《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #13 使用Block I/O控制器设置I/O优先级
HACK #13 使用Block I/O控制器设置I/O优先级
本节介绍使用Block I/O控制器的功能设置I/O优先级的方法。
Block I/O控制器可以将任意进程分组,并对该分组设置I/O的优先级。这个功能是在Linux 2.6.33时添加到Linux内核中的。例如,在前台进行一般处理的同时,在后台磁盘备份处理的情况下,如果备份处理频繁地向磁盘进行I/O操作,前台的处理即使有I/O请求,也不能立刻进行I/O处理,结果导致前台处理的性能下降。
Block I/O控制器在这种情况下就非常有效。创建I/O优先级较高的分组和较低的分组,并将前台处理的进程和后台处理的进程分别分配到这些分组中。这样可以使前台处理的I/O优先于后台处理,防止性能下降。
本节将介绍Block I/O控制器的使用方法。使用的Linux内核版本为2.6.35。
使用Block I/O控制器的前提条件
Block I/O控制器是Cgroup的子系统之一,是作为I/O调度程序之一的CFQ的一部分安装的。因此,使用Block I/O控制器时,必须使用启用了下列config选项编译的内核。
CONFIG_BLK_CGROUP
CONFIG_CFQ_GROUP_IOSCHED
确认Cgroup支持
首先确认运行中的内核是否支持Cgroup和Cgroup子系统Block I/O控制器。如果有/proc/cgroups,运行中的内核就可以支持Cgroup。/proc/cgroups的内容如下。
$ cat /proc/cgroups
subsys_name hierarchy num_cgroups enabled
blkio 1 1 1
只要subsys_name列显示了blkio,且enabled为1就没问题。如果看不到blkio,就需要重新编译内核。如果enabled为0,则启动时的内核命令行应当如下所示。
cgroup_disabled=blkio
这时需要修改/boot/grub/grub.conf等,将上述指定从内核命令行中删除,并重新启动。
确认CFQ支持
接下来确认是否能够将CFQ作为I/O调度程序使用。例如,想要查看块设备sdb中可以使用的I/O调度程序时,需要执行下列命令。
$ cat /sys/class/block/sdb/queue/scheduler
noop deadline [cfq]
可以使用的I/O调度程序会显示出来,其中当前选择的调度程序已加上了方括号。如果显示cfq则没问题;如果不显示就需要启用CFQ,重新编译内核。
注意事项:设备种类不同,scheduler文件的内容也不同。I/O调度程序是对一般的块设备使用的,因此,例如在loopback设备loop0等中不会显示cfq。请对sda、sdb等一般的块设备进行确认。
尝试使用Block I/O控制器
Block I/O控制器的设置通过cgroup文件系统进行。关于Cgroup和cgroup文件系统的基本情况请参考Hack #7。
首先挂载cgroup文件。将blkio作为挂载选项,指定将Block I/O控制器作为子系统使用。
# mount -t cgroup -o blkio cgroup/cgroup
然后,在CFQ中为想要控制I/O优先级的块设备设置I/O调度程序。这里使用的块设备是sdb。
# echo cfq > /sys/class/block/sdb/queue/scheduler
$ cat /sys/class/block/sdb/queue/scheduler
noop deadline [cfq]
这时,使用Block I/O控制器前的准备工作就完成了。为了方便讲解,在这里创建优先级较高的分组“high”和优先级较低的分组“low”,并分别向各分组分配1个进程来观察I/O的情况。首先创建分组。
# mkdir /cgroup/high
# mkdir /cgroup/low
对各分组设置I/O的优先级。设置优先级时,在blkio.weight中写入100~1000的“weight值”。初始值为500,值越大表示优先级越高。
# echo 1000 > /cgroup/high/blkio.weight
# echo 100 > /cgroup/low/blkio.weight
小贴士:仅根分组的weight初始值为1000。
为了进行测试,制作一个简单的脚本。这个脚本将进程添加到所指定的两个分组low和high,分别计算出读文件所需的时间。创建如下的“blkio_test.sh”脚本,并为其赋予执行权限。
#! /bin/sh
# blkio_test.sh
# Test script for Block IO Controller
# read /mnt/sdb/low.dat ($flow) as cgroup $cg_low
# and read /mnt/sdb/high.dat ($fhigh) as cgroup $cg_high simultaneously.
#
# $1: cgroup path for lower priority (--> $cg_low)
# $2: cgroup path for higher priority (--> $cg_high)
function print_usage()
{
echo "usage: $0 <cgroup_low> <cgroup_high>"
exit 1
}
##############################
# params and variables
flow=/mnt/sdb/low.dat
fhigh=/mnt/sdb/high.dat
# cgroups to which processes will be asigned
if [ $# != 2 ]; then
print_usage
fi
cg_low=$1
cg_high=$2
for cg in $cg_low $cg_high; do
if [ ! -d $cg ]; then
echo "$cg does not exists"
print_usage
fi
done
# temporary files
out_low=$(mktemp)
out_high=$(mktemp)
##############################
# sync, drop caches and read files
echo -n "sync and drop all caches..."
