机器学习-决策树系列-GBDT算法-集成学习-30
1. 复习
再开始学习GBDT算法之前 先复习一下之前的 线性回归 逻辑回归(二分类) 多分类
- 线性回归
找到一组W 使得 L 最小 进而求得F*
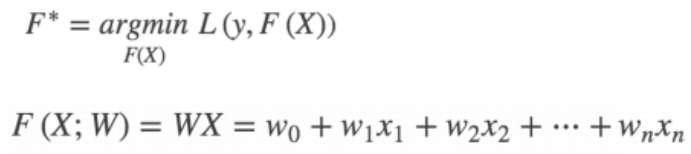
使用梯度下降法:
梯度下降的方向: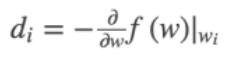
不断更新w: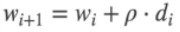
最终求得的w 可以表示为:
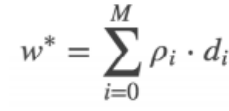
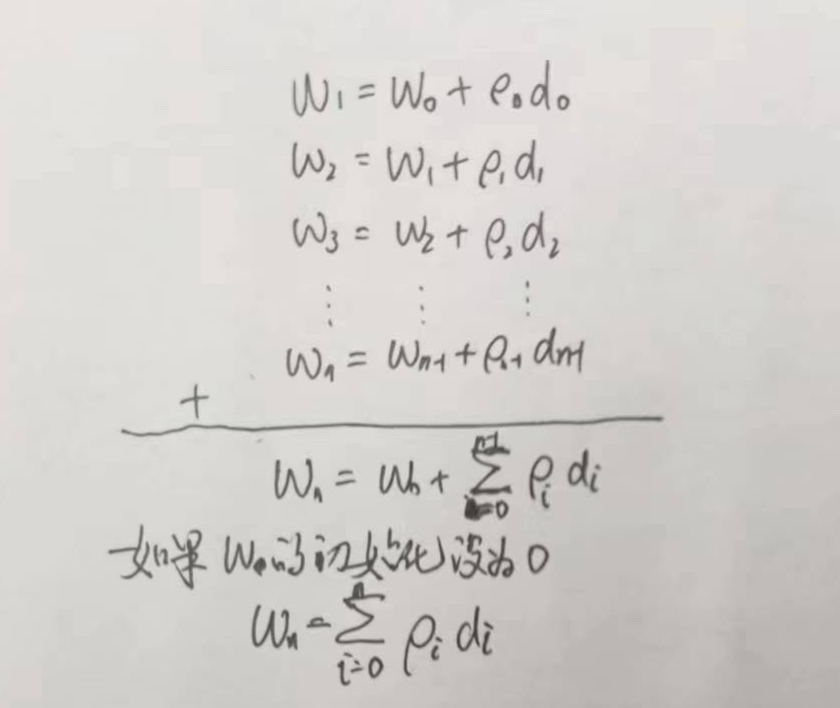
2.逻辑回归
逻辑回归 是 用于处理二分类的问题
只不过是将线性回归的输出 Wx结果 再用sigmoid函数 映射到 0-1 之间
sigmoid函数:
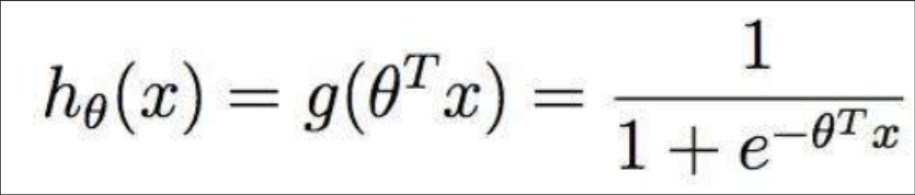
逻辑回归预测的结果是该样本为正例的概率
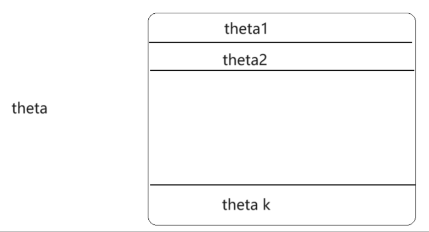
- 多分类
多分类: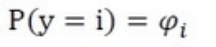
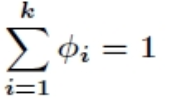
多分类求解的θ 跟线性回归的w不一样 而是一个矩阵
对于任意一条样本:

2. GBDT
gradient boost decision tree
初始化 第0棵 树 f0 (初始化的值 可以给0 为了快速拟合 给定一个先验概率 例如统计正例的比例)
计算残值 y-y_hat 训练第一棵树 f1
再计算残值 再训练 第二棵树 f2
...
