Hadoop入门 运行环境搭建
模板虚拟机
1 硬件
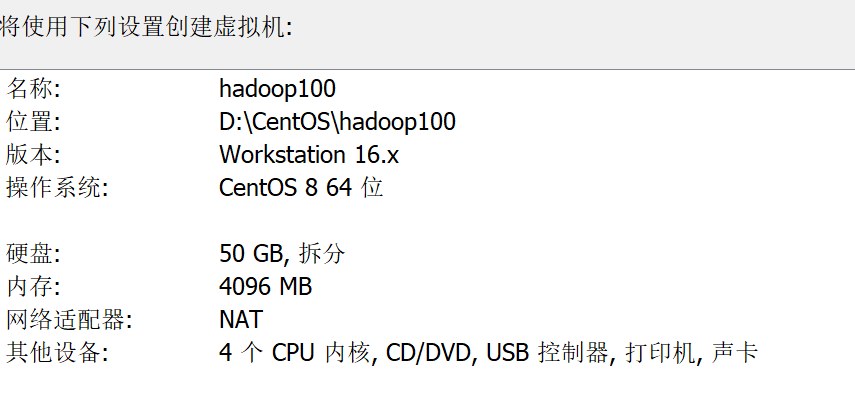
说明:
1.hadoop100.vmdk生成的物理磁盘文件,为了方便管理放在hadoop100文件夹下。
2 操作系统
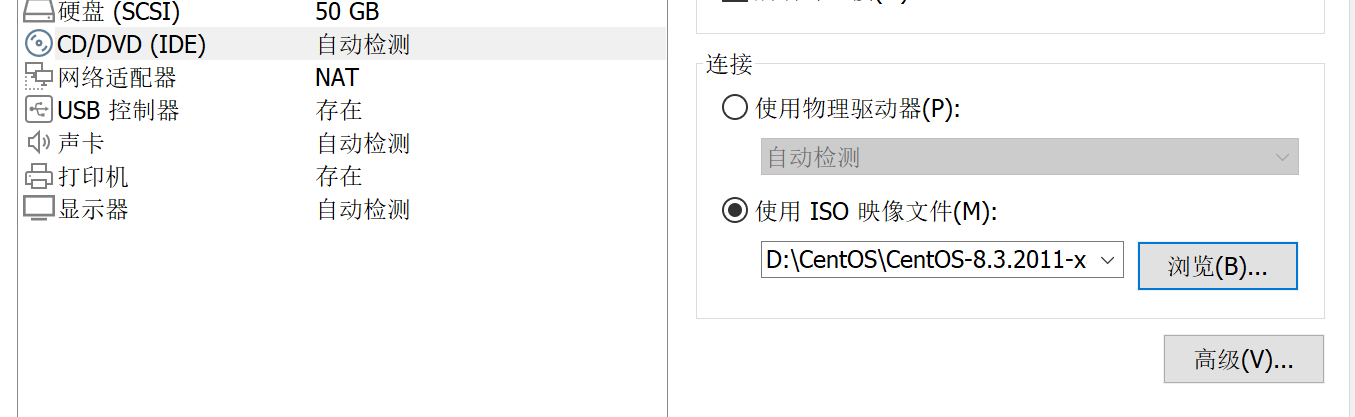
磁盘分区:选择自定义-点击完成-进行分区
/boot 文件系统选ext4
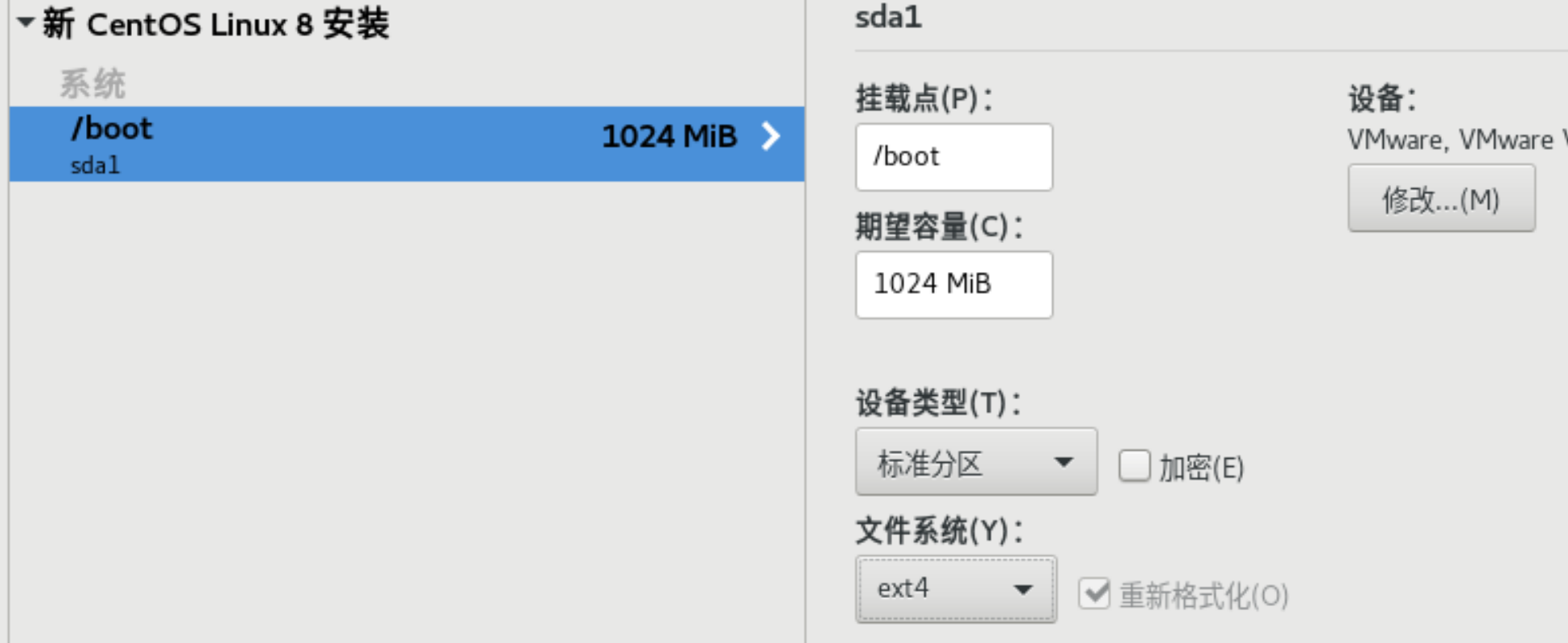
swap 当内存不够时由此区域冒充硬盘
网络和主机名
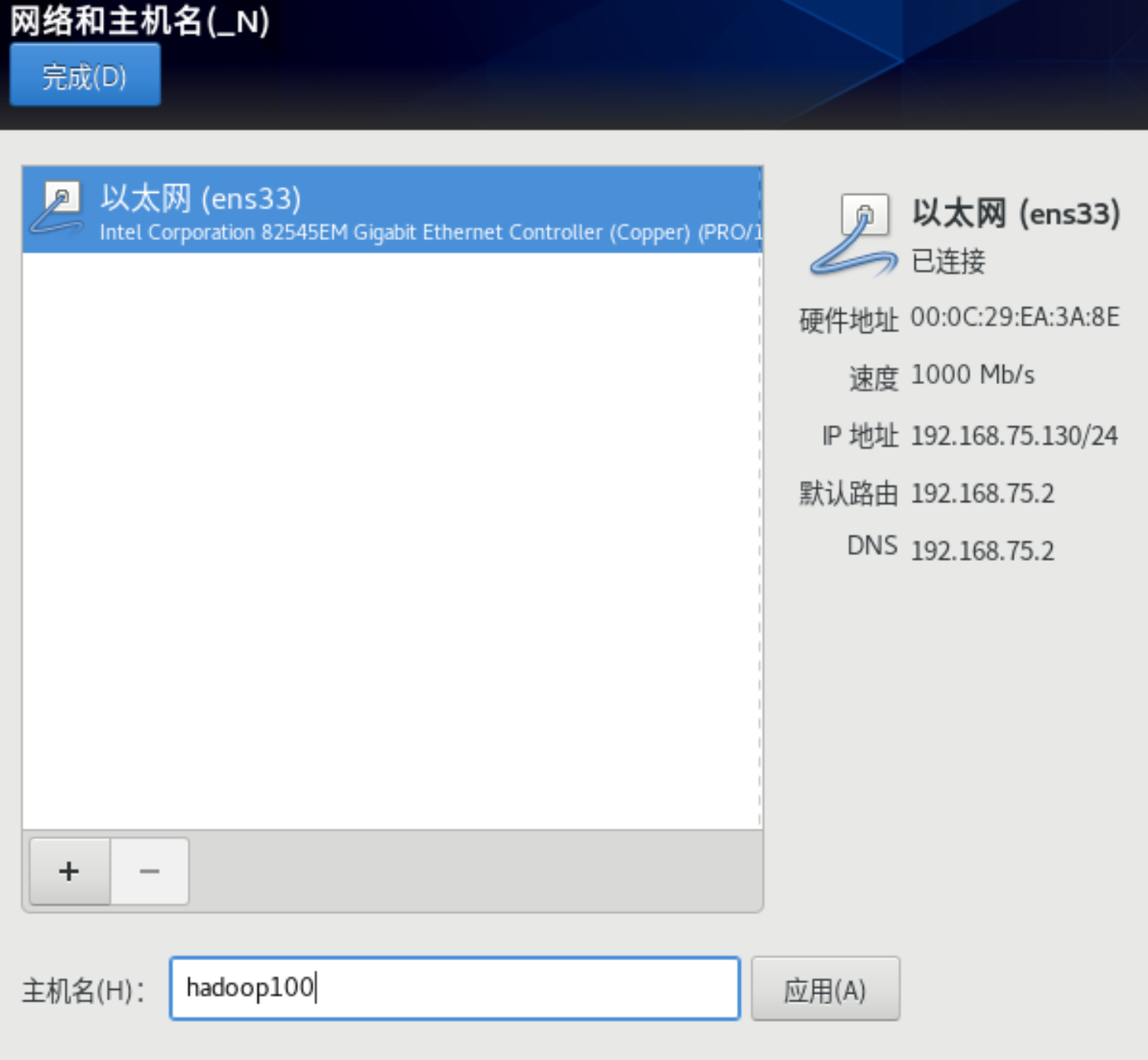
3 IP地址和主机名称
需要进行三个地方的ip地址配置:Hadoop100 服务器、vm、windows服务器
修改的目的:宿主机windows和虚拟机linux能够进行网路连接,同时虚拟机linux可以通过宿主机window进入互联网
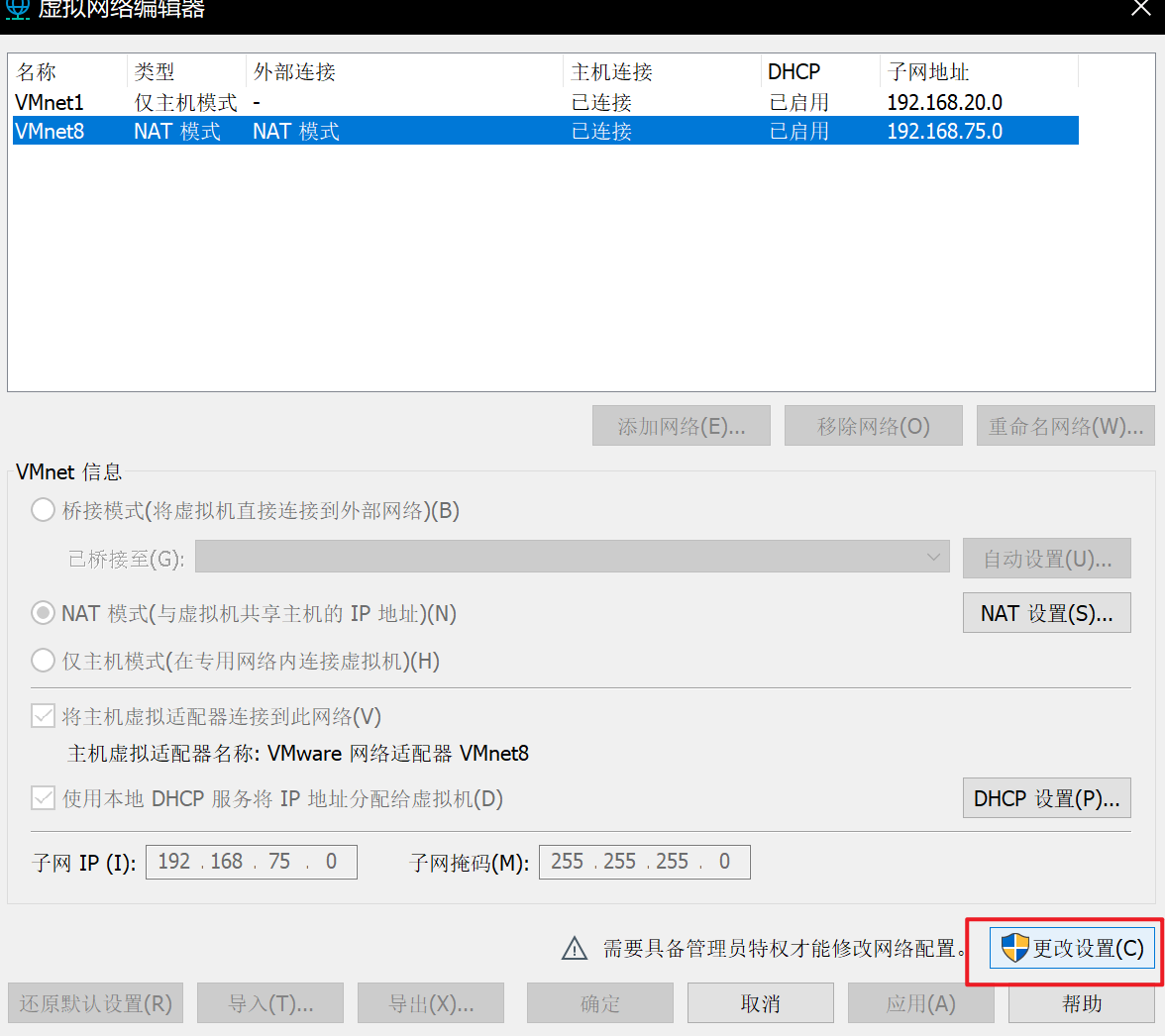
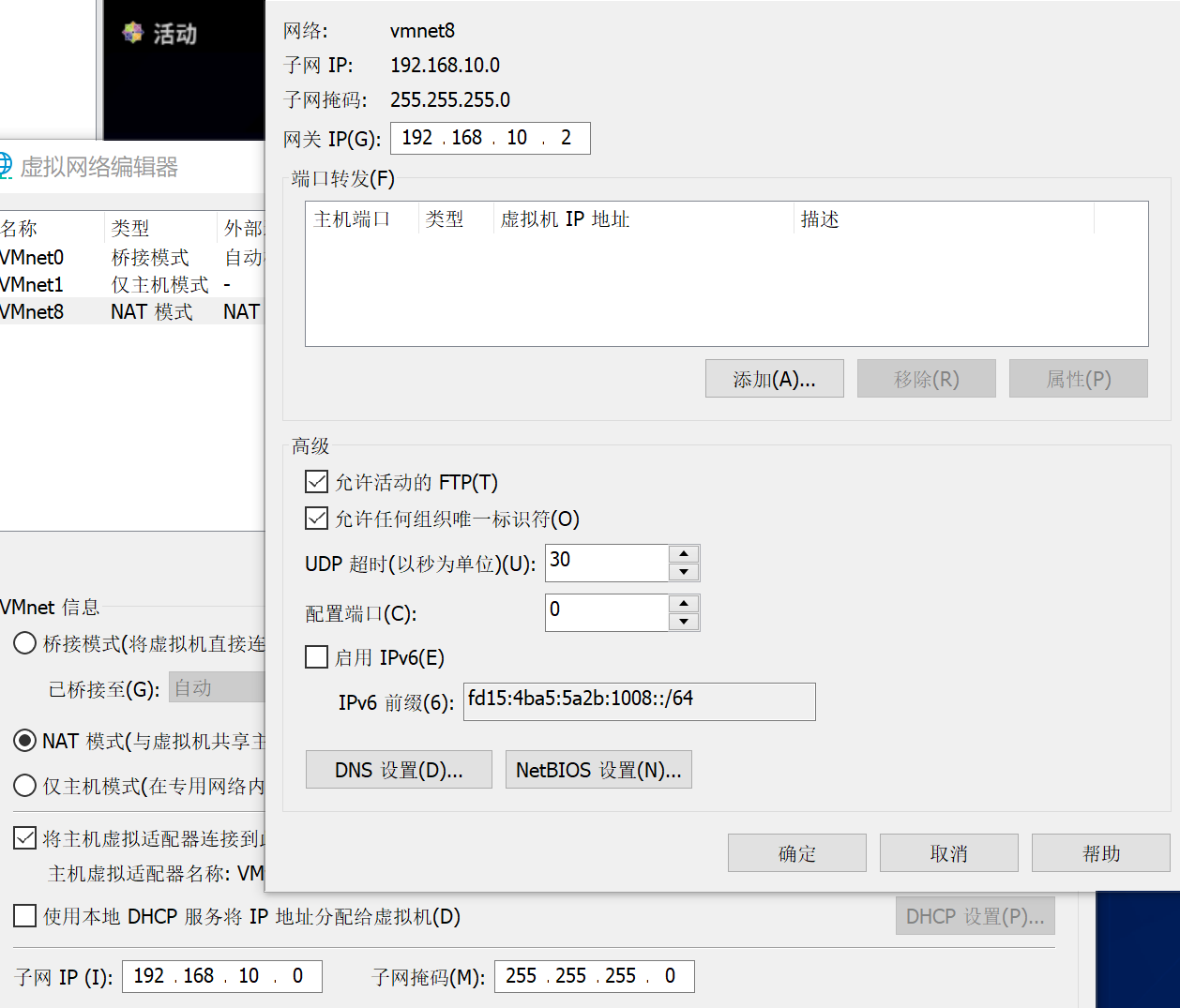
vm
子网IP192.168.10.0 网关IP192.168.10.2
编辑器 - 虚拟网络编辑器
虚拟网卡网关需要和真实网卡网关一致
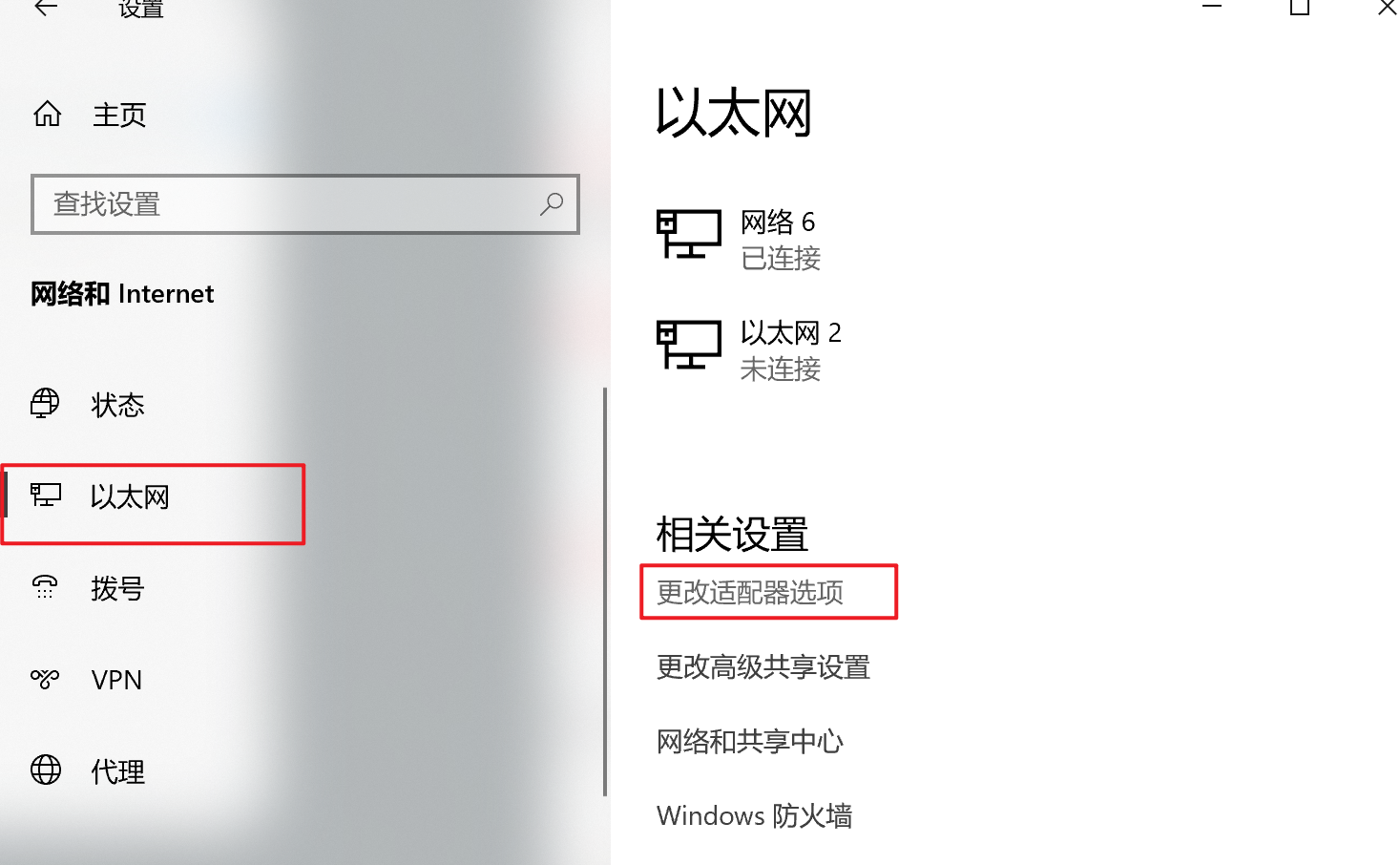
windows10
IP地址192.168.10.1
修改默认网关192.168.10.2,首选DNS服务器192.168.10.2
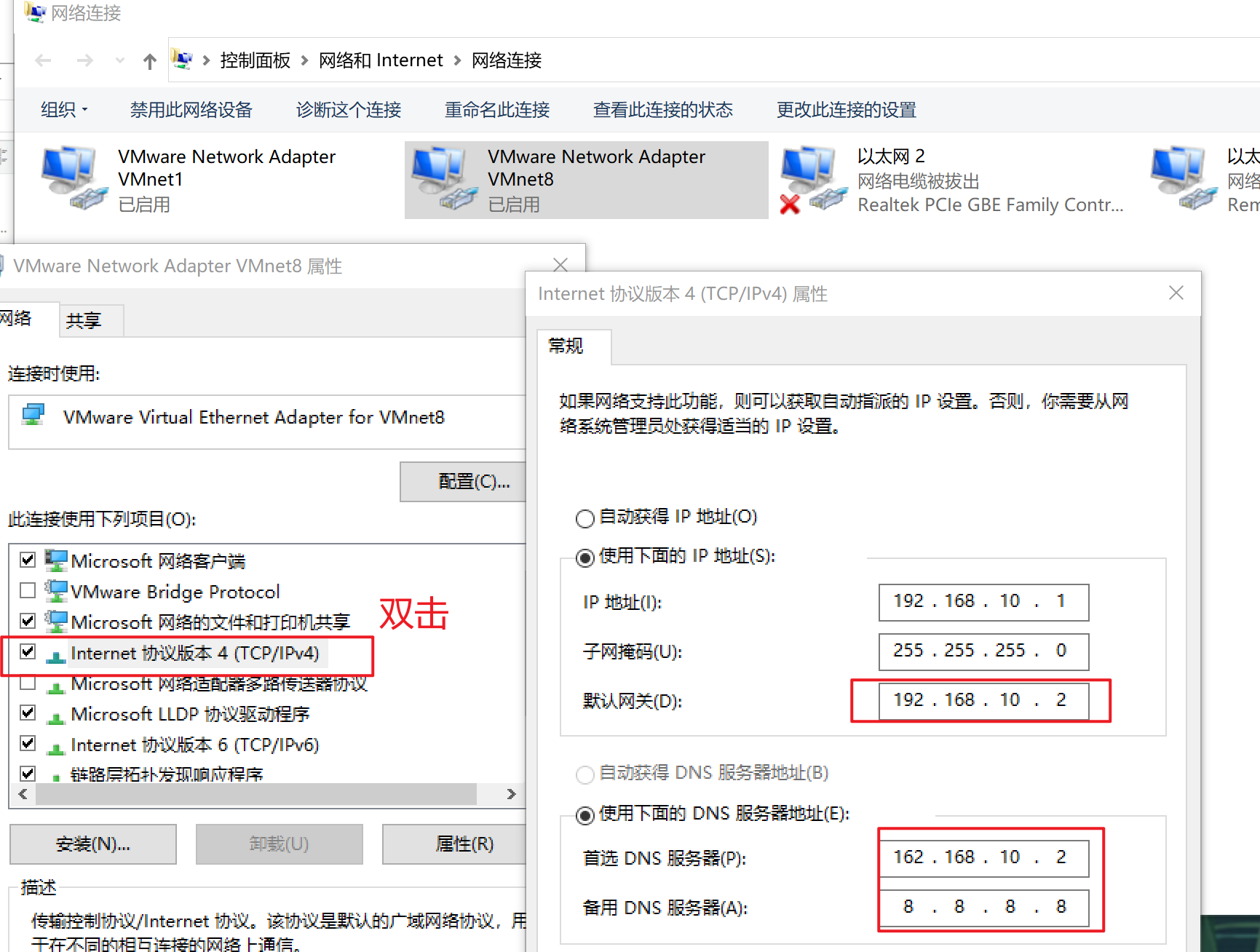
Hadoop100服务器
配置网卡
配置静态IP地址192.168.10.100,默认网关192.168.10.2,DNS192.168.10.2
