Hive处理Json数据
Json 格式的数据处理
Json 数据格式是我们比较常用的的一种数据格式,例如埋点数据、业务端的数据、前后端调用都采用的是这种数据格式,所以我们很有必要学习一下这种数据格式的处理方法
准备数据
cat json.data
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
创建hive表并且加载数据
create table ods.ods_json_data(text string);
load data local inpath "/Users/XXX/workspace/hive/json.data" overwrite into table ods.ods_json_data;
get_json_object 和 json_tuple 函数
json_tuple 不支持json 的嵌套处理,但是支持一次性获取多个顶级的key对应的值
get_json_object 不支持一次获取多个值,但是支持复杂json 的处理
get_json_object()
用法:get_json_object(string json_string, string path) 前面我们介绍过如何查看函数的用法desc function get_json_object
返回值:String
说明:解析json的字符串json_string,返回path指定的内容。如果输入的json字符串无效,那么返回NUll,这个函数每次只能返回一个数据项。
具体示例: get_json_object(value,’$.id’)
select get_json_object(text,"$.movie") from ods.ods_json_data;
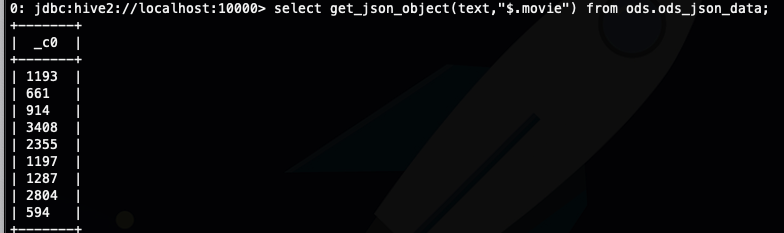
这个函数的不足之处是,它只能返回一个值,就是我们不能一次性从json 中提取多个值,如果要提取多个值的话,就要多次调用这个函数,但是我们下面介绍的json_tuple 就可以,但是这不是说这个函数不强或者怎么样,记住这个函数的api 可以帮你节约很多时间
json_tuple
用法:json_tuple(jsonStr, p1, p2, ..., pn) 整理的pn 就是我们要提取的键
返回值:tuple(v1,...vn) 这里的返回值v1 ... vn 和 键p1 .... pn 是相对应的
select json_tuple(text,'movie','rate','timeStamp','uid') from ods.ods_json_data;
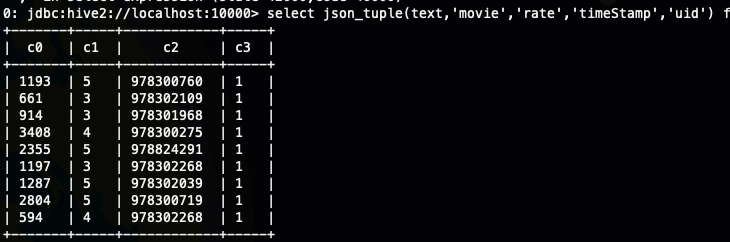
json_tuple相当于get_json_object的优势就是一次可以解析多个Json字段。
例子演示
1. 嵌套json 的处理
前面我们说了json_tuple不支持嵌套JSON 的处理
select get_json_object('{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1","info":{"name":"天之骄子"}}',"$.info.name")
select json_tuple('{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1","info":{"name":"天之骄子"}}',"info.name")

2. Json数组解析(get_json_object 实现)
SELECT get_json_object('[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]', '$.[0].website'), get_json_object('[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]', '$.[1].website');
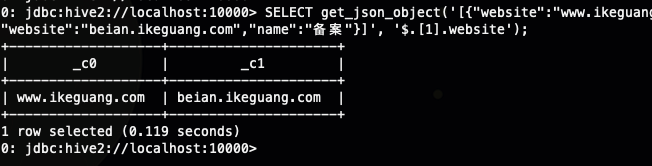
这个时候时候你发现我提取的都是json 数组中的website,有没有什么简单的办法呢,理论上get_json_object 只能有一个返回值,无论如何都需要写多个,那你有没有想过一个问题,我要是这个数组里面有100个元素都是json,我需要每一个json 的website 那我是不是需要写100次了,这个时候你要是仔细阅读这个函数的api 的话,你就会发现了另外一个符号*
SELECT get_json_object('[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]', '$.[*].website')
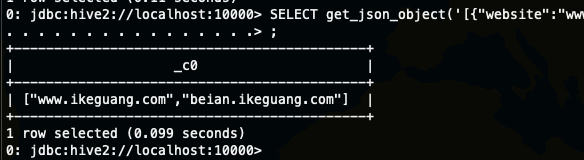
这下你知道了,get_json_object 是只能返回一个元素,不是只能返回一个字符串,上面本来就是一个json 数组,那要是我们是从json 里面解析出来的数组怎么处理呢?
SELECT get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]}', '$.info');