直到满足收敛条件
模型做预测:sum(f1+f2+...+fm)
gbdt用于回归树
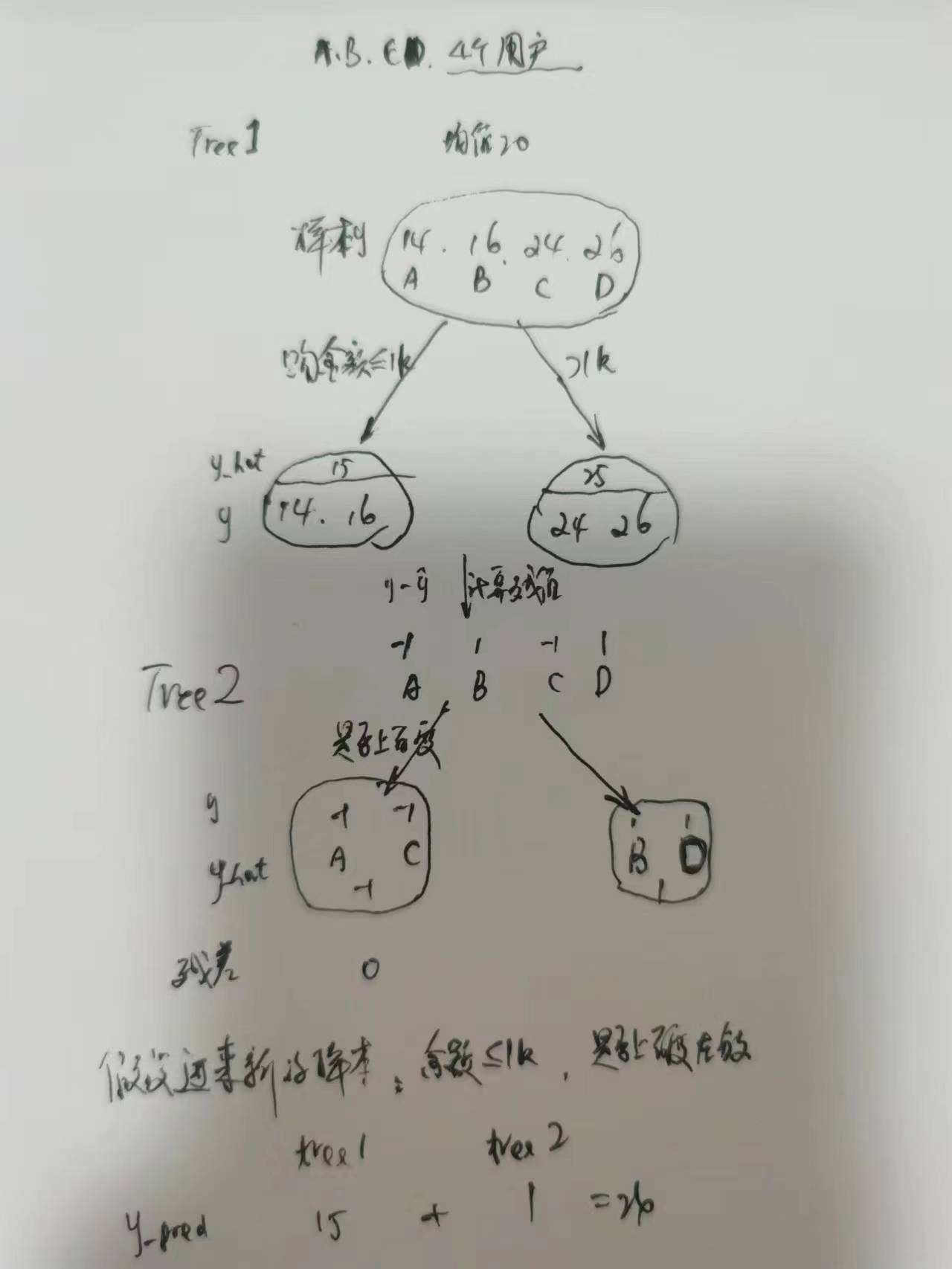
每一次计算都是为了减少上一次的残差。
AdaBoosting中关注正确错误的样本加权,也就是下一次会更重视上一次分错的。
3. gbdt应用于二分类:
之前学的逻辑回归,本质上是用一个线性模型去拟合对数几率: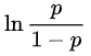

GBDT处理二分类也是一样,只是用一系列的梯度提升树去拟合这个对数几率。
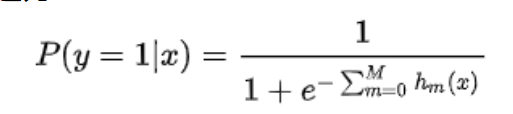
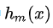
就是学习到的决策树
单条样本的熵:
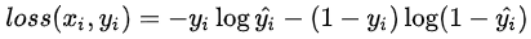
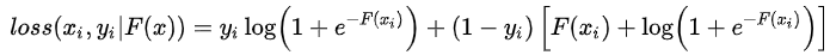
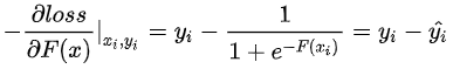
因此,与回归问题很类似,下一棵决策树的训练样本为: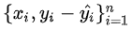
需要拟合的残差为真实标签与预测概率之差。
GBDT应用于二分类的算法:
1, 初始化: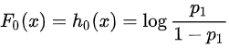
训练样本中y=1的比例,利用先验信息来初始化学习器
2. 训练的次数 for m=1, 2, 3, ...