作用:因为服务器的ip总是不变的,
命令:vim /etc/sysconfig/network-scripts/ifcfg-ens33
# 1 按esc切换模式 ins插入
:wq # 输入:wq退出文件
# 2 配置IP地址
# IP地址的配置方法[static(静态分配)|none(不使用协议)|bootp(bootp协议)|dhcp(DHCP协议)]
# 默认是DHCP动态分配的
BOOTPROTO=static
IPADDR=192.168.10.100 # IP设置
GATEWAY=192.168.10.2 # 网关
DNS1=192.168.10.2 #DNS配置成和网关一样的
NETMASK=255.255.255.0
配置主机名及地址映射
作用:修改主机名为一系列有规律的主机名(方便管理),并修改hosts文件添加我们需要的主机名和地址映射(方便节点服务器间通过主机名进行通讯)
修改主机名
vim /etc/hostname
修改主机名为Hadoop100,在安装桌面系统的时候已经修改了,这里就不修改啦
修改主机名和地址映射
vim /etc/hosts
通过主机名通讯时,先会去该机的hosts文件找该主机名的ip,(DNS DomainNameSystem 域名系统的规则一层一层找)
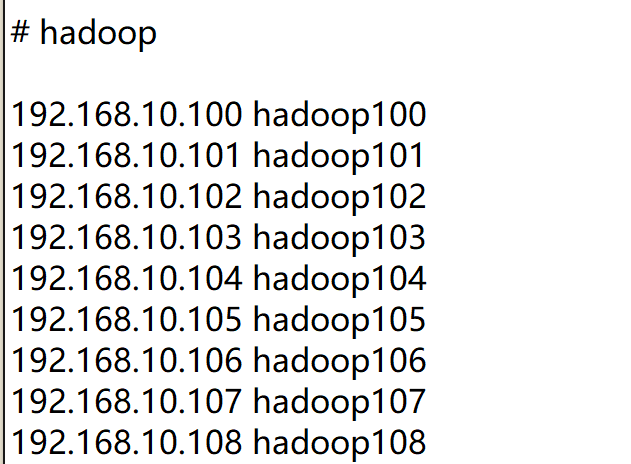
192.168.10.100 hadoop100
192.168.10.101 hadoop101
192.168.10.102 hadoop102
192.168.10.103 hadoop103
192.168.10.104 hadoop104
192.168.10.105 hadoop105
192.168.10.106 hadoop106
