词法分析器Lexer
词法分析
In computer science, lexical analysis, lexing or tokenization is the process of converting a sequence of characters (such as in a computer program or web page) into a sequence of tokens (strings with an assigned and thus identified meaning).
在计算机科学中,词法分析,lexing或标记化是将一系列字符(例如在计算机程序或网页中)转换成一系列标记(具有指定且因此标识的含义的字符串)的过程。
编码目标
给定一个源代码文件,能够将其转化为词法记号流。
比如规定int的词法记号为30,输出就是<30, int>;数字的词法记号为11,则输入123,输出为<11, 123>。
约定
把程序中的词法单元分为四类:标识符(分为关键字和一般标识符)、数字、特殊字符、空白(空格、Tab、回车换行等)
程序流程图
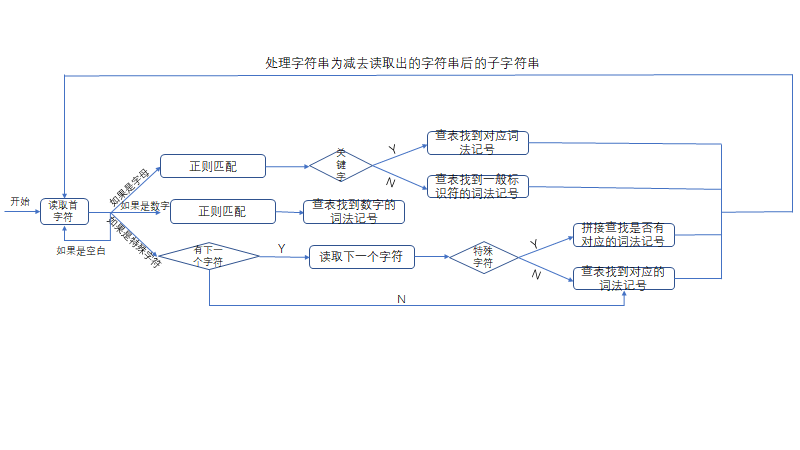
对于运算符等符号,这里只考虑两个字符的组合情况,不考虑三个字符组成的运算符。之所以要在读到特殊字符之后在往后读一个字符是因为有可能在表中存在类似>=和>的运算符,要保证最长字符匹配。
关键代码
首字符类型判断
public static String getCharType(String str) {
String regex_Letter = "[a-zA-Z]";
String regex_Number = "[0-9]";
String regex_Blank = "\\s";
Pattern pattern;
pattern = Pattern.compile(regex_Letter);
Matcher matcher = pattern.matcher(str);
if (matcher.find())
return "LETTER";
pattern = Pattern.compile(regex_Number);
matcher = pattern.matcher(str);
if (matcher.find())
return "NUMBER";
pattern = Pattern.compile(regex_Blank);
matcher = pattern.matcher(str);
if (matcher.find())
return "BLANK";
return "SPECIAL";
}
如果首字符为字母
case "LETTER":
pattern = Pattern.compile(regex_ID);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
if (LexicalToken.isKeyWord(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
} else {
int token = lextok.getToken("ID");
System.out.printf("<%d,%s> ", token, result);
}
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是数字
case "NUMBER":
pattern = Pattern.compile(regex_NUM);
matcher = pattern.matcher(srcCode);
if (matcher.lookingAt()) {
String result = matcher.group();
int token = lextok.getToken("NUM");
System.out.printf("<%d,%s> ", token, result);
}
srcCode = srcCode.substring(matcher.end());
break;
如果首字符是空格
case "BLANK":
srcCode = srcCode.substring(1);
break;
如果首字符是特殊符号
case "SPECIAL":
if (srcCode.length() > 1) {
String secondChar = srcCode.substring(1, 2);
String result;
LinkedHashMap tokenMap = lextok.getLexicalTokenMap();
Set set = tokenMap.keySet();
result = firstChar + secondChar;
if (getCharType(secondChar).equals("SPECIAL") && set.contains(result)) {
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(2);
}else {
result = firstChar;
int token = lextok.getToken(result);
System.out.printf("<%d,%s> ", token, result);
srcCode = srcCode.substring(1);
}
} else { // 字符串中只有一个字符时
int token = lextok.getToken(srcCode);
System.out.printf("<%d,%s> ", token, srcCode);
srcCode = srcCode.substring(1);
}
break;
源码地址:https://github.com/Liyzy/Lexer
开发环境:IJ idea 2018.2
词法分析器Lexer的更多相关文章
- atitit.词法分析原理 词法分析器 (Lexer)
atitit.词法分析原理 词法分析器 (Lexer) 1. 词法分析(英语:lexical analysis)1 2. :实现词法分析程序的常用途径:自动生成,手工生成.[1] 2 2.1. 词法分 ...
