[转帖]TiDB 热点问题处理
TiDB 热点问题处理
本文介绍如何定位和解决读写热点问题。
TiDB 作为分布式数据库,内建负载均衡机制,尽可能将业务负载均匀地分布到不同计算或存储节点上,更好地利用上整体系统资源。然而,机制不是万能的,在一些场景下仍会有部分业务负载不能被很好地分散,影响性能,形成单点的过高负载,也称为热点。
TiDB 提供了完整的方案用于排查、解决或规避这类热点。通过均衡负载热点,可以提升整体性能,包括提高 QPS 和降低延迟等。
常见热点场景
TiDB 编码规则回顾
TiDB 对每个表分配一个 TableID,每一个索引都会分配一个 IndexID,每一行分配一个 RowID(默认情况下,如果表使用整数型的 Primary Key,那么会用 Primary Key 的值当做 RowID)。其中 TableID 在整个集群内唯一,IndexID/RowID 在表内唯一,这些 ID 都是 int64 类型。
每行数据按照如下规则进行编码成 Key-Value pair:
其中 Key 的 tablePrefix 和 recordPrefixSep 都是特定的字符串常量,用于在 KV 空间内区分其他数据。
对于 Index 数据,会按照如下规则编码成 Key-Value pair:
Index 数据还需要考虑 Unique Index 和非 Unique Index 两种情况,对于 Unique Index,可以按照上述编码规则。但是对于非 Unique Index,通过这种编码并不能构造出唯一的 Key,因为同一个 Index 的 tablePrefix{tableID}_indexPrefixSep{indexID} 都一样,可能有多行数据的 ColumnsValue 是一样的,所以对于非 Unique Index 的编码做了一点调整:
表热点
从 TiDB 编码规则可知,同一个表的数据会在以表 ID 开头为前缀的一个 range 中,数据的顺序按照 RowID 的值顺序排列。在表 insert 的过程中如果 RowID 的值是递增的,则插入的行只能在末端追加。当 Region 达到一定的大小之后会进行分裂,分裂之后还是只能在 range 范围的末端追加,永远只能在一个 Region 上进行 insert 操作,形成热点。