192.168.10.107 hadoop107
192.168.10.108 hadoop108
需求:希望windows可以通过主机名来连接centos
补充:如果是linux主机间.则修改的文件是/etc/hosts
修改windows的主机映射文件(hosts文件)
1.进入c/windows/System32/drivers/etc文件
2.复制hosts文件到桌面
3.打开桌面的hosts文件并添加如下内容
192.168.10.100 hadoop100
4.用桌面上的hosts文件覆盖c/windows/System32/drivers/etc路径中的hosts文件
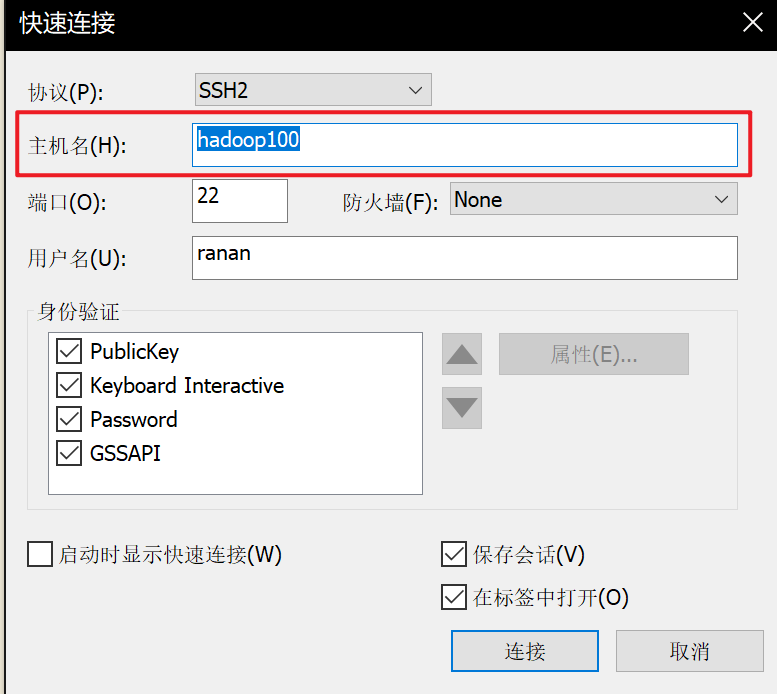
使用主机名连接
检查
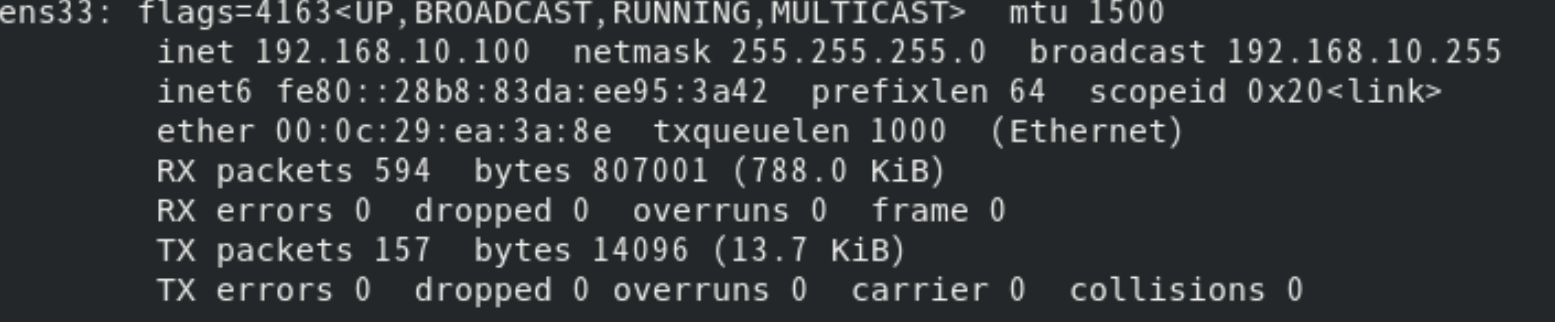
命令:ifconfig
说明:显示或设置网络设备
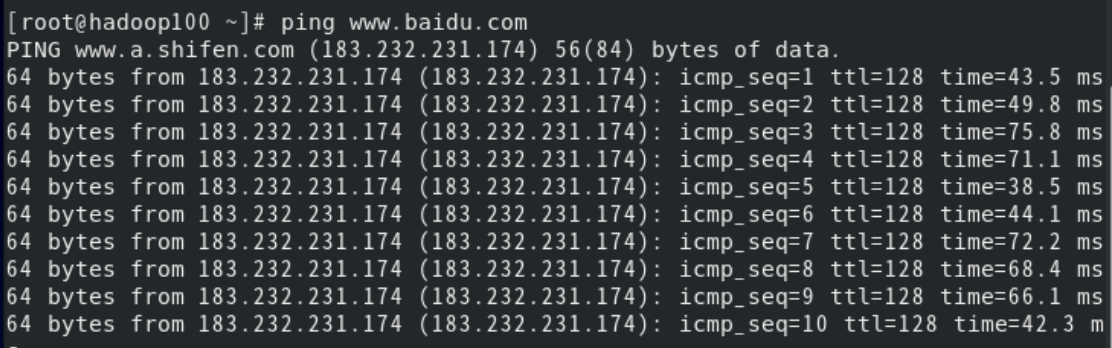
ping 目的主机
说明:ping测试主机之间网络连通信,测试当前服务器是否可以连接目的主机
hostname
说明:查看主机名

远程访问工具
服务器一般放在机房,我们需要远程访问服务器。
使用的是Xshell,连接hadoop100
把windows的文件传进linux里 xftp
Xshell使用卡一卡的,最后选择使用SecureCRT
其他准备
1 epel-release安装
一个软件仓库,大多数rpm包在官方repository中找不到,所以需要额外安装一个软件仓库
yum install -y epel-release
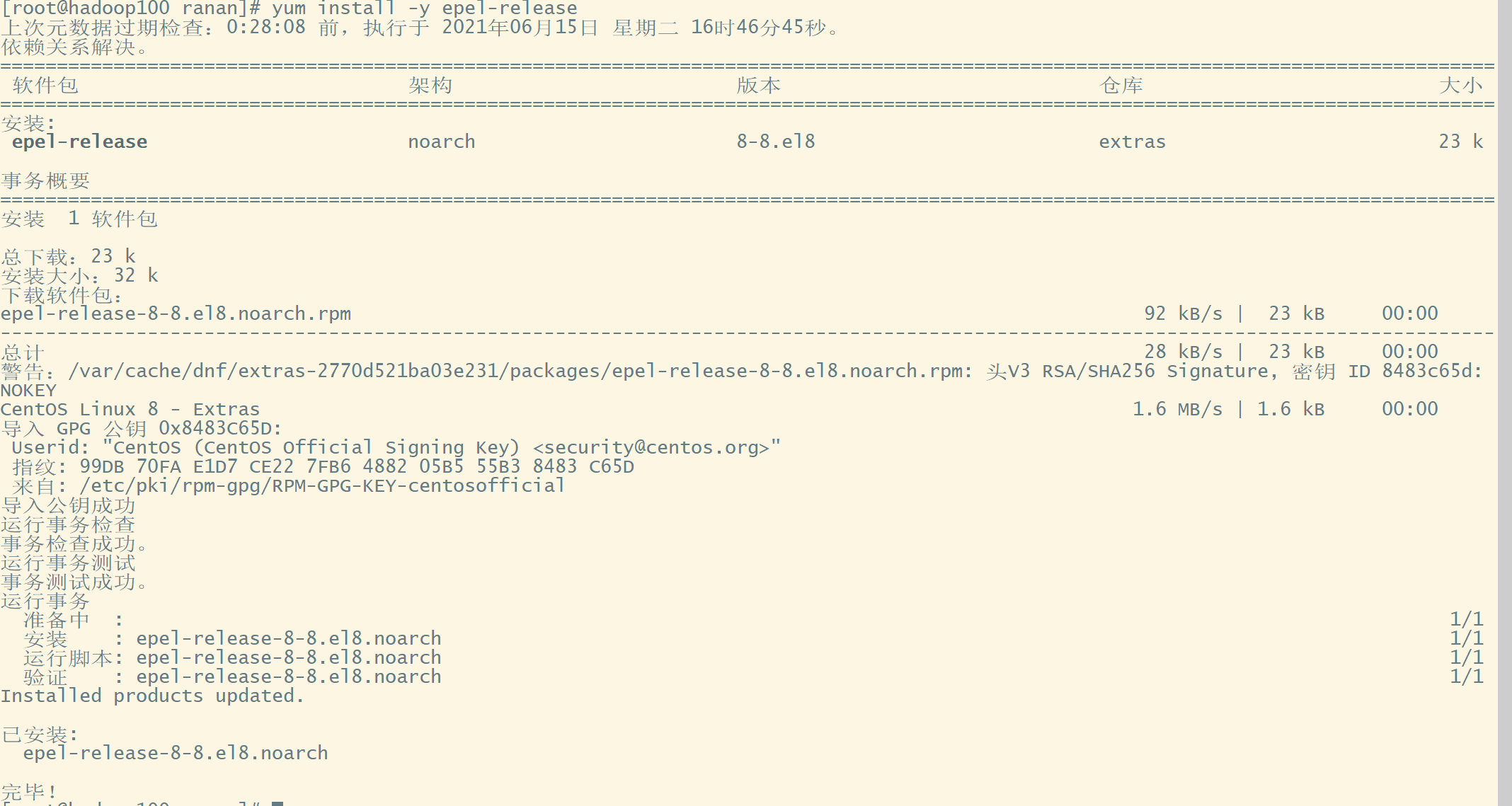
最小系统版还需要安装
- net-tool 工具包集合,包含ifconfig等命令
