爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接。
环境和方法:ubantu16.04、python3、requests、xpath
1.用浏览器打开知乎,并登录
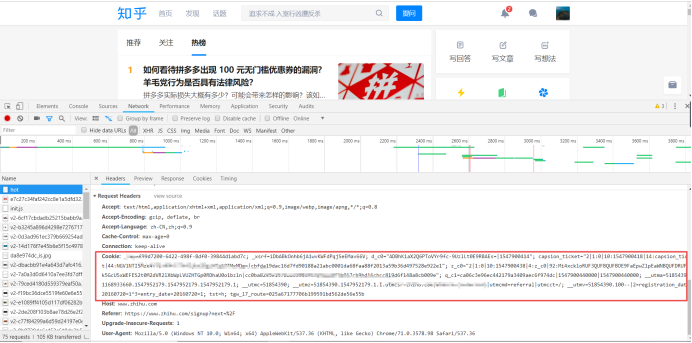
2.获取cookie和User—Agent
3.上代码
import requests
from lxml import etree def get_html(url):
headers={
'Cookie':'你的Cookie',
#'Host':'www.zhihu.com',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
} r=requests.get(url,headers=headers) if r.status_code==200:
deal_content(r.text) def deal_content(r):
html = etree.HTML(r)
title_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/h2')
link_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/@href')
for i in range(0,len(title_list)):
print(title_list[i].text)
print(link_list[i])
with open("zhihu.txt",'a') as f:
f.write(title_list[i].text+'\n')
f.write('\t链接为:'+link_list[i]+'\n')
f.write('*'*50+'\n') def main():
url='https://www.zhihu.com/hot'
get_html(url) main()
4.爬取结果

爬取知乎热榜标题和连接 (python,requests,xpath)的更多相关文章
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
随机推荐
- 【分享·微信支付】 C# MVC 微信支付教程系列之公众号支付
微信支付教程系列之公众号支付 今天,我们接着讲微信支付的系列教程,前面,我们讲了这个微信红包和扫码支付.现在,我们讲讲这个公众号支付.公众号支付的应用环境常见的用户通过公众号,然后 ...
- mysql那些招
show table status mysql官方文档在 http://dev.mysql.com/doc/refman/5.1/en/show-table-status.html 这里的rows行是 ...
- ThreadState属性
这个属性代表了线程运行时状态,在不同的情况下有不同的值,我们有时候可以通过对该值的判断来设计程序流程. ThreadState 属性的取值如下: Aborted:线程已停止: AbortRequest ...
- KVO 的进一步理解
这篇文章讲述了KVO的深入理解 http://blog.csdn.net/kesalin/article/details/8194240 对kvo有了更深入的理解 如下连接的文章讲述了kvo接口的一些 ...
- SQL的别名和SQL的执行顺序和SQL优化
SQL的别名 1.不可以在where子句中使用列名的别名,即select name t from emp where t>2999;是不允许的 2.使用别名的好处: 提高SQL的易读性 提高SQ ...
- python 爬虫部分解释
example:self.file = www.baidu.com存有baidu站的index.html def parseAndGetLinks(self): # parse HTML, save ...
- POJ2724 Purifying Machine
嘟嘟嘟 扒下来的题意:迈克有一台可以净化奶酪的机器,用二进制表示净化的奶酪的编号.但是,在某些二进制串中可能包含有\(*\).例如\(01*100\),\(*\)其实就代表可以取\(0\),\(1\) ...
- 【小游戏】flappy pig
(1)这款游戏的画面很简单:一张背景图,始终就没有变过: (2)这款游戏的对象只有俩:一个小鸟(有三种挥动翅膀的状态)以及一对管道(有管道向上和向下两个方向): http://www.cnblogs. ...
- leetcode300. Longest Increasing Subsequence 最长递增子序列 、674. Longest Continuous Increasing Subsequence
Longest Increasing Subsequence 最长递增子序列 子序列不是数组中连续的数. dp表达的意思是以i结尾的最长子序列,而不是前i个数字的最长子序列. 初始化是dp所有的都为1 ...
- ThinkPHP5入门(三)----模型篇
一.操作数据库 1.数据库连接配置 数据库默认的相关配置在项目的application\database.php中已经定义好. 只需要在模块的数据库配置文件中配置好当前模块需要连接的数据库的配置参数即 ...