常见的 increment 类型自增主键就是顺序递增的,默认情况下,在主键为整数型时,会用主键值当做 RowID,此时 RowID 为顺序递增,在大量 insert 时形成表的写入热点。
同时,TiDB 中 RowID 默认也按照自增的方式顺序递增,主键不为整数类型时,同样会遇到写入热点的问题。
此外,当写入或读取数据存在热点时,即出现新建表或分区的写入热点问题和只读场景下周期性读热点问题时,你可以使用表属性控制 Region 合并。具体的热点场景描述和解决方法可以查看使用表属性控制 Region 合并的使用场景。
索引热点
索引热点与表热点类似,常见的热点场景出现在时间顺序单调递增的字段,或者插入大量重复值的场景。
确定存在热点问题
性能问题不一定是热点造成的,也可能存在多个因素共同影响,在排查前需要先确认是否与热点相关。
判断写热点依据:打开监控面板 TiKV-Trouble-Shooting 中 Hot Write 面板,观察 Raftstore CPU 监控是否存在个别 TiKV 节点的指标明显高于其他节点的现象。
判断读热点依据:打开监控面板 TIKV-Details 中 Thread_CPU,查看 coprocessor cpu 有没有明显的某个 TiKV 特别高。
使用 TiDB Dashboard 定位热点表
TiDB Dashboard 中的流量可视化功能可帮助用户缩小热点排查范围到表级别。以下是流量可视化功能展示的一个热力图样例,该图横坐标是时间,纵坐标是各个表和索引,颜色越亮代表其流量越大。可在工具栏中切换显示读或写流量。
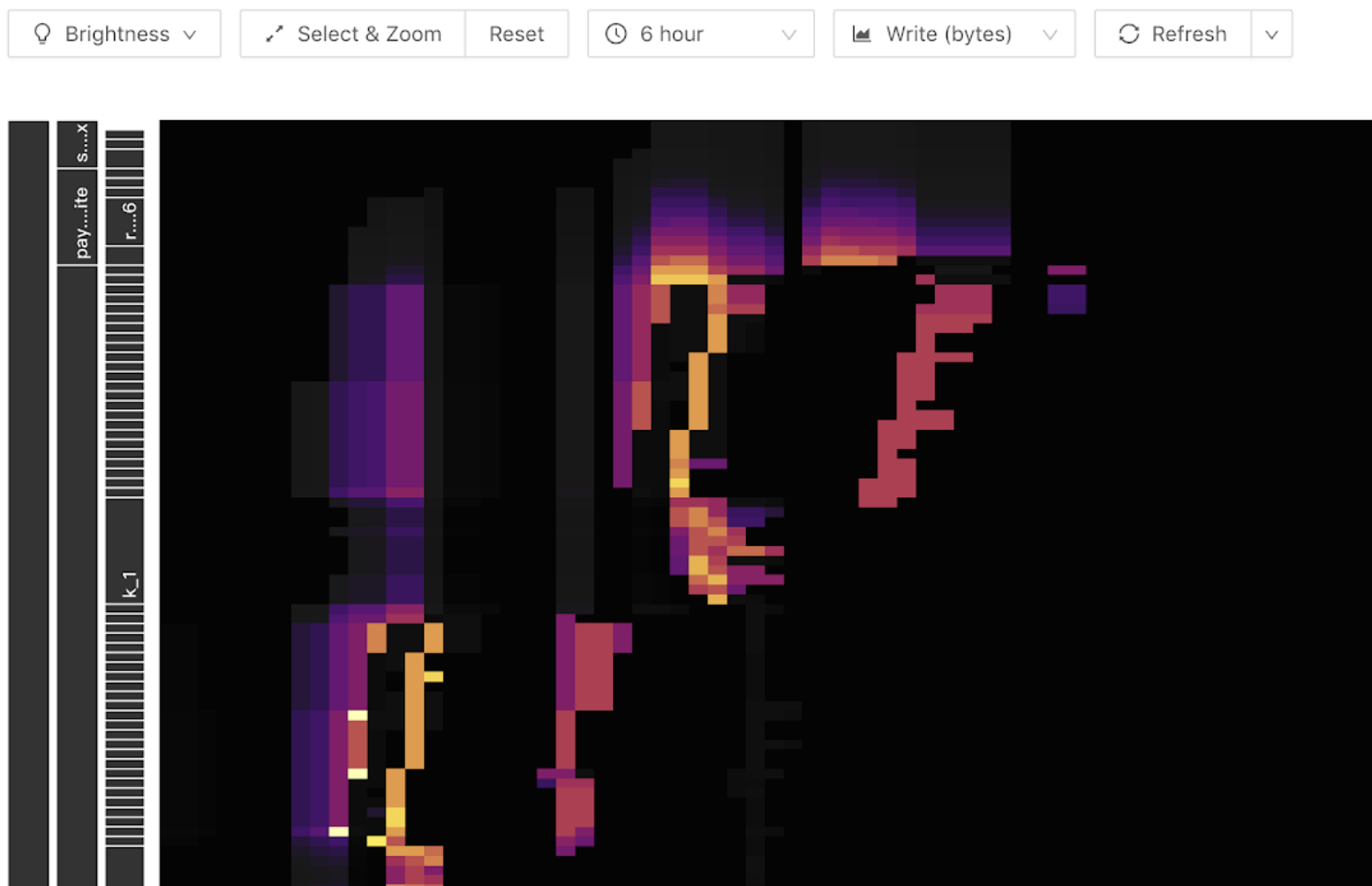
当图中写入流量图出现以下明亮斜线(斜向上或斜向下)时,由于写入只出现在末端,随着表 Region 数量变多,呈现出阶梯状。此时说明该表构成了写入热点:

对于读热点,在热力图中一般表现为一条明亮的横线,通常是有大量访问的小表,如下图所示:

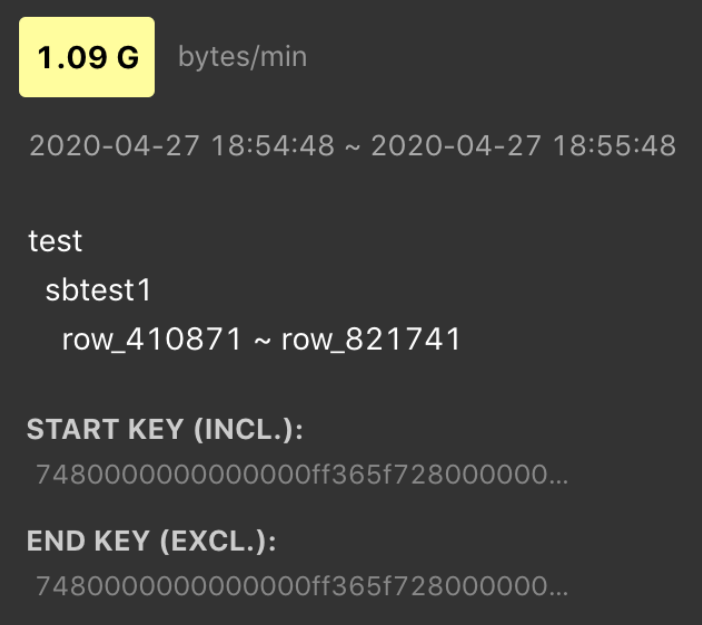
将鼠标移到亮色块上,即可看到是什么表或索引具有大流量,如下图所示:
使用 SHARD_ROW_ID_BITS 处理热点表
对于非聚簇索引主键或没有主键的表,TiDB 会使用一个隐式的自增 RowID,大量 INSERT 时会把数据集中写入单个 Region,造成写入热点。