- vim 编辑器
yum install -y net-tools
yum install -y vim
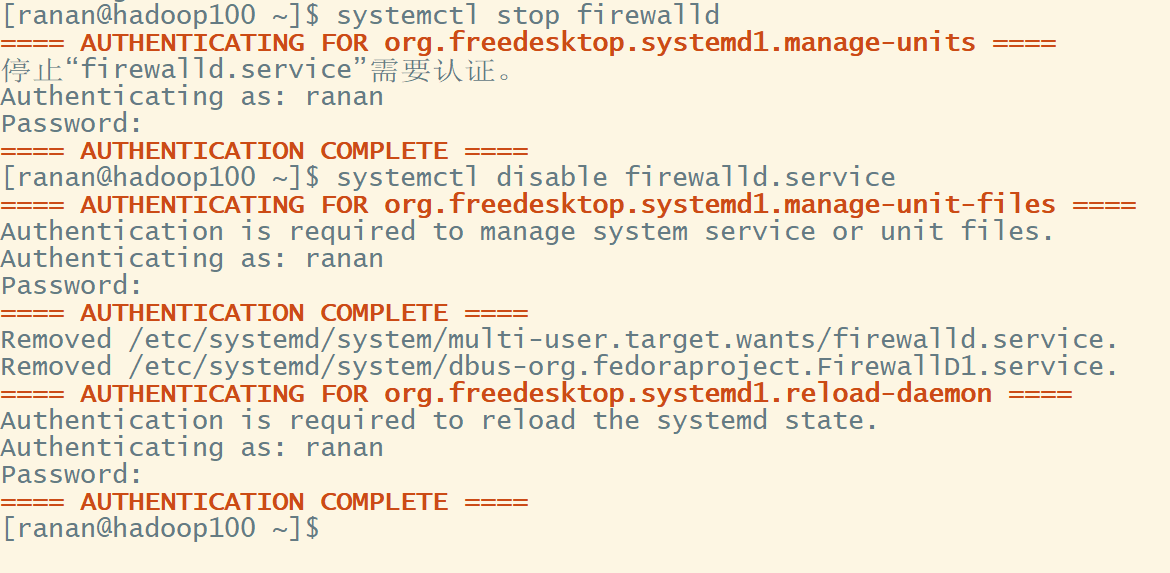
2 关闭防火墙
通常单个服务器的防火墙是关闭的,整体对外会设置非常安全的防火墙
# 关闭防火墙
systemctl stop firewalld
# 关闭开机自启防火墙
systemctl disable firewalld.service
3 用户配置管理员权限
目的:方便后期sudo执行root权限的命令。
root用户进行配置,不然会权限不够
vim /etc/sudoers
# 在%wheel行下添加
ranan ALL=(ALL) NOPASSWD:ALL
这行添加不要直接放在root行下面。因为所有用户都属于wheel组,先执行了这行免密后,执行到wheel时,又会被覆盖回需要密码。
/opt/module 用于存放安装的软件
/opt/software 用于存放安装包
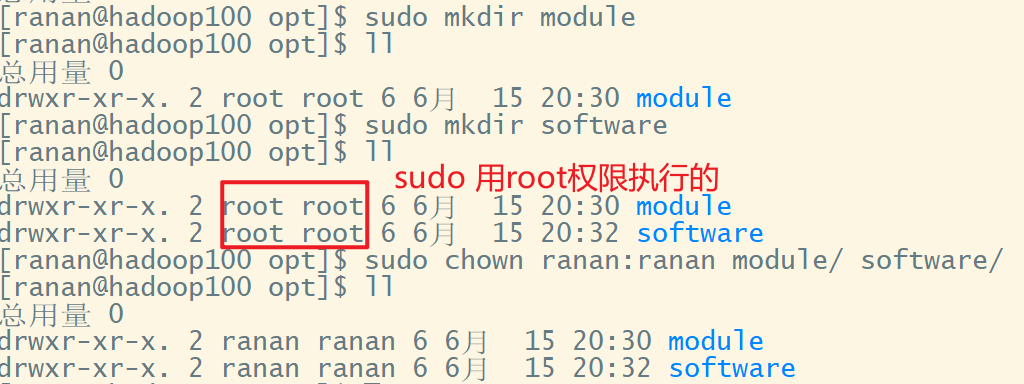
4 卸载虚拟机自带的JDK
桌面版本会默认自动安装JDK
rpm -qa | grep -i java | xargs -nl rpm -e --nodeps
rpm -qa:查看所安装的所有rpm软件包
grep -i:忽略大小写
xargs -nl:表示每次只传递一个参数
rpm -e --nodeps:强制卸载软件
rpm -qa | grep -i java执行之后发现查不出东西,我的虚拟机没有安装
最后reboot重启
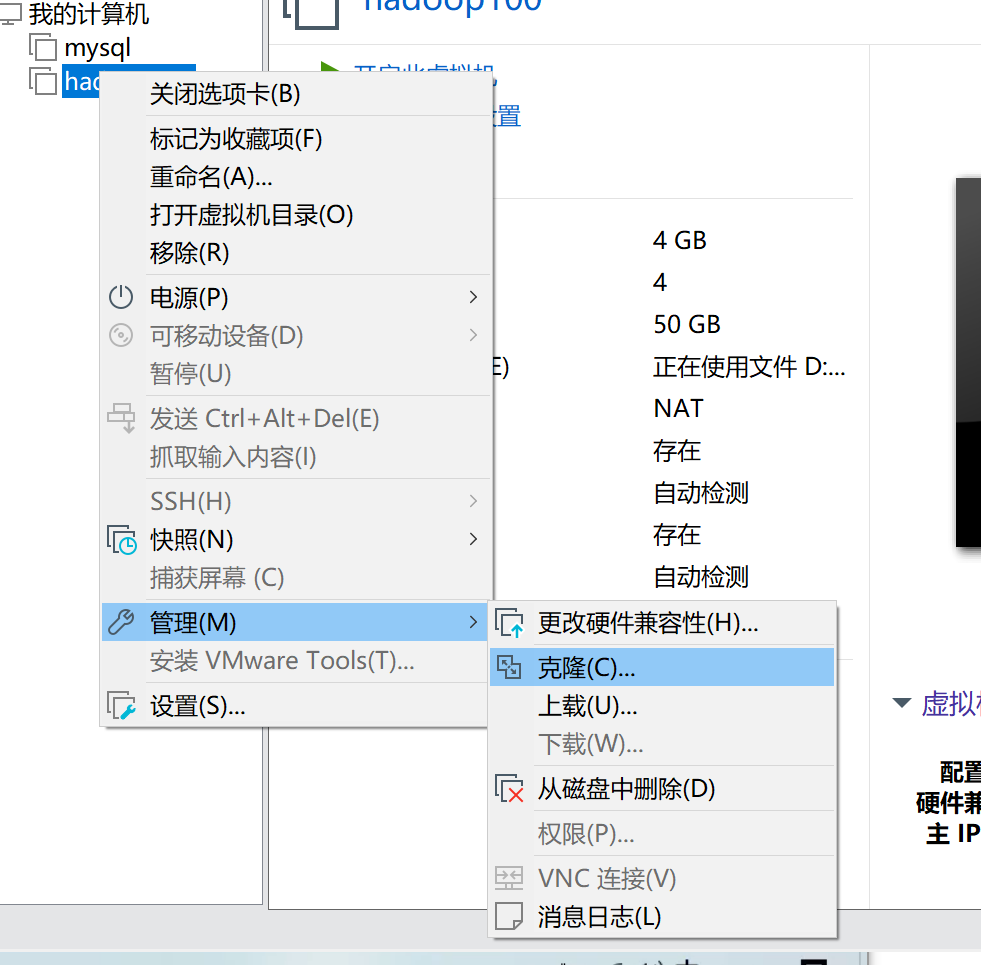
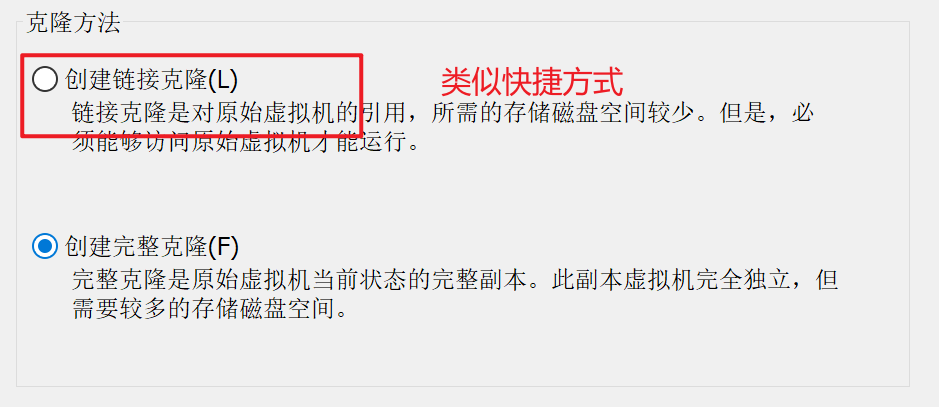
克隆虚拟机