3. 计算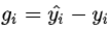
得到训练样本: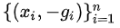
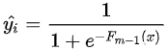
4. 得到学习器
3. gbdt应用于多类
多分类问题,则需要考虑以下softmax模型:
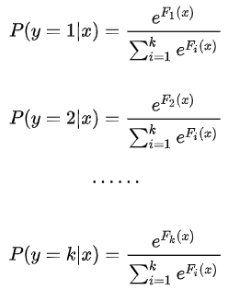
每一轮的训练实际上是训练了 k 棵树去拟合softmax的每一个分支模型的负梯度。
softmax模型的单样本损失函数为:
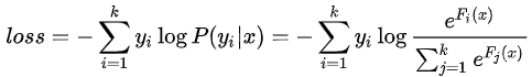
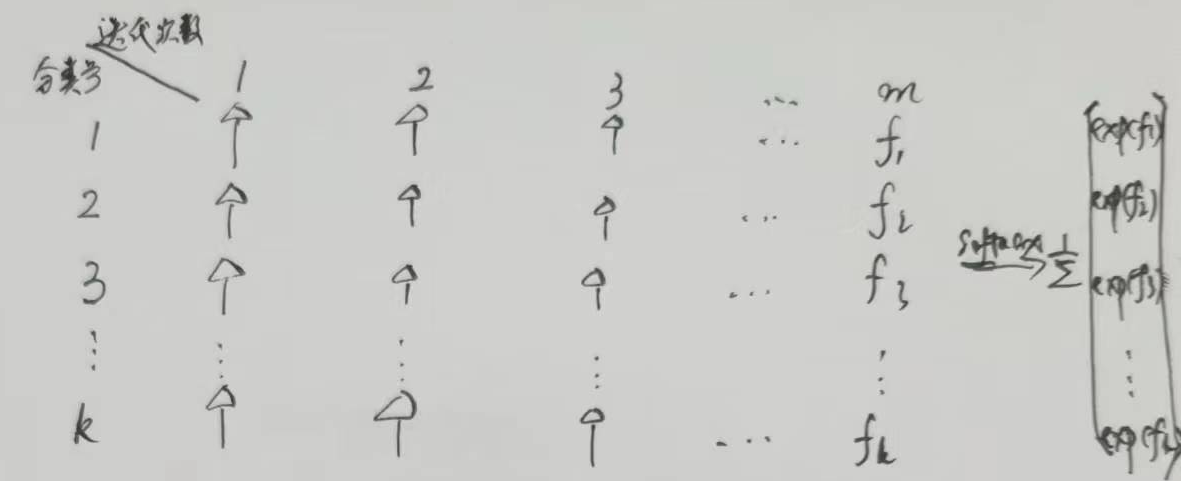
4. 叶子节点输出值c的计算
对于新生成的树,计算各个叶子节点的最佳残差拟合值c:
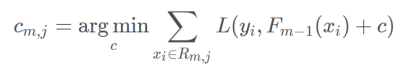
对于m次迭代, 所有落入j
推导过程:

GBDT算法:
- init
- -gradient
- leaf node value update
5. GBDT的其他应用
- 特征重要度
树在做分叉的时候是根据某一特征值 来进行的
特征j在单颗树中的重要度,是计算特征j在单颗树中带来的收益之和
例如:
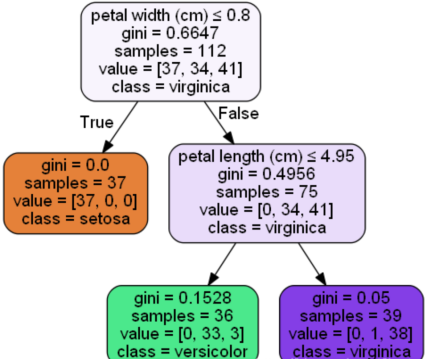
petal width (cm)就是根节点:feature importance=(112∗0.6647−75∗0.4956−37∗0)/112=0.5564007189
petal length (cm)的featureimportance=(75∗0.4956−39∗0.05−36∗0.1528)/112=0.4435992811
- 特征组合对特征降维
GBDT + LT
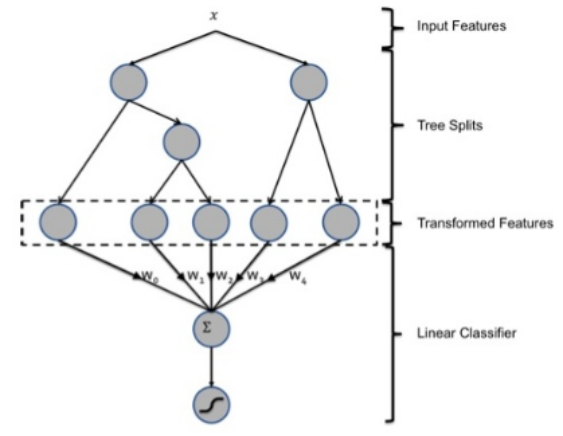
将X的特征(很多维度 几百个 甚至更多) 转化成GBDT输出的 几个组合特征
feature_1 feature_2, feature_3, feature_4, feature_5
x1 0 1 0 0 0
x2 1 0 0 0 0
...
再用这些新的特征去做一个LR 线性回归 给出预测值
6. GBDT+LR 代码实现
import numpy as np
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.linear_model._logistic import LogisticRegression
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
from sklearn.metrics._ranking import roc_auc_score
class GradientBoostingWithLr(object):
def __init__(self):
self.gbdt_model = None
self.lr_model = None
self.gbdt_encoder = None
self.X_train_leafs = None
self.X_test_leafs = None
self.X_trans = None # GBDT 转后之后的X
def gbdt_train(self, X_train, y_train):
"""
训练GBDT模型
:return:
"""
gbdt_model = GradientBoostingClassifier(
n_estimators=10,
