如何构建面向海量数据、高实时要求的企业级OLAP数据引擎?
在字节跳动各产品线飞速成长的过程中,对数据分析能力也提出了更高的要求,现有的主流数据分析产品都没办法完全满足业务要求。因此,字节跳动在ClickHouse引擎基础上重构了技术架构,实现了云原生环境的部署和运维管理、存储计算分离、多租户管理等能力,推出了云原生数据仓库ByteHouse。
在性能、可扩展性、稳定性、可运维性以及资源利用率方面都实现了巨大提升,能够很好的满足字节跳动数据量极大、实时性要求极高、场景丰富的业务需求。
我们可以从下面几个方面认识ByteHouse:
极致性能
在延续了ClickHouse单表查询强大性能的同时,新增了自研的查询优化器,在多表关联查询和复杂查询场景下性能提升若干倍,实现了在各类型查询中都达到极致性能。
新一代MPP架构,存算分离
使用新式架构,Shared-nothing的计算层和Shared-everything的存储层,可以性能损耗很小的情况下,实现存储层与计算层的分离,独立按需扩缩容。
资源隔离,读写分离
对硬件资源进行灵活切割分配,按需扩缩容。资源有效隔离,读写分开资源管理,任务之间互不影响,杜绝了大查询打满所有资源拖垮集群的现象。
丰富功能
ByteHouse提供客户丰富的企业级能力,如:兼容ANSI-SQL 2011标准、支持多租户、库表资产管理、基于角色的权限管理以及多样的性能诊断工具等。
ByteHouse架构设计
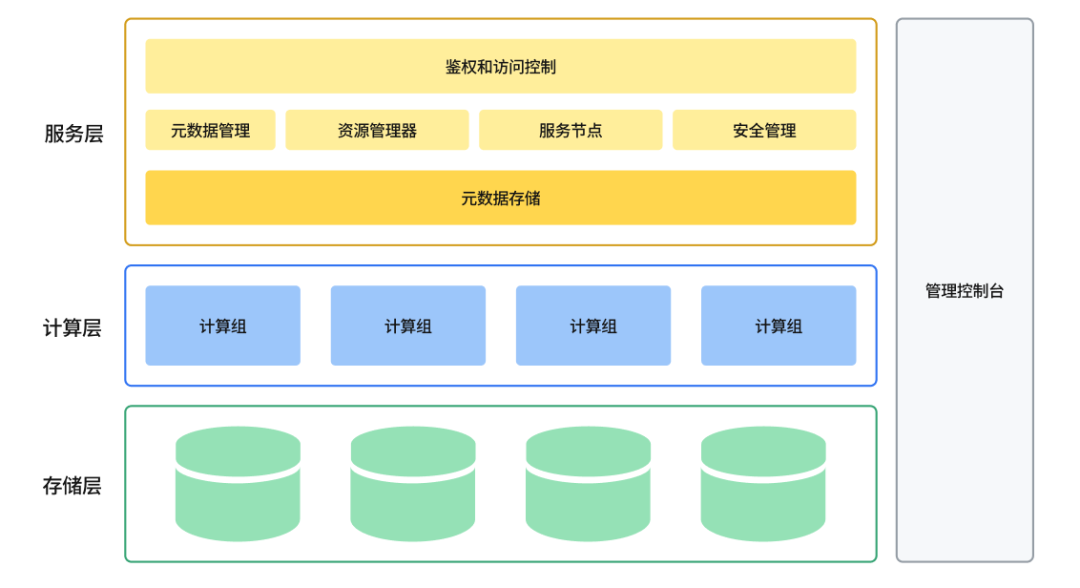
ByteHouse整体架构图
云原生数据仓库ByteHouse总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。
服务层
服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。
服务层主要包括如下组件:
资源管理器
资源管理器(Resource Manager)负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,为查询、写入和后台任务动态分配资源。同时支持计算资源隔离和共享,资源池化和弹性扩缩等功能。资源管理器是提高集群整体利用率的核心组件。
服务节点
服务节点(CNCH Server)可以看成是Query执行的master或者是coordinator。每一个计算组有1个或者多个CNCH Server,负责接受用户的query请求,解析query,生成逻辑执行计划,优化执行计划,调度和执行query,并将最终结果返回给用户。计算组是 Bytehouse 中的计算资源集群,可按需进行横向扩展。
服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。
元数据服务
元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata主要包括2部分:Table的元数据和Part的元数据。表的元数据信息主要包括表的Schema,partitioning schema,primary key,ordering key。Part的元数据信息记录表所对应的所有data file的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。
