时,要选择那些在最近季度报表中,每股收益比上年同期要有较大增幅的股票. 每股收益是指公司税后净利润除以公司普通股的总股本 选择年增长率为25%--50%的公司 年度盈利和季度盈利都要出色 ...
- 《给业余投资者的10条军规 (雪球「岛」系列) (闲来一坐s话投资》读书笔记
大多数进入股市的人,往往有着非一般的自信.比如,读了几本大师的书,就感觉自己掌握了什么秘笈,又恰逢账面浮盈,自信心更是前所未有的膨胀. 有人说,投资者不经过一轮牛熊转换是成熟不起来的. 古人早就有言, ...
- ADC关键性能指标及误区
ADC关键性能指标及误区 由于ADC产品相对于网络产品和服务器需求小很多,用户和集成商在选择产品时对关键指标的理解难免有一些误区,加之部分主流厂商刻意引导,招标规范往往有不少非关键指标作被作为必须符合 ...
- 机器学习十大算法总览(含Python3.X和R语言代码)
引言 一监督学习 二无监督学习 三强化学习 四通用机器学习算法列表 线性回归Linear Regression 逻辑回归Logistic Regression 决策树Decision Tree 支持向 ...
- .NET 5.0正式发布,功能特性介绍(翻译)
本文由葡萄城技术团队翻译并首发 转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 我们很高兴今天.NET5.0正式发布.这是一个重要的版本-其中也包括了C# ...
- ML 05、分类、标注与回归
机器学习算法 原理.实现与实践 —— 分类.标注与回归 1. 分类问题 分类问题是监督学习的一个核心问题.在监督学习中,当输出变量$Y$取有限个离散值时,预测问题便成为分类问题. 监督学习从数据中学习 ...
- 十大算法---Adaboost
当我们有针对同一数据集有多个不同的分类器模型时,怎样组合它们使预测分类的结果更加准确, 针对这种情况,机器学习通常两种策略. 1 一种是bagging,一种是boosting bagging:随机对样 ...
- zhihu spark集群,书籍,论文
spark集群中的节点可以只处理自身独立数据库里的数据,然后汇总吗? 修改 我将spark搭建在两台机器上,其中一台既是master又是slave,另一台是slave,两台机器上均装有独立的mongo ...
- 企业架构研究总结(39)——TOGAF架构能力框架之架构委员会和架构合规性
3. 架构委员会 正如前面所说,一个用来对架构治理策略的实现进行监督的跨组织的架构委员会是架构治理策略成功的主要要素之一.架构委员会应该能够代表所有主要干系人的需求,并且通常还需要对整个架构的审查及维 ...
- TOGAF架构能力框架之架构委员会和架构合规性
TOGAF架构能力框架之架构委员会和架构合规性 3. 架构委员会 正如前面所说,一个用来对架构治理策略的实现进行监督的跨组织的架构委员会是架构治理策略成功的主要要素之一.架构委员会应该能够代表所有主要 ...
随机推荐
- Solution -「洛谷 P5659」「CSP-S 2019」树上的数
Description Link. 联赛原题应该都读过吧-- Solution Part 0 大致思路 主要的思路就是逐个打破,研究特殊的数据得到普通的结论. Part 1 暴力的部分分 暴力的部分分 ...
- java数组的定义和使用规范
java数组 三种定义方式 1.数组类型[] 数组名字 = new 数组类型[数组长度] String[] str = new String[n]; //这里n代表数组的长度可变 //另外上面这种写法 ...
- Go 多版本管理工具
Go 多版本管理工具 目录 Go 多版本管理工具 一.go get 命令 1.1 使用方法: 二.Goenv 三.GVM (Go Version Manager) 四.voidint/g 4.1 安装 ...
- a-2b
a-2b 描述 输入两个高精度数a和b,求a-2b的值. 输入 输入两行,第一行是被减数a,第二行是减数b(a>2b并且a,2b的位数不同且不存在借位,且b+b不存在进位). 输出 一行,即 ...
- MySQL8.0默认加密连接方式
Mysql8.0开始默认采用新的caching_sha2_password的身份验证方式,常规老接口会因此无法连接数据库. 为继续使用老的身份验证方式,需显式指定身份验证方式为 mysql_nativ ...
- umich cv-2-2
UMICH CV Linear Classifiers 在上一篇博文中,我们讨论了利用损失函数来判断一个权重矩阵的好坏,在这节中我们将讨论如何去找到最优的权重矩阵 想象我们要下到一个峡谷的底部,我们自 ...
- 2020 5 17 codeforces
cf还没结束,就开始写总结了.cf确实是个好东西,能够直接暴露出弱点和增加刷题量.以后还是要多打打的.这次我发现自己的码力还是不行.一个二分都要调好久.唉T1sb题,就是入门用的.题目看不懂...写了 ...
- 基于matomo实现业务数据埋点采集上报
matomo是一款Google-analytics数据埋点采集上报的平替方案,可保护您的数据和客户的隐私:正如它官网的slogan: Google Analytics alternative that ...
- OpenTiny Vue 支持 Vue2.7 啦!
你好,我是 Kagol. 前言 上个月发布了一篇 Vue2 升级 Vue3 的文章. 少年,该升级 Vue3 了! 里面提到使用了 ElementUI 的 Vue2 项目,可以通过 TinyVue 和 ...
- 揭秘计算机奇迹:探索I/O设备的神秘世界!
引言 在之前的章节中,我们详细讲解了计算机系统中一些核心组成部分,如中央处理器(CPU).内存.硬盘等.这些组件负责处理和存储数据,使得计算机能够有效地运行.然而,除了这些核心组件,计算机系统还包含许 ...