sync
echo 3 > /proc/sys/vm/drop_caches
echo "done"
echo -n "reading files..."
echo
$$
> $cg_low/tasks
(time dd if=$flow of=/dev/null) > $out_low 2>&1 &
echo
$$
> $cg_high/tasks
(time dd if=$fhigh of=/dev/null) > $out_high 2>&1 &
wait
echo "done"
##############################
# print the results
echo "--------------------"
echo "dd in $cg_low:"
cat $out_low
echo "--------------------"
echo "dd in $cg_high:"
cat $out_high
rm -f $out_low $out_high
首先,在不分组的情况下进行测试。使用同属于根分组的两个进程,同时读入文件。由于脚本读入的是/mnt/sdb/low.dat、/mnt/sdb/high.dat文件,因此需要先创建两个大小适当的文件,再运行脚本。这里创建了约400MB的文件并执行相关代码。
# dd if=/dev/zero of=/mnt/sdb/low.dat bs=1M count=400
# dd if=/dev/zero of=/mnt/sdb/high.dat bs=1M count=400
# ./blkio_test.sh /cgroup /cgroup
--------------------
dd in /mnt/cgroups:
819200+0 records in
819200+0 records out
419430400 bytes (419 MB) copied, 14.0493 s, 29.9 MB/s
real 0m14.156s
user 0m0.261s
sys 0m1.183s
--------------------
dd in /mnt/cgroups:
819200+0 records in
819200+0 records out
419430400 bytes (419 MB) copied, 14.2007 s, 29.5 MB/s
real 0m14.292s
user 0m0.281s
sys 0m1.186s
两个进程同样使用约14秒的时间完成读入。接下来,在分组的情况下进行测试。将两个进程分别添加到low、high分组中,同时读入文件。
# ./blkio_test.sh /cgroup/low /cgroup/high
--------------------
dd in /cgroup/low:
819200+0 records in
819200+0 records out
419430400 bytes (419 MB) copied, 13.0829 s, 32.1 MB/s
real 0m13.388s
user 0m0.250s
sys 0m1.208s
--------------------
dd in /cgroup/high:
819200+0 records in
819200+0 records out
419430400 bytes (419 MB) copied, 7.43459 s, 56.4 MB/s
real 0m7.818s
user 0m0.256s
sys 0m1.209s
属于/cgroup/low的进程完成文件读入耗费约13秒,而属于/cgroup/high的进程完成读入耗费约8秒。与优先级较低,即weight设置值较小的分组相比,优先级较高,即属于weight设置值较大的分组(/cgroup/high)的进程可以优先执行I/O操作。
Block I/O控制器提供的特殊文件
除了blkio.weight以外,Block I/O控制器还提供了一些其他的特殊文件。文件列表如表2-7所示。只读属性的特殊文件是用来获取统计信息的文件,多数是根据各设备、I/O的类型(read/write、sync/async)另起一行的。
表2-7 Block I/O控制器的设置用特殊文件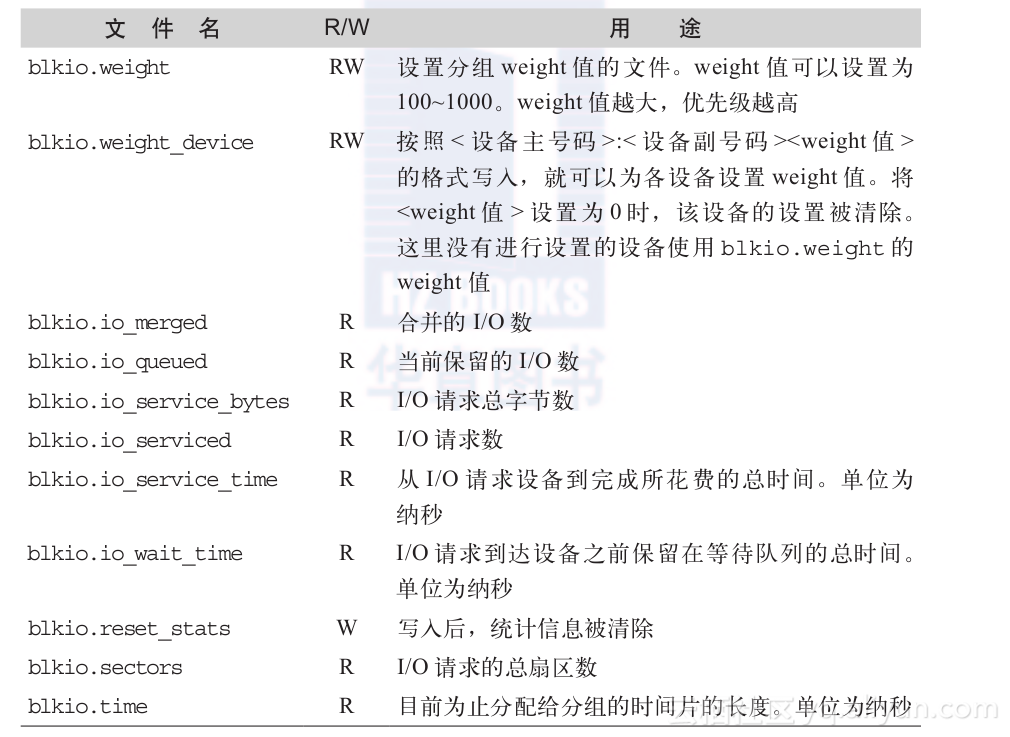
小贴士:I/O的合并,是指将应用程序发出的多个I/O请求合并为1个。把相邻扇区的I/O整理到一起后,仅需一次DMA就可以完成I/O,因此可以提高I/O处理的效率。
另外,在启用内核选项CONFIG_DEBUG_BLK_CGROUP进行编译的内核中,还有为用户提供调试用信息的文件,这里不作说明。
关于Block I/O控制器的CFQ设置用虚拟文件