利用模板及hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
克隆
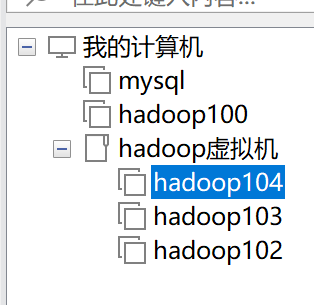
修改主机名/ip
以102为例子
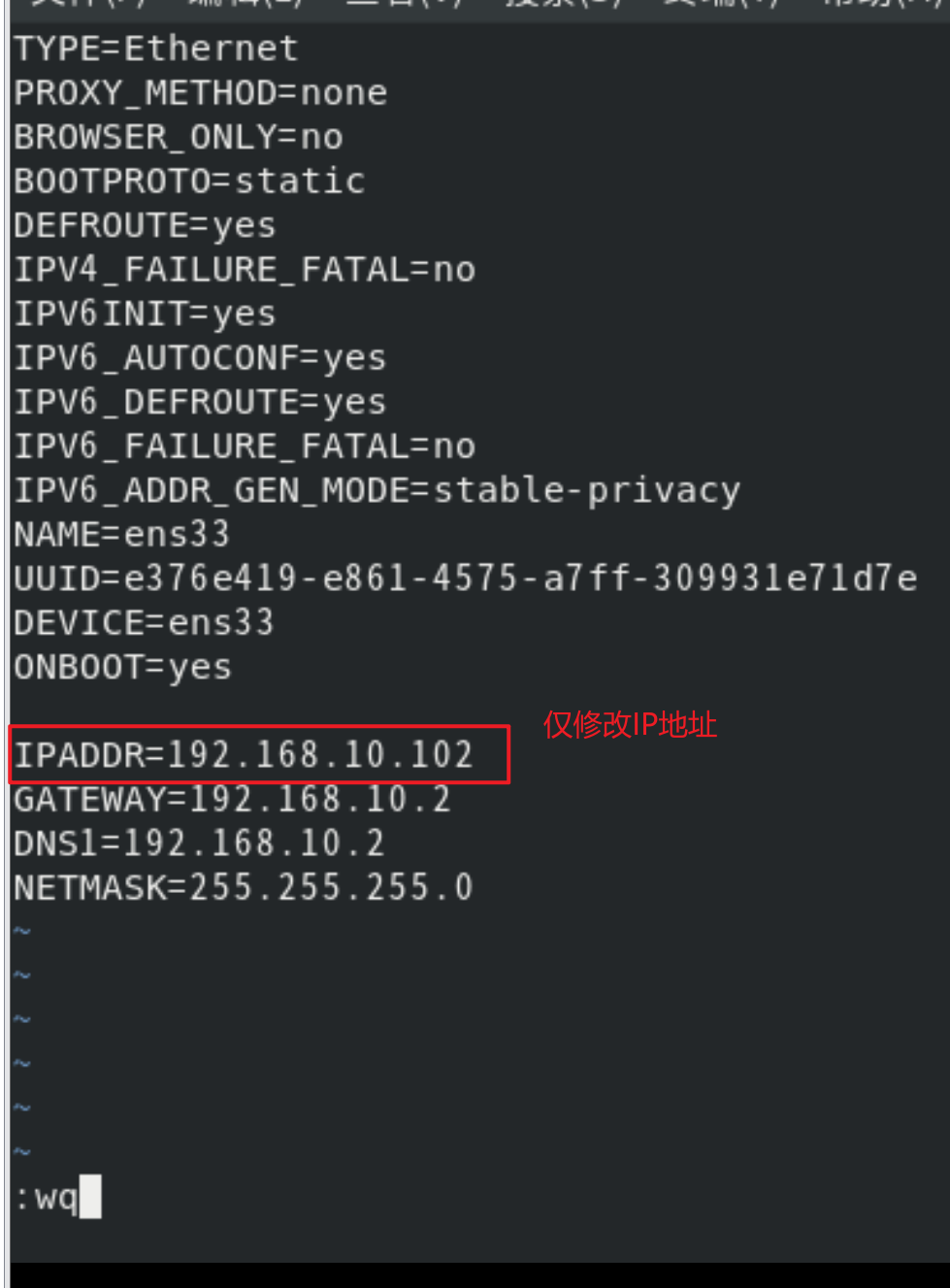
修改IP地址
配置静态IP地址192.168.10.102
命令:vim /etc/sysconfig/network-scripts/ifcfg-ens33
修改主机名
命令:vim /etc/hostname
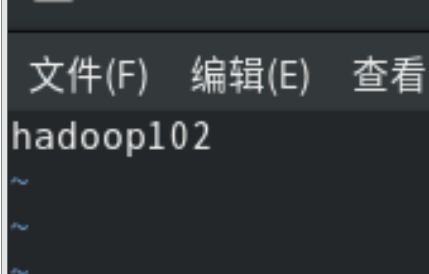
最后reboot
安装jdk
在hadoop102上安装JDK,因为通常103、104上的JDK是从102上拷贝,所以不需要单独在103、104上安装JDK
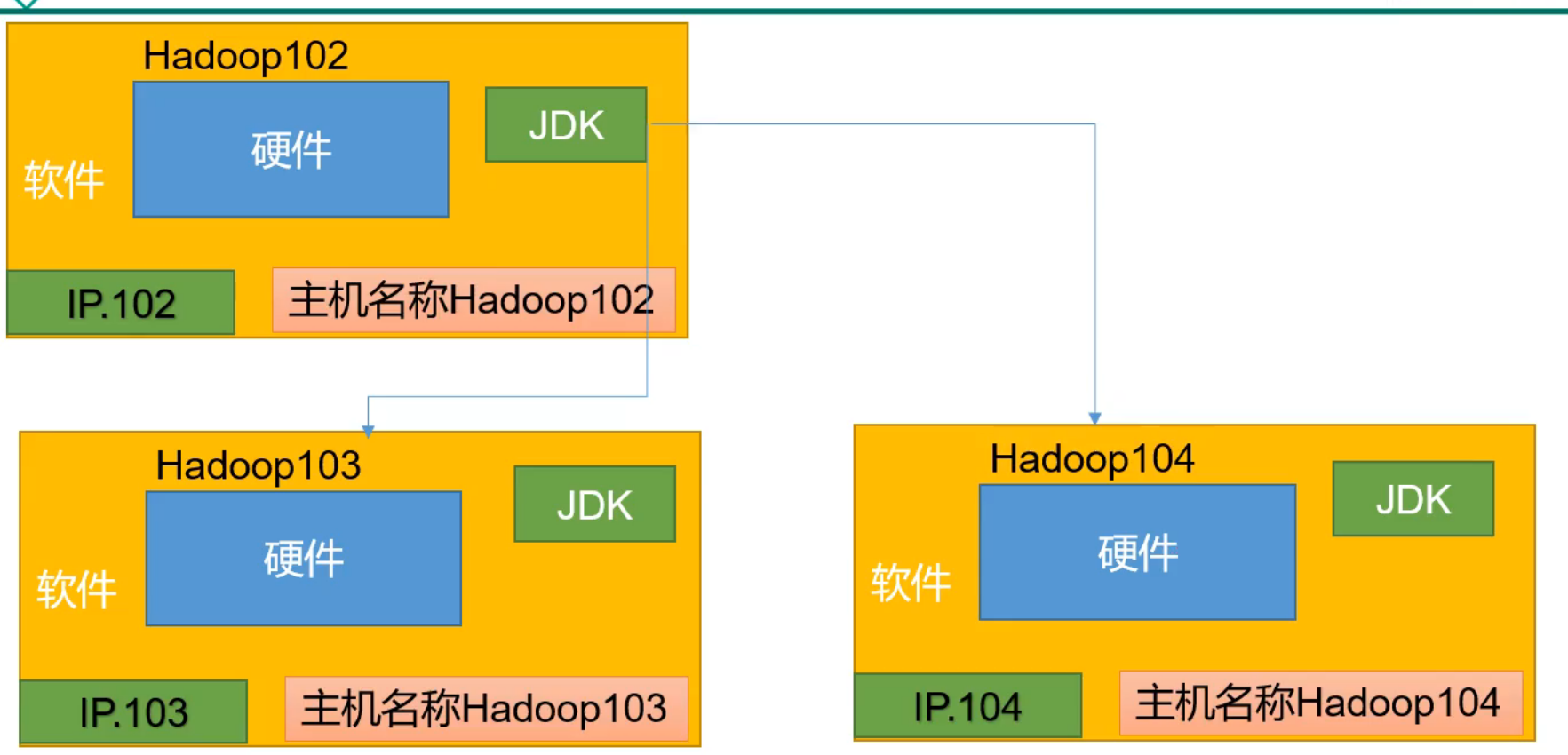
1 上传jdk和hadoop安装包

2 解压安装包进module文件夹下
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
3 配置JDK环境变量
方便使用到JDK的程序能正常调用JDK
1.进入到JDK后,获取JDK路径 /opt/module/jdk1.8.0_212

2.新建环境变量文件
/etc/profile文件,该文件属于root用户,如果其他用户需要使用sudo vim命令对它进行编辑
profile文件

profile.d目录
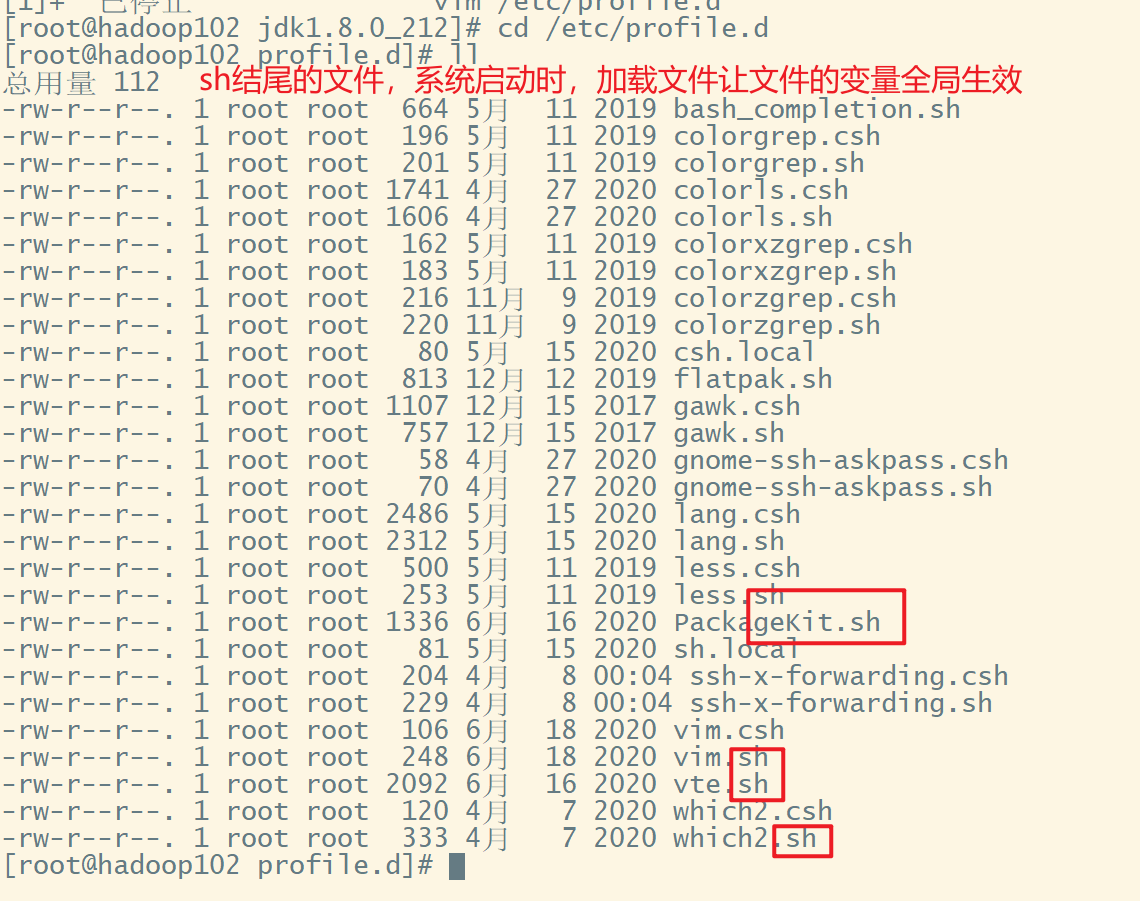
按照这个原理,我们自己新建一个my_env.sh文件

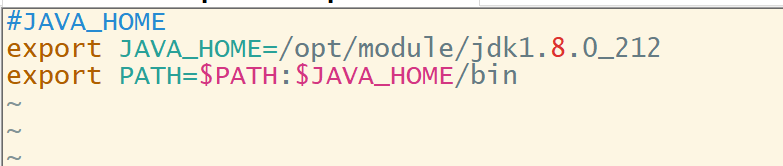