通过设置 SHARD_ROW_ID_BITS,可以把 RowID 打散写入多个不同的 Region,缓解写入热点问题。
语句示例:
SHARD_ROW_ID_BITS 的值可以动态修改,每次修改之后,只对新写入的数据生效。
对于含有 CLUSTERED 主键的表,TiDB 会使用表的主键作为 RowID,因为 SHARD_ROW_ID_BITS 会改变 RowID 生成规则,所以此时无法使用 SHARD_ROW_ID_BITS 选项。而对于使用 NONCLUSTERED 主键的表,TiDB 会使用自动分配的 64 位整数作为 RowID,此时也可以使用 SHARD_ROW_ID_BITS 特性。要了解关于 CLUSTERED 主键的详细信息,请参考聚簇索引。
以下是两张无主键情况下使用 SHARD_ROW_ID_BITS 打散热点后的流量图,第一张展示了打散前的情况,第二张展示了打散后的情况。
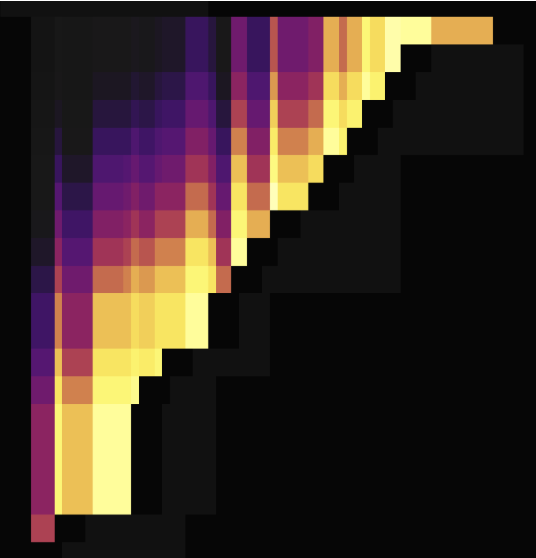
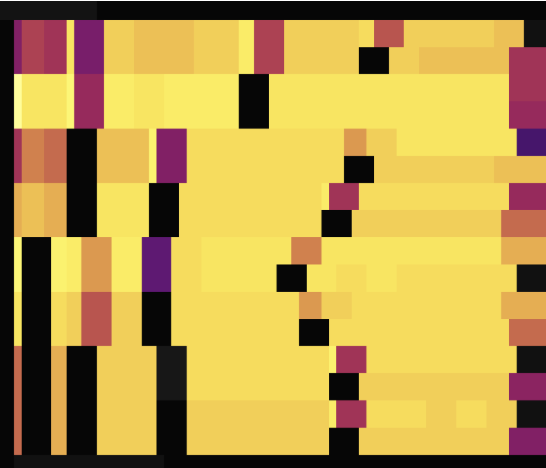
从流量图可见,设置 SHARD_ROW_ID_BITS 后,流量热点由之前的只在一个 Region 上变得很分散。
使用 AUTO_RANDOM 处理自增主键热点表
使用 AUTO_RANDOM 处理自增主键热点表,适用于代替自增主键,解决自增主键带来的写入热点。
使用该功能后,将由 TiDB 生成随机分布且空间耗尽前不重复的主键,达到离散写入、打散写入热点的目的。
注意 TiDB 生成的主键不再是自增的主键,可使用 LAST_INSERT_ID() 获取上次分配的主键值。
将建表语句中的 AUTO_INCREMENT 改为 AUTO_RANDOM 即可使用该功能,适用于主键只需要保证唯一,不包含业务意义的场景。示例如下:
以下是将 AUTO_INCREMENT 表改为 AUTO_RANDOM 打散热点后的流量图,第一张是 AUTO_INCREMENT,第二张是 AUTO_RANDOM。
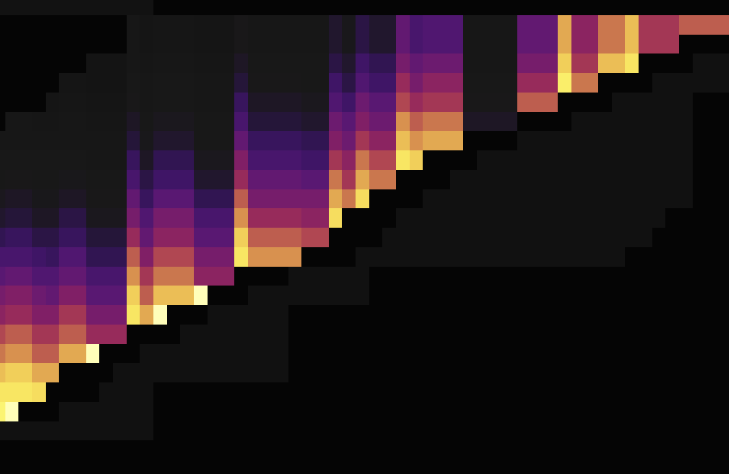

由流量图可见,使用 AUTO_RANDOM 代替 AUTO_INCREMENT 能很好地打散热点。
更详细的说明参见 AUTO_RANDOM 文档。
小表热点的优化