- 词法分析器Antlr
一.我们都知道编程语言在执行之前需要先进行编译,这样就可以把代码转换成机器识别的语言,这个过程就是编译. 那么它是怎么编译的呢? Java在JVM虚拟机中进行编译,javascript在Js引擎中编译 ...
- 02.从0实现一个JVM语言之词法分析器-Lexer-03月02日更新
从0实现JVM语言之词法分析器-Lexer 本次有较大幅度更新, 老读者如果对前面的一些bug, 错误有疑问可以复盘或者留言. 源码github仓库, 如果这个系列文章对你有帮助, 希望获得你的一个s ...
- B-index、bitmap-index、text-index使用场景详解
索引的种类:B-tree索引.Bitmap索引.TEXT index1. B-tree索引介绍: B-tree 是一种常见的数据结构,也称多路搜索树,并不是二叉树.B-tree 结构可以显著减少定位 ...
- oracle全文检索
全文检索 oracle对使用几十万以上的数据进行like模糊查询速度极差,包括 like 'AAA%' ,like '%AAA',like '%AAA%',like '%A%A%'的那些模糊查询.网上 ...
- Lex和Yacc入门
Lex和Yacc入门 标签: lexyacc 2013-07-21 23:02 584人阅读 评论(0) 收藏 举报 分类: Linux(132) 原文地址:http://coanor.blog ...
- Lex+YACC详解
1. 简介 只要你在Unix环境中写过程序,你必定会邂逅神秘的Lex&YACC,就如GNU/Linux用户所熟知的Flex&Bison,这里的Flex就是由Vern Paxon实现的一 ...
- oracle的全文索引
1.查看oracle的字符集 SQL> select userenv('language') from dual; USERENV('LANGUAGE') ------------------- ...
- Oracle建立全文索引详解
Oracle建立全文索引详解1.全文检索和普通检索的区别 不使用Oracle text功能,当然也有很多方法可以在Oracle数据库中搜索文本,比如INSTR函数和LIKE操作: SELECT *FR ...
随机推荐
- spring boot快速入门 3: controller的使用
模版引擎的使用: 第一步:在POM文件添加配置 <!-- 模版引擎 --> <dependency> <groupId>org.springframework.bo ...
- 【JAVA-WEB】在url上追加sessionid
HttpSession session = request.getSession(); url = url+";jsessionid="+session.getId();
- 高性能队列Disruptor的使用
一.什么是 Disruptor 从功能上来看,Disruptor 是实现了"队列"的功能,而且是一个有界队列.那么它的应用场景自然就是"生产者-消费者"模型的应 ...
- ubuntu编译安装protobuf
测试环境:Ubuntu 16.04 LTS 到protobuf的release页面 下载源码:https://github.com/protocolbuffers/protobuf/releases/ ...
- memcached 学习笔记 5
memcached installed on linux 使用的操作系统是centos6.5 (有桌面) 1 上传libebent和memcache到/usr/local/src [root@jt ...
- 203_Removed-Linked-List-Elements
目录 203_Removed-Linked-List-Elements Description Solution Java solution 1 Java solution 2 Python solu ...
- JAVA泛型——基本使用
Java1.5版本推出了泛型,虽然这层语法糖给开发人员带来了代码复用性方面的提升,但是这不过是编译器所做的一层语法糖,在真正生成的字节码中,这类信息却被擦除了.笔者发现很多几年开发经验的程序员,依然不 ...
- 04-Tomcat体系结构与插件配置
一.发布程序详解 Context docBase:web应用的文件路径 path:URL入口 reloadable:字节码变化服务器是否重新加载web应用 二.tomcat服务器体系结构 1.Serv ...
- linux的目录结构及文件基本操作
1. linux的文件组织目录结构 linux的目录与window的区别 win以存储介质为主,主要以盘符及分区实现文件 管理,再下面才是目录. linux以树形目录结构的形式来构造整个系统,每一个目 ...
- Java基础-基于《Thinking In Java》
摘要 本文是对一些java基础知识的整理,把之前印象笔记里面的全部慢慢搬到这个blog来 为了方便就按照<Thinking In Java>的目录来编辑. 这里面的内容均为面试题相关,可能 ...