元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。
元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。
安全管理
权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。
计算层
通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有计算资源都放在容器中。
计算组是计算资源的组织单位,可以将计算资源按需划分为多个虚拟集群。每个虚拟集群里包含0到多台计算节点,可按照实际资源需求量动态的扩缩容。
计算节点主要承担的是计算任务,这些任务可以是用户的查询,也可以是一些后台任务。用户查询和这些后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的资源隔离。
计算组是无状态的,可以快速水平扩展。
存储层
采用HDFS或S3等云存储服务作为数据存储层。用来存储实际数据、索引等内容。
数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如HDFS,Amazon S3, Google cloud storage,Azure blob storage,阿里云对象存储等等。底层存储是天然支持高可用、容量是无限扩展的。
不同的分布式存储系统,例如S3和HDFS有很多不同的功能和不一样的性能,会影响到我们的设计和实现。例如HDFS不支持文件的update, S3 object move操作时重操作需要复制数据等。
通过存储的服务化,计算层可以支持ByteHouse自身的计算引擎之外,将来还可以便捷地对接其他计算引擎,例如Presto、Spark等。
数据导入导出
ByteHouse包括一个数据导入导出(Data Express)模块,负责数据的导入导出工作。
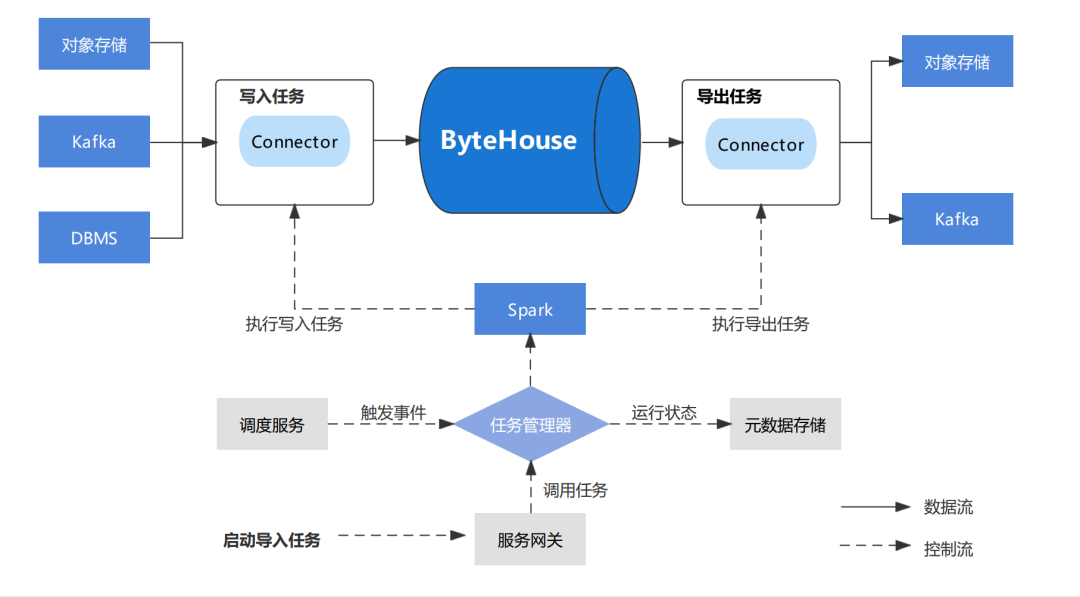
Data Express模块架构图
Data Express 为数据导入/导出作业提供工作流服务和快速配置模板,用户可以从提供的快速模板创建数据加载作业。
DataExpress 利用 Spark 来执行数据迁移任务。
主要模块:
JobServer
导入模板
导出模板
JobServer 管理所有用户创建的数据迁移作业,同时运行外部事件触发数据迁移任务。
启动任务时,JobServer 将相应的作业提交给 Spark 集群,并监控其执行情况。作业执行状态将保存在我们的元存储中,以供 Bytehouse 进一步分析。
ByteHouse支持离线数据导入和实时数据导入。
离线导入
离线导入数据源:
Object Storage:S3、OSS、Minio
Hive (1.0+)
Apache Kafka /Confluent Cloud/AWS Kinesis
本地文件
RDS
离线导入适用于希望将已准备好的数据一次性加载到 ByteHouse 的场景,根据是否对目标数据表进行分区,ByteHouse 提供了不同的加载模式:
全量加载:全量将用最新的数据替换全表数据。
增量加载:增量加载将根据其分区将新的数据添加到现有的目标数据表。ByteHouse 将替换现有分区,而非进行合并。
支持的文件类型
ByteHouse的离线导入支持以下文件格式:
Delimited files (CSV, TSV, etc.)