需要注意下面这样操作之后你拿到的就是一个json 字符串了,这下你就可以按照上面的方式再处理一次了
select get_json_object (get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]}', '$.info' ),'$.[1].website');

但是有时候我们希望直接获取,而不是通过这样嵌套的方式,这个时候其实就是将上面的嵌套的get_json_object函数的path 参数进行组合
SELECT get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]}', '$.info[1].website');

这个时候如果我们再上 * 进行加持,那就很简单了
SELECT get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]}', '$.info[*].website');

其实到这里我们学习了指定一个数组的某个下标获取一个元素,指定* 获取全部元素,那就如我就想获取前三个或者偶数个或者奇数个呢,哈哈,如果你回过头去看api 你就是知道了提供了一个Union operator,指定任意你想组合的下标即可,获取
SELECT get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"}]}', '$.info[0,1].website');

下面我们尝试获取一下偶数个,或者奇数个或者是一定范围内的奇数个或者偶数个,其实就是上面提供的数组切片,你可以参考api 进行使用
SELECT get_json_object('{"info":[{"website":"www.ikeguang.com","name":"我的生活记忆"},{"website":"beian.ikeguang.com","name":"备案"},{"website":"www.ikeguang2.com","name":"我的生活记忆"}]}', '$.info[0:2:2].website');
但是我尝试了一下,发现这个功能有bug,不能做到切片的效果,每次都是全部返回
SELECT get_json_object('{"info":[
{"website":"www.ikeguang.com","name":"我的生活记忆"},
{"website":"beian.ikeguang.com","name":"备案"},
{"website":"www.ikeguang2.com","name":"我的生活记忆"}]}', '$.info[0:2:2].website');
加载JSON 数据
对于上面json.data 的数据,我们能不能在load 数据到hive 的时候就处理,而不是load 完之后再到使用的时候去处理,尤其是针对这种嵌套结构不是很复杂的这种json 格式
create table ods.ods_json_parse_data(
movie string,
rate string,
`timeStamp` string,
uid string)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
load data local inpath "/Users/liuwenqiang/workspace/hive/json.data" overwrite into table ods.ods_json_parse_data;
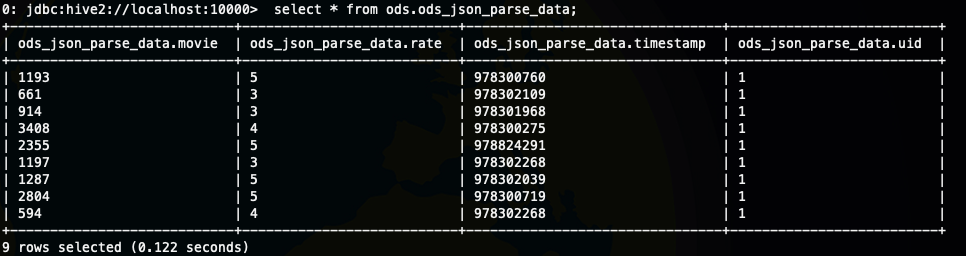
这种方法需要注意的是你的数据类型和字段名称都要匹配,否则就会报错或者不能获取到值,那要是复杂一点的嵌套结构呢,其实也可以,在上面的数据基础上添加了一个嵌套的字段也是可以的
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1","info":{"name":"天之骄子"}}
create table ods.ods_json_parse_data2(
movie string,
rate string,
`timeStamp` string,
uid string,
info map<string,string>)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS TEXTFILE;
load data local inpath "/Users/liuwenqiang/workspace/hive/json.data" overwrite into table ods.ods_json_parse_data2;