max_depth=6,
verbose=0,
max_features=0.5 # 训练的时候 会计算那哪些特征 的收益 取最小 features are considered at each split.
)
gbdt_model.fit(X_train, y_train)
return gbdt_model
def lr_train(self, X_train, y_train):
lr_model = LogisticRegression()
lr_model.fit(X_train, y_train)
return lr_model
def gbdt_lr_train(self, X_train, y_train):
self.gbdt_model = self.gbdt_train(X_train, y_train)
# one_hot
self.X_train_leafs = self.gbdt_model.apply(X_train)[:, :, 0]
# print(self.X_train_leafs[0])
self.gbdt_encoder = OneHotEncoder(categories="auto", sparse=False)
self.X_transform= self.gbdt_encoder.fit_transform(self.X_train_leafs)
# print(self.X_transform[0])
self.lr_model = self.lr_train(self.X_transform, y_train)
def predict(self, X_test, _test):
self.X_test_leafs = self.gbdt_model.apply(X_test)[:, :, 0]
(train_rows, cols) = self.X_train_leafs.shape
X_trans_all = self.gbdt_encoder.fit_transform(np.concatenate((self.X_train_leafs, self.X_test_leafs), axis=0))
y_pred = self.lr_model.predict_proba(X_trans_all[train_rows:])[:, 1]
print(roc_auc_score(y_test, y_pred))
def load_data():
iris_data = load_iris()
X = iris_data.data
y = iris_data.target == 2 # 原结果输出的是 0,1,2 根据是否==2 转化成 0,1
return train_test_split(X, y, test_size=0.4, random_state=0)
if __name__ == '__main__':
X_train, X_test, y_train, y_test = load_data()
gblr = GradientBoostingWithLr()
gblr.gbdt_lr_train(X_train, y_train)
gblr.predict(X_test, y_test)
机器学习-决策树系列-GBDT算法-集成学习-30的更多相关文章
- 机器学习笔记(九)---- 集成学习(ensemble learning)【华为云技术分享】
集成学习不是一种具体的算法,而是在机器学习中为了提升预测精度而采取的一种或多种策略.其原理是通过构建多个弱监督模型并使用一定策略得到一个更好更全面的强监督模型.集成学习简单的示例图如下: 通过训练得到 ...