Json (multiline)
Avro
Parquet
Excel (xls)
实时导入
ByteHouse 能够连接到 Kafka,并将数据持续传输到目标数据表中。与离线导入不同,Kafka 任务一旦启动将持续运行。ByteHouse 的 Kafka 导入任务能够提供 exactly-once 语义。您可以停止/恢复消费任务,ByteHouse 将记录 offset 信息,确保数据不会丢失。
ByteHouse 在流式导入中支持以下消息格式:
Protobuf
JSON
总结
云原生数据仓库ByteHouse是一个具备极致性能、能够存储和计算资源分别按需扩缩容、功能丰富的数据分析产品,是一个面向海量数据、高实时要求的一个企业级OLAP数据引擎。
ByteHouse在字节跳动的众多场景中有着丰富的经验积累,尤其是在实时数据分析场景和海量数据灵活查询场景,都有超大规模的应用。ByteHouse基于自研技术优势和超大规模的使用经验,为企业大数据团队带来新的选择和支持,以应对复杂多变的业务需求,高速增长的数据场景。目前,ByteHouse已在火山引擎上提供免费试用,欢迎大家来尝试,并为我们提出宝贵建议。
如何构建面向海量数据、高实时要求的企业级OLAP数据引擎?的更多相关文章
- Linux海量数据高并发实时同步架构方案杂谈
不论是Redhat还是CentOS系统,除去从CDN缓存或者数据库优化.动静分离等方面来说,在架构层面上,实 现海量数据高并发实时同步访问概括起来大概可以从以下几个方面去入手,当然NFS的存储也可以是 ...
- Socket.IO – 基于 WebSocket 构建跨浏览器的实时应用
Socket.IO 是一个功能非常强大的框架,能够帮助你构建基于 WebSocket 的跨浏览器的实时应用.支持主流浏览器,多种平台,多种传输模式,还可以集合 Exppress 框架构建各种功能复杂 ...
- 基于 WebSocket 构建跨浏览器的实时应用
Socket.IO – 基于 WebSocket 构建跨浏览器的实时应用 Socket.IO 是一个功能非常强大的框架,能够帮助你构建基于 WebSocket 的跨浏览器的实时应用.支持主流浏览器,多 ...
- 构建可读性更高的 ASP.NET Core 路由
原文:构建可读性更高的 ASP.NET Core 路由 一.前言 不知你在平时上网时有没有注意到,绝大多数网站的 URL 地址都是小写的英文字母,而我们使用 .NET/.NET Core MVC 开发 ...
- 实时分布式低延迟OLAP数据库Apache Pinot探索实操
@ 目录 概述 定义 特性 何时使用 部署 Local安装 快速启动 手动设置集群 Docker安装 快速启动 手动启动集群 Docker Compose 实操 批导入数据 流式导入数据 概述 定义 ...
- 阿里云智能数据构建与管理 Dataphin公测,助力企业数据中台建设
阿里云智能数据构建与管理 Dataphin (下简称“Dataphin”)近日重磅上线公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客 ...