TiDB 的 Coprocessor Cache 功能支持下推计算结果缓存。开启该功能后,将在 TiDB 实例侧缓存下推给 TiKV 计算的结果,对于小表读热点能起到比较好的效果。
更详细的说明参见下推计算结果缓存文档。
其他相关资料:
打散读热点
在读热点场景中,热点 TiKV 无法及时处理读请求,导致读请求排队。但是,此时并非所有 TiKV 资源都已耗尽。为了降低延迟,TiDB v7.1.0 引入了负载自适应副本读取功能,允许从其他 TiKV 节点读取副本,而无需在热点 TiKV 节点排队等待。你可以通过 tidb_load_based_replica_read_threshold 系统变量控制读请求的排队长度。当 leader 节点的预估排队时间超过该阈值时,TiDB 会优先从 follower 节点读取数据。在读热点的情况下,与不打散读热点相比,该功能可提高读取吞吐量 70%~200%。
[转帖]TiDB 热点问题处理的更多相关文章
- 以TiDB热点问题来谈Region的调度流程
什么是热点问题 说这个话题之前我们先回顾一下TiDB的主要结构和概念. TiDB的核心架构分为TiDB.TiKV.PD三个部分,其中TiKV是一个分布式数据存储引擎用来存储真实的数据,在TiKV中又对 ...
- TiDB 架构及设计实现
一. TiDB的核心特性 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移. 水平弹性扩展 ...
- 如何关闭wps热点,如何关闭wpscenter,如何关闭我的wps
用wps已经快十年了,最开始的时候速度快,非常好用,甩office几条街,但最近这几年随着wps胃口越来越大,各种在线功能不断推出,植入广告越来越多,逐渐让人失去欢喜. 通过各种网帖的经验,我把网上流 ...
- [转帖] 数据库用优化方案 https://segmentfault.com/a/1190000006158186
Mysql大表优化方案 当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部 ...
- 三篇文章了解 TiDB 技术内幕 —— 谈调度
任何一个复杂的系统,用户感知到的都只是冰山一角,数据库也不例外. 前两篇文章介绍了 TiKV.TiDB 的基本概念以及一些核心功能的实现原理,这两个组件一个负责 KV 存储,一个负责 SQL 引擎,都 ...