3.修改文件后,需要执行source命令使修改后的文件生效

安装hadoop
1 解压安装包进module文件夹下
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/
2 配置环境变量
文件路径:/opt/module/hadoop-3.1.3
修改配置文件: vim /etc/profile.d/my_env.sh
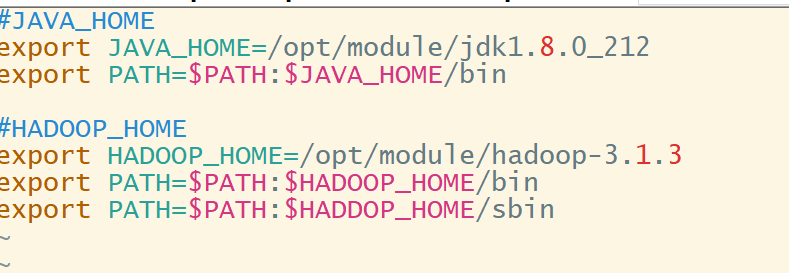
修改后执行source /etc/profile使其生效
Hadoop入门 运行环境搭建的更多相关文章
- Hadoop之运行环境搭建
一.虚拟机环境准备 1.克隆虚拟机 2.修改克隆虚拟机静态IP 3.修改主机名 4.关闭防火墙 5.创建hadoop用户 6.配置hadoop用户具有root权限 7.在/opt 目录下创建文件夹 1 ...
- Hadoop基础教程-运行环境搭建
一.Hadoop是什么 一个分布式系统基础架构,由Apache基金会所开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力进行高速运算和存储. Hadoop实现了一个分布式 ...
- Hadoop系列003-Hadoop运行环境搭建
本人微信公众号,欢迎扫码关注! Hadoop运行环境搭建 1.虚拟机网络模式设置为NAT 2.克隆虚拟机 3.修改为静态ip 4. 修改主机名 5.关闭防火墙 1)查看防火墙开机启动状态 chkcon ...
- Hadoop运行环境搭建
Hadoop运行环境搭建 更改为阿里的Centos7的yum源 #下载wget yum -y install wget #echo 下载阿里云的yum源配置 Centos-7.repo wget - ...