/sys/block//queue/iosched中有CFQ的设置用虚拟文件,表2-8所示文件会对Block I/O控制器的运行产生影响。
表2-8 关于Block I/O控制器的sysfs的CFQ设置文件
限制事项
由于Block I/O控制器仍是比较新的功能,因此在使用上还有一些限制。接下来列出了到Linux内核版本2.6.35为止存在的限制事项。
不支持非同步I/O
需要各分组进行优先级控制的,当前仅为同步I/O,即初次读入和Direct I/O的读写。普通的写入是经过页面缓存的非同步I/O,因此不属于优先级控制的对象,都被看做根分组发出的I/O。
不支持分组层次化
把分组的层次限制为仅一层,因此无法创建从根分组开始有两层次以上的分组。用cgroup文件系统的目录层次可以显示如下。
/cgroup # 根分组
/cgroup/gr1 # 第一层:可以创建
/cgroup/gr1/gr2 # 第二层:不可以创建
根分组与子分组作同等处理
根分组不作为其他子分组的上级分组,而是作为同等分组进行处理。当根分组内存在拥有实时I/O优先权的进程时,这个影响比较明显。根分组会被其他子分组抢占,因此即使是实时进程,也不能占用I/O带宽。
Block I/O控制器的结构与注意事项
为了更准确地理解Block I/O控制器的运行,下面介绍其内部结构及其使用上的注意事项。
Block I/O控制器对各分组的I/O请求分配时间片。仅许可各分组在这个时间片内执行I/O操作。分组的weight值越大,时间片的长度越长;weight值越小,时间片的长度越短。通过这种方式来指定分组间的I/O操作的优先级。
这里需要注意的是,优先级不是通过I/O带宽(字节/秒,bps),而是通过时间片的长度来指定的。因此,两个分组在I/O完成所需时间差距极大的模式下执行I/O时,具体来说,就是一个依次读入,另一个随机读入的情况下,各分组的I/O带宽就会与weight值的设置迥然不同。
另外,还需要注意的是,Block I/O控制器只有在针对设备的I/O发生竞争时,才会根据优先级对I/O进行控制。在I/O不发生竞争的情况下,即使是优先级较低的分组,Block I/O控制器也不会禁止I/O的执行。也就是说,如果优先级较高的分组没有对某个设备发出I/O请求,那么即使是优先级较低的分组,也可以使用该设备的全部带宽。这里所说的设备是指实际的物理块设备。dm(device-mapper)等可以为应用程序提供逻辑性块设备,但是Block I/O控制器与逻辑块设备完全无关,只在向物理设备执行I/O时进行控制。当多个分组同时对同一逻辑设备发出I/O请求时,根据这些I/O请求所针对的物理设备不同,实际的I/O有可能竞争,有可能不竞争。这时,想要预测出哪个I/O会优先进行,就必须正确把握逻辑设备和物理设备的对应关系。
小结
Block I/O控制器是正在开发的新功能。还存在前面所述的一些限制,因此更需要大家通过实际体验来发现存在问题或尚有不足的功能,反馈给开发者或者自己大胆地制作出来,才能够将其不断地完善。
参考文献
关于Cgroup请参考Hack #7。
Documentation/cgroups/blkio-controller.txt(内核源文档)
—Munehiro IKEDA
《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #13 使用Block I/O控制器设置I/O优先级的更多相关文章
- 《Linux内核精髓:精通Linux内核必会的75个绝技》目录
1章 内核入门HACK #1 如何获取Linux内核HACK #2 如何编译Linux内核HACK #3 如何编写内核模块HACK #4 如何使用GitHACK #5 使用checkpatch.pl检 ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #1 如何获取Linux内核
HACK #1 如何获取Linux内核 本节介绍获取Linux内核源代码的各种方法.“获取内核”这个说法看似简单,其实Linux内核有很多种衍生版本.要找出自己想要的源代码到底是哪一个,必须首先理解各 ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #15 ramzswap
HACK #15 ramzswap 本节介绍将一部分内存作为交换设备使用的ramzswap.ramzswap是将一部分内存空间作为交换设备使用的基于RAM的块设备.对要换出(swapout)的页面进行 ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #14 虚拟存储子系统的调整
