爬取知乎热榜标题和连接 (python,requests,xpath)
用python爬取知乎的热榜,获取标题和链接。
环境和方法:ubantu16.04、python3、requests、xpath
1.用浏览器打开知乎,并登录
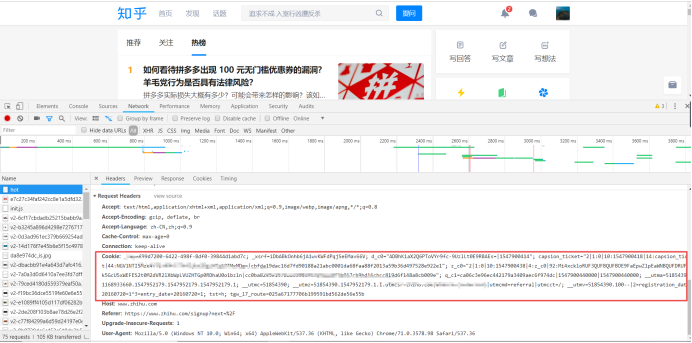
2.获取cookie和User—Agent
3.上代码
import requests
from lxml import etree def get_html(url):
headers={
'Cookie':'你的Cookie',
#'Host':'www.zhihu.com',
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36'
} r=requests.get(url,headers=headers) if r.status_code==200:
deal_content(r.text) def deal_content(r):
html = etree.HTML(r)
title_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/h2')
link_list = html.xpath('//*[@id="TopstoryContent"]/div/section/div[2]/a/@href')
for i in range(0,len(title_list)):
print(title_list[i].text)
print(link_list[i])
with open("zhihu.txt",'a') as f:
f.write(title_list[i].text+'\n')
f.write('\t链接为:'+link_list[i]+'\n')
f.write('*'*50+'\n') def main():
url='https://www.zhihu.com/hot'
get_html(url) main()
4.爬取结果

爬取知乎热榜标题和连接 (python,requests,xpath)的更多相关文章
- python抓取知乎热榜
知乎热榜讨论话题,https://www.zhihu.com/hot,本文用python抓取下来分析 #!/usr/bin/python # -*- coding: UTF-8 -*- from ur ...
- python实战项目 — 使用bs4 爬取猫眼电影热榜(存入本地txt、以及存储数据库列表)
案例一: 重点: 1. 使用bs4 爬取 2. 数据写入本地 txt from bs4 import BeautifulSoup import requests url = "http:// ...
- 16、爬取知乎大v张佳玮的文章“标题”、“摘要”、“链接”,并存储到本地文件
爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # 爬取知乎大v张佳玮的文章“标题”.“摘要”.“链接”,并存储到本地文件 # URL https://www.zhihu.co ...
- 使用python scrapy爬取知乎提问信息
前文介绍了python的scrapy爬虫框架和登录知乎的方法. 这里介绍如何爬取知乎的问题信息,并保存到mysql数据库中. 首先,看一下我要爬取哪些内容: 如下图所示,我要爬取一个问题的6个信息: ...
- scrapy 爬取知乎问题、答案 ,并异步写入数据库(mysql)
python版本 python2.7 爬取知乎流程: 一 .分析 在访问知乎首页的时候(https://www.zhihu.com),在没有登录的情况下,会进行重定向到(https://www. ...
- 40行代码爬取猫眼电影TOP100榜所有信息
主要内容: 一.基础爬虫框架的三大模块 二.完整代码解析及效果展示 1️⃣ 基础爬虫框架的三大模块 1.HTML下载器:利用requests模块下载HTML网页. 2.HTML解析器:利用re正则表 ...
- 通过scrapy,从模拟登录开始爬取知乎的问答数据
这篇文章将讲解如何爬取知乎上面的问答数据. 首先,我们需要知道,想要爬取知乎上面的数据,第一步肯定是登录,所以我们先介绍一下模拟登录: 先说一下我的思路: 1.首先我们需要控制登录的入口,重写star ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet mail:vpoet_sir@163.com 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 # ...
随机推荐
- 用POP动画编写带富文本的自定义动画效果
用POP动画编写带富文本的自定义动画效果 [源码] https://github.com/YouXianMing/UI-Component-Collection [效果] [特点] * 支持富文本 * ...
- [翻译] KVNProgress
KVNProgress KVNProgress is a fully customizable progress HUD that can be full screen or not. KVNProg ...
- Java学习---JAVA的类设计
基础知识 JAVA是由C/C++语言发展而来的纯面向对象语言,其基本元素包括:简单数据类型 和 复合数据类型(即类).类是对客观事物的抽象描述,它有面向对象的四个特点,即:封装性.继承性.多态性和通信 ...
- Java实例---简单的个人管理系统
代码分析 FileOperate.java package com.ftl.testperson; import java.io.File ; import java.io.FileInputStre ...
- 无法用Put方式请求发布在IIS中的WebAPI
WebApi程序发布到IIS上后,无法使用Put的方式进行请求,错误信息如下: 原因和解决方案: 在IIS中默认不支持Put请求和Delete请求,因为IIS中注册的Web ...
- C#网络编程(一)基础篇
简介: C#网络编程API包含在System.Net和System.Net.Sockets命名空间下,大部分网络操作都可以在其中找到相应的类来实现:包括Socket的创建和连接,网络流收发方法的封装, ...
- 为OS X增加环境变量
1.创建并以 TextEdit 的方式打开 ~/.bash_profile 文件 touch ~/.bash_profile; open -t ~/.bash_profile 2.新增环境变量 exp ...
- HTTP协议图--HTTP 报文首部之请求行、状态行
1.请求行 举个栗子,下面是一个 HTTP 请求的报文: GET /index.htm HTTP/1.1 Host: sample.com 其中,下面的这行就是请求行, GET /index.htm ...
- 【React】使用 create-react-app 快速构建 React 开发环境
create-react-app 是来自于 Facebook,通过该命令我们无需配置就能快速构建 React 开发环境. create-react-app 自动创建的项目是基于 Webpack + E ...
- 关于numpy mean函数的axis参数
import numpy as np X = np.array([[1, 2], [4, 5], [7, 8]]) print np.mean(X, axis=0, keepdims=True) pr ...