- 机器学习-决策树之ID3算法
概述 决策树(Decision Tree)是一种非参数的有监督学习方法,它是一种树形结构,所以叫决策树.它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回 ...
- 机器学习--聚类系列--DBSCAN算法
DBSCAN算法 基本概念:(Density-Based Spatial Clustering of Applications with Noise) 核心对象:若某个点的密度达到算法设定的阈值则其为 ...
- 机器学习--聚类系列--K-means算法
一.聚类 聚类分析是非监督学习的很重要的领域.所谓非监督学习,就是数据是没有类别标记的,算法要从对原始数据的探索中提取出一定的规律.而聚类分析就是试图将数据集中的样本划分为若干个不相交的子集,每个子集 ...
- 机器学习——集成学习(Bagging、Boosting、Stacking)
1 前言 集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器.弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 5. 集成学习(Ensemble Learning)GBDT
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 1. 集成学习(Ensemble Learning)原理
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 3. 集成学习(Ensemble Learning)随机森林(Random Forest)
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 2. 集成学习(Ensemble Learning)Bagging
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- .Net 8与硬件设备能碰撞出怎么样的火花(使用ImageSharp和Protobuf协议通过HidApi与设备通讯)
前言 本人最近在社区里说想做稚晖君的那个瀚文键盘来着,结果遇到两个老哥一个老哥送了我电路板,一个送了我焊接好元件的电路板,既然大家这么舍得,那我也就真的投入制作了这把客制化键盘,当然我为了省钱也是特意 ...
- 华企盾DSC客户端服务无法启动一直处于启动停止状态
该问题有两种情况: 1.客户端安装有问题,5097目录缺少文件,解决方法见下面详细信息 2.客户端本地数据库出现问题,需要卸载客户端以及删除对应的本地数据库备份文件(解决方法见下面详细信息) 3.由于 ...
- 万界星空科技MES系统中的生产调度流程
MES系统生产调度的目标是达到作业有序.协调.可控和高效的运行效果,作业计划的快速生成以及面向生产扰动事件的快速响应处理是生产调度系统的核心和关键. 为了顺利生成作业计划,需要为调度系统提供完整的 ...
- 如何在SAP GUI中快速执行新的事务代码
当我们成功登录SAP的某个连接后,在SAP GUI起始页(SAP轻松访问),我们可以通过点击[收藏夹]或者在界面左上角的输入框输入对应的事务代码,直接进入对应事务的界面.但是下面列举的场景,你是否知道 ...
- 什么是HuggingFace
一.HuggingFace简介 1.HuggingFace是什么 可以理解为对于AI开发者的GitHub,提供了模型.数据集(文本|图像|音频|视频).类库(比如transformers|peft|a ...
- 云图说|什么是可信智能计算服务TICS
阅识风云是华为云信息大咖,擅长将复杂信息多元化呈现,其出品的一张图(云图说).深入浅出的博文(云小课)或短视频(云视厅)总有一款能让您快速上手华为云.更多精彩内容请单击此处. 本文分享自华为云社区&l ...
- 盘点Python 中字符串的常用操作
摘要:盘点 Python 中字符串的几个常用操作,对新手极度的友好. 本文分享自华为云社区<盘点 Python 中字符串的常用操作,对新手极度友好>,作者:TT-千叶 . 在 Python ...
- 初探语音识别ASR算法
摘要:语音转写文字ASR技术的基本概念与数学原理简介. 本文分享自华为云社区<新手语音入门(三): 语音识别ASR算法初探 | 编码与解码 | 声学模型与语音模型 | 贝叶斯公式 | 音素> ...
- PPT 求职应聘:如何利用PPT去制作简历
PPT 求职应聘:如何利用PPT去制作简历 知识的载体 传播.美学.价值 价值:是通过思考 价值:将PPT导成了长图放到了微薄, 如何制作简历 09:00
- 【PS算法理论探讨三】 Photoshop中图层样式之 颜色叠加/渐变叠加/图案叠加 算法原理初探讨。
这三个表面上看上去很简单,我们就先描述简单的部分. 颜色叠加:这个和编辑菜单下的填充 颜色 基本是一个意思,相当于在原有的图层上部添加了一个纯实色的虚拟图层,选项里的不透明度和混合模式和普通的概念是一 ...