- 网易云社区有奖问答活动第二期——技术领导力、深入分布式、PHP圣经、Linux运维、Unity……三月热点图书等你拿!
网易云社区第二期有奖问答活动开始了!(第一期活动已结束:人工智能图书大抽奖!) 欢迎积极参与网易云社区,讨论问题,交流心得.我们本期准备了一批技术领域热点图书,送给参与社区的朋友们,将以抽奖的形式送出 ...
- [转帖]七牛云对HTTPS 的解释
感觉对RTT 还有 建立连接的说明挺好的 转帖一下 学习 https://www.cnblogs.com/qiniu/p/6856012.html 序•魔戒再现 几天前,OpenSSL ...
- TiDB 在摩拜单车的深度实践及应用
一.业务场景 摩拜单车 2017 年开始将 TiDB 尝试应用到实际业务当中,根据业务的不断发展,TiDB 版本快速迭代,我们将 TiDB 在摩拜单车的使用场景逐渐分为了三个等级: P0 级核心业务: ...
- 创建假的wifi热点
本帖介绍怎么创建假的wifi热点,然后抓取连接到这个wifi用户的敏感数据.我们还会给周围的无线路由器发送未认证的包,使这些路由器瘫痪,强迫用户连接(或自动连接)我们创建的假wifi热点. 这种攻击也 ...
- TIDB4 —— 三篇文章了解 TiDB 技术内幕 - 谈调度
原文地址:https://pingcap.com/blog-cn/tidb-internal-3/ 为什么要进行调度 先回忆一下第一篇文章提到的一些信息,TiKV 集群是 TiDB 数据库的分布式 K ...
随机推荐
- LeetCode 图篇
743. 网络延迟时间 有 N 个网络节点,标记为 1 到 N. 给定一个列表 times,表示信号经过有向边的传递时间. times[i] = (u, v, w),其中 u 是源节点,v 是目标节点 ...
- EDS从小白到专家丨打造你的专属“数据物流”系统
"数据快递"如何支撑便捷就医?本期让我们来了解如何使用EDS打造专属的"数据物流"系统...... 本文分享自华为云社区<[EDS从小白到专家]第2期-E ...
- 云小课|MRS基础原理之Oozie任务调度
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 摘要:Oozie是一个基 ...
- 【火热招募】一文看懂华为云IoT Edge边缘计算开发者大赛技术亮点
摘要:第二届边缘计算开发者大赛已启动,赛程时间将从9月持续到12月,华为云IoT Edge · 边云协同赛道奖金池高达40万元. 近日,第二届边缘计算开发者大赛已启动(查看启动仪式),全球揭榜挂帅火热 ...
- 低至200元 / 月,火山引擎DataLeap帮你搭建企业级数据中台
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 企业数字化转型正席卷全球,这不仅是趋势所在,也是企业发展必然面对的考题.数字化不仅仅考验企业的技术"硬& ...
- PlayWright安装及使用
PlayWright是由业界大佬微软(Microsoft)开源的端到端 Web 测试和自动化库,可谓是大厂背书,功能满格,虽然作为无头浏览器,该框架的主要作用是测试 Web 应用,但事实上,无头浏览器 ...
- POJ - 1190 生日蛋糕(深搜+神奇的剪枝)
链接:https://ac.nowcoder.com/acm/contest/1015/B 题目描述 7月17日是Mr.W的生日,ACM-THU为此要制作一个体积为Nπ的M层生日蛋糕,每层都是一个圆柱 ...
- 20级训练赛Round #5
A - 凯少与素数 签到 & 思维题, 要使每一对数字 \((i,j)\) 的最大公约数都等于 1,简单来说区间相邻的两个数一定 \(gcd(i,j) = 1\) 并且 \((r - l)\) ...
- 实战指南 | Serverless 架构下的应用开发
作者 | 刘宇.田初东.卢萌凯.王仁达 UC Berkeley认为Serverless架构的出现过程类似于40多年前从汇编语言转向高级语言的过程,在未来Serverless架构的使用会飙升,或许服务器 ...
- 最全!即学即会 Serverless Devs 基础入门(下)
作者 | 刘宇(阿里云 Serverless 产品经理) 在上篇<最全!即学即会 Serverless Devs 基础入门>中,我们阐述了工具链的重要性,并对安装方式 & 密钥配置 ...