- 【个人笔记】003-PHP基础-01-PHP快速入门-03-PHP环境搭建
003-PHP基础-01-PHP快速入门 03-PHP环境搭建 1.客户端(浏览器) IE FireFox CHROME Opera Safari 2.服务器 是运行网站的基本 是放置程序代码的地方 ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- 《Programming Hive》读书笔记(一)Hadoop和hive环境搭建
<Programming Hive>读书笔记(一)Hadoop和Hive环境搭建 先把主要的技术和工具学好,才干更高效地思考和工作. Chapter 1.Int ...
随机推荐
- NOIP模拟85(多校18)
前言 好像每个题目背景所描述的人都是某部番里的角色,热切好像都挺惨的(情感上的惨). 然后我只知道 T1 的莓,确实挺惨... T1 莓良心 解题思路 首先答案只与 \(w\) 的和有关系,于是问题就 ...
- 转:BeanFactory和FactoryBean的区别
一.BeanFactory简介 BeanFacotry是spring中比较原始的Factory.如XMLBeanFactory就是一种典型的BeanFactory.原始的BeanFactory无法支持 ...
- OKhttp3的使用教程
首先在build.gradle下的dependencies下添加引用. implementation "com.squareup.okhttp3:okhttp:4.9.0" 然后编 ...
- 转载:10G以太网光口与Aurora接口回环实验
10G以太网光口与高速串行接口的使用越来越普遍,本文拟通过一个简单的回环实验,来说明在常见的接口调试中需要注意的事项.各种Xilinx FPGA接口学习的秘诀:Example Design.欢迎探讨. ...