HACK #14 虚拟存储子系统的调整 本节介绍如何使用/proc进行虚拟存储子系统的调整.虚拟空间存储方式在Linux上向应用程序分配内存时,是通过以页面为单位的虚拟存储方式进行的.采用虚拟存储方式 ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #3 如何编写内核模块
HACK #3 如何编写内核模块 本节将介绍向Linux内核中动态添加功能的结构—内核模块的编写方法.内核模块Linux内核是单内核(monolithic kernel),也就是所有的内核功能都集成在 ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #21FUSE
HACK #21FUSE 本节将介绍使用用户进程的文件系统框架—FUSE.FUSE概要FUSE(Filesystem in Userspace,用户空间文件系统),是用来生成用户空间的一般进程的框架. ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #20 使用fio进行I/O的基准测试
HACK #20 使用fio进行I/O的基准测试 本节介绍使用fio进行模拟各种情况的I/O基准测试的操作方法.I/O的基准测试中有无数需要考虑的因素.是I/O依次访问还是随机访问?是通过read/w ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #17 如何使用ext4
HACK #17 如何使用ext4 本节介绍ext4的编写和挂载方法.开发版ext4的使用方法.ext4是ext3的后续文件系统,从Linux 2.6.19开始使用.现在主要的发布版中多数都是采用ex ...
- 《Linux内核精髓:精通Linux内核必会的75个绝技》一HACK #16 OOM Killer的运行与结构
HACK #16 OOM Killer的运行与结构(1) 本节介绍OOM Killer的运行与结构. Linux中的Out Of Memory(OOM) Killer功能作为确保内存的最终手段,可以在 ...
随机推荐
- python 随机选择字符串中的一个字符
import random print(random.choice('abcdefghijklm'))
- XML_CPP_资料_libXml2_01
ZC: 看了一些 C/C++的XML文章,也看了一些 Qt的 QXmlQuery/QXmlSimpleReader/QXmlStreamReader/QXmlStreamWriter 的文章.总体感觉 ...
- CentOS6.4x86EngCustomize120g__20160307.rar
安装的镜像包: CentOS-6.4-i386-bin-DVD1to2(CentOS-6.4-i386-bin-DVD1.iso / CentOS-6.4-i386-bin-DVD2.iso) 1. ...
- [java]java String.split()函数的用法分析
转自:http://swiftlet.net/archives/709 一.在java.lang包中有String.split()方法的原型是: public String[] split(Strin ...
- REST服务使用@RestController实例,输出xml/json
REST服务使用@RestController实例,输出xml/json 需要用到的服务注解 org.springframework.web.bind.annotation.RestControlle ...
- Python——列表表达式
https://www.cnblogs.com/xuyuanyuan123/p/6718403.html
- echarta3 北京,上海地图
1.首先你得到echarts官网下载js,建议下载完整代码,这样你就很容易根据我的路径找到beijing.js 2.把echarts.js和beijingi.js根据你的路径引对,然后就可以copy我 ...
- 动态创建OATipBean
动态创建OATipBean. 动态创建的OATipBean无法直接设置提示内容,需要添加一个静态文本. 参考User Guide示例如下. If you need to create a tip pr ...
- JQuery鼠标移到小图显示大图效果的方法
JQuery鼠标移到小图显示大图效果的方法 本文实例讲述了JQuery鼠标移到小图显示大图效果的方法.分享给大家供大家参考.具体分析如下: 这里的显示大图功能类似上一篇<JQuery实现超链接鼠 ...
- Beta阶段贡献分配规则
作业要求[https://edu.cnblogs.com/campus/nenu/2018fall/homework/2382] 在新成员加入后,我们经过讨论,决定沿用alpha阶段贡献分分配规则. ...