总结
- get_json_object 和 json_tuple 函数的使用场景和其优缺点
- 如果json 格式比较简单,那么可以在建表加载数据的时候就可以将json 处理掉,如果比较复杂也可以再加载的时候解析一部分,然后再通过SQL 进行解析
- 也可以尝试写一些UDF 函数来处理JSON
关注公众号:大数据技术派,回复"资料",领取
1024G资料。
Hive处理Json数据的更多相关文章
- hive 存储,解析,处理json数据
hive 处理json数据总体来说有两个方向的路走 1.将json以字符串的方式整个入Hive表,然后通过使用UDF函数解析已经导入到hive中的数据,比如使用LATERAL VIEW json_tu ...
- hive加载json数据解决方案
hive官方并不支持json格式的数据加载,默认支持csv格式文件加载,如何在不依赖外部jar包的情况下实现json数据格式解析,本编博客着重介绍此问题解决方案 首先创建元数据表: create EX ...
- 【spark】文件读写和JSON数据解析
1.读文件 通过 sc.textFile(“file://") 方法来读取文件到rdd中. val lines = sc.textFile("file://")//文件地 ...
- hive之Json解析(普通Json和Json数组)
一.数据准备 现准备原始json数据(test.json)如下: {"movie":"1193","rate":"5", ...
- spark SQL (五)数据源 Data Source----json hive jdbc等数据的的读取与加载
1,JSON数据集 Spark SQL可以自动推断JSON数据集的模式,并将其作为一个Dataset[Row].这个转换可以SparkSession.read.json()在一个Dataset[Str ...
- Hive解析Json数组超全讲解
在Hive中会有很多数据是用Json格式来存储的,如开发人员对APP上的页面进行埋点时,会将多个字段存放在一个json数组中,因此数据平台调用数据时,要对埋点数据进行解析.接下来就聊聊Hive中是如何 ...
- 使用TSQL查询和更新 JSON 数据
JSON是一个非常流行的,用于数据交换的文本数据(textual data)格式,主要用于Web和移动应用程序中.JSON 使用“键/值对”(Key:Value pair)存储数据,能够表示嵌套键值对 ...
- Hive读取外表数据时跳过文件行首和行尾
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 有时候用hive读取外表数据时,比如csv这种类型的,需要跳过行首或者行尾一些和数据无关的或者自 ...
- 利用Python进行数据分析(2) 尝试处理一份JSON数据并生成条形图
一.JSON 数据准备 首先准备一份 JSON 数据,这份数据共有 3560 条内容,每条内容结构如下: 本示例主要是以 tz(timezone 时区) 这一字段的值,分析这份数据里时区的分布情况. ...
随机推荐
- Vue3学习(五)之集成HTTP库axios
一.安装axios npm install axios@0.21.0 --save 二.axios的使用 1.在主页中引用axios 在Vue3新增了setup初始化方法,所以我们在这里开始使用并测试 ...
- Oracle12C安装教程
准备工作 网盘链接: https://pan.baidu.com/s/1gffHbOjImk1SfezdWO2Bpw 提取码: imft Oracle12C的安装 1.分别解压"winx64 ...
- 如何查找一个目录中所有c文件的总行数
如何查找一个目录中所有c文件的行数 面试题问到了一题,如何统计wc文件夹下所有文件的行数,包括了子目录. 最后在 https://blog.csdn.net/a_ran/article/details ...
- [对对子队]测试报告Beta
一.测试中发现的bug BETA阶段的新bug 描述 提出者(可能需要发现者在会议上复现) 处理人 是否解决 第四关中工作区的循环语句拖动到组件区后成本的大小比原来不一样的问题 梁河览 何瑞 是 循环 ...
- SpringBoot加密配置属性
一.背景 在系统中的运行过程中,存在很多的配置属性,比如: 数据库配置.阿里云配置 等等,这些配置有些属性是比较敏感的,是不应直接以明文的方式出现在配置文件中,因此对于这些配置我们就需要加密来处理. ...
- reactnative实现qq聊天消息气泡拖拽消失效果
前言(可跳过) 我在开发自己的APP时遇到了一个类似于qq聊天消息气泡拖拽消息的需求,因为在网上没有找到相关的组件,所以自己动手实现了一下 需求:对聊天消息气泡拖拽到一定长度松开时该气泡会消失(可自行 ...
- cf 11A Increasing Sequence(水,)
题意: A sequence a0, a1, ..., at - 1 is called increasing if ai - 1 < ai for each i: 0 < i < ...
- Windows内核基础知识-5-调用门(32-Bit Call Gate)
Windows内核基础知识-5-调用门(32-Bit Call Gate) 调用门有一个关键的作用,就是用来提权.调用门其实就是一个段. 调用门: 这是段描述符的结构体,里面的s字段用来标记是代码段还 ...
- Linux安装部署Zabbix
Zabbix 是一个企业级的分布式开源监控方案,能够监控各种网络参数以及服务器健康性和完整性的软件.Zabbix使用灵活的通知机制,允许用户为几乎任何事件配置基于邮件的告警.这样可以快速反馈服务器的问 ...
- java中lamda表达式用法
map-> list Map<String, Object> map = new HashMap<>(); List<String> list = new A ...