- Python-爬取CVE漏洞库👻
Python-爬取CVE漏洞库 最近吧准备复现一下近几年的漏洞,一个一个的去找太麻烦了.今天做到第几页后面过几天再来可能就不记得了.所以我想这搞个爬虫给他爬下来做个excel表格,那就清楚多了.奈何还 ...
- 纯 CSS 自定义多行省略:从原理到实现
文字溢出怎么展示,你的需求是什么?单行还是多行?截断,省略,自定义样式,自适应高度?在这里你都能找到答案.接下来我会由浅入深,从原理到实现,带你一步步揭开多行省略的面纱.我们先从最简单的单行溢出省略开 ...
- redis学习笔记(详细)——高级篇
redis学习笔记(详细)--初级篇 redis学习笔记(详细)--高级篇 redis配置文件介绍 linux环境下配置大于编程 redis 的配置文件位于 Redis 安装目录下,文件名为 redi ...
- 华为C/C++编码规范+《数学之美》感想
1.排版 1.1 程序块要采用缩进风格编写, 缩进的空格数为4个.(说明: 对于由开发工具自动生成的代码可以有不一致)1.2 相对独立的程序块之间.变量说明之后必须加空行.1.3 循环.判断等语句中若 ...
- 18-Spring Cloud Alibaba Nacos
简介 为什么叫Nacos 前四个字母分别为Naming和Configuration的前两个字母,最后的s为Service Nacos是什么 一个更易于构建云原生应用的动态服务发现.配置管理和服务管理平 ...
- SVN设置忽略文件列表以及丢失了预定增加的文件解决方法
设置svn忽略列表 Linux下svn命令行配置 1. 修改版本库的相关属性 2. svn 客户端的配置 Windows下 Tortoise SVN 设置 1. Tortoise SVN 上修改版本库 ...