- Tapdata肖贝贝:实时数据引擎系列(三) - 流处理引擎对比
摘要:本文将选取市面上一些流计算框架包括 Flink .Spark .Hazelcast,从场景需求出发,在核心功能.资源与性能.用户体验.框架完整性.维护性等方面展开分析和测评,剖析实时数据框架 ...
- ElasticSearch做实时OLAP框架~实时搜索、统计和OLAP需求,甚至可以作为NOSQL来使用(转)
使用ElasticSearch作为大数据平台的实时OLAP框架 – lxw的大数据田地 http://lxw1234.com/archives/2015/12/588.htm 一直想找一个用于大数据平 ...
- Tapdata 肖贝贝:实时数据引擎系列(四)-关于 Oracle 与 Oracle CDC
摘要:想实现 Oracle 的 CDC,排除掉一些通用的比如全量比对, 标记字段获取之外, 真正的增量形式获取变更, 有三种办法: Logminer .XStream .裸日志解析,但不管哪种方法 ...
- 性能测试 CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据
CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 2 1.安装influxdb ...
随机推荐
- influxdb报错:cache-max-memory-size exceeded
转载请注明出处: influxdb报错日志: 该错误信息表示 InfluxDB 引擎超过了缓存最大内存大小.这意味着 InfluxDB 的缓存使用量超出了配置的限制. 要解决此问题,可以采取以下步骤来 ...
- Ocserv整合Radius认证
目前社区主流SSL VPN有两个分支:openvpn和ocserv,通过官网和检索到的资料对比前者服务端比较强大,后者客户端和移动端支持更好,二者并不兼容: 另外前者商业化封装更好,偏向商业化,后者对 ...
- 集合-Nim游戏
与普通\(NIM\)游戏不同的地方是限制了每次拿东西的个数,这个个数会给定在集合\(S\)中,也就是说每次拿的数量只能在集合\(S\)中. 现在就可以把每一堆石子看成是一个有向图了,最主要就是用记忆化 ...
- Ubuntu环境下C++使用onnxruntime和Opencv进行YOLOv8模型部署
目录 环境配置 系统环境 项目文件路径 文件环境 config.txt CMakeLists.txt type.names 读取config.txt配置文件 修改图片尺寸格式 读取缺陷标志文件 生成缺 ...
- 解密Spring Cloud微服务调用:如何轻松获取请求目标方的IP和端口
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. 目的 Spring Cloud 线上微服务实例都是2个起步,如果出问题后,在没有ELK等日志分析平台,如何确定调用到了目标 ...
- 【Android】无法通过drawable下的selector类型改变背景颜色?
举例 我在darwable目录下创建了selector文件,并设置了如下内容 <?xml version="1.0" encoding="utf-8"?& ...
- 洛谷3521 [POI2011]ROT-Tree Rotations(线段树合并)
题意:给定一颗有 n 个叶节点的二叉树.每个叶节点都有一个权值pi(注意,根不是叶节点),所有叶节点的权值构成了一个1∼n 的排列.对于这棵二叉树的任何一个结点,保证其要么是叶节点,要么左右两个孩子 ...
- 黑客玩具入门——5、继续Metasploit
1.利用FTP漏洞并植入后门 实验靶机:Metasploitable2. 实践: 使用nmap扫描目标靶机 nmap -sV xxx.xxx.xxx.xxx(目标ip) 生成linux系统后门 msf ...
- bi报表软件开发的特点什么,产品和流程?
BI报表软件是一种针对企业数据分析和决策支持的工具,具有高度灵活性和易用性.在当前数据化的时代,越来越多的企业开始关注BI报表软件的开发和应用,因为它们可以帮助企业更好地管理数据,更好地进行商业决策. ...
- 神经网络入门篇:详解参数VS超参数(Parameters vs Hyperparameters)
参数 VS 超参数 什么是超参数? 比如算法中的learning rate \(a\)(学习率).iterations(梯度下降法循环的数量).\(L\)(隐藏层数目).\({{n}^{[l]}}\) ...