Centos下Ambari2.7.5的编译和安装
前言
终于,要开始写点大数据相关的文章了。当真的要开始写老本行的时候,还是考虑了挺久的。一是不知道从何处写起,二是如何能写点有意思的。
我们常说,过程比结果重要。也是有很多人喜欢准备完全之后,才会开始做一件事情。但往往还没开始,自己就慢慢地否定了自己的想法。
技术如人生,总有翻不完的山。对未来将要发生的事情有所期待、对未来可能会发生的事情又不抱有期待。我们能做的,只有走好眼前的每一步。
所以,这次就决定从过程开始写起。提出构思和想法,然后去实现,每完成一部分,就写下过程、感悟。可能最后没有达到预期的结果,但相信过程总有收获。
平台架构
玩大数据,走到哪,肯定是要有平台的。最基本的Hadoop生态HDFS、Yarn、Hive是要有的,Kafka、zookeeper肯定也是要有的,redis肯定也是要有的,Spark、Flink客户端肯定也是要有的。
这么多东西怎么搞呢?
搞三台虚拟机?舍不得折腾自己的笔记本。
搞三台服务器?成本太高。
看了看手上仅有的一台1Core 2G配置的CVM,不禁陷入了沉思...
面临问题
1Core 2G想搞这么多平台组件,能够搞得起来?
大数据集群不是需要多台机器做分布式吗?
解决方案
机器配置怎么低,肯定性能就不要考虑了。如果考虑性能,就用钞能力升级配置或者使用多台主机。
至于分布式需要的多台机器,就用docker容器化来进行解决。这台机器上,之前也搞过8节点的redis cluster,难点就是端口的映射。
对于端口,redis还好,Hadoop端口机器多,所以在映射的时候时候肯定会很麻烦,这个就到时候再说。
起点 Ambari
第一步肯定是安装Hadoop了。本来打算虚拟四个docker,然后搞个HA的Hadoop就完事了。但是,我就想着都弄到这了,就搞个Ambari吧,既能在线安装各个平台,还有监控运维界面,这逼格又高,功能又强,还不花钱何乐而不为?
所以第一步目标就是安装Ambari。
Ambari
当时我编译Ambari的时候最新版本还是2.7.5,现在已经是2.7.6了。编译的步骤跟着官方给出的文档即可。官方文档地址:https://cwiki.apache.org/confluence/display/AMBARI/Installation+Guide+for+Ambari+2.7.5
编译前准备
- 安装JDK、安装maven
- 配置node,npm install bower
- 安装数据库,我选用的是MySQL,并建库建表,命令如下:
create database ambari default charset=utf8;
CREATE USER 'ambari'@'%' IDENTIFIED BY 'ambari';
use ambari;
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;
grant all on ambari.* to ambari@'%';
mysql> set global validate_password_policy=LOW; set global validate_password_policy=LOW; ^C
mysql> CREATE USER 'ambari'@'%' IDENTIFIED BY 'ambari';
ERROR 1819 (HY000): Your password does not satisfy the current policy requirements
mysql> set global validate_password_length=6
-> ;
- 安装python2.6或者2.7,还需要使用setuptools模块,可以通过下面egg方式来进行安装。
# 下载链接:https://pypi.python.org/packages/2.7/s/setuptools/setuptools-0.6c11-py2.7.egg#md5=fe1f997bc722265116870bc7919059ea
sh setuptools-0.6c11-py2.7.egg
Step1:下载编译
官方文档给出的五个步骤中,最难的就是编译这一块,编译过程中会遇到各种问题。我当时用了一个星期的晚上,解决了十几个比较棘手的问题,之后耗时40分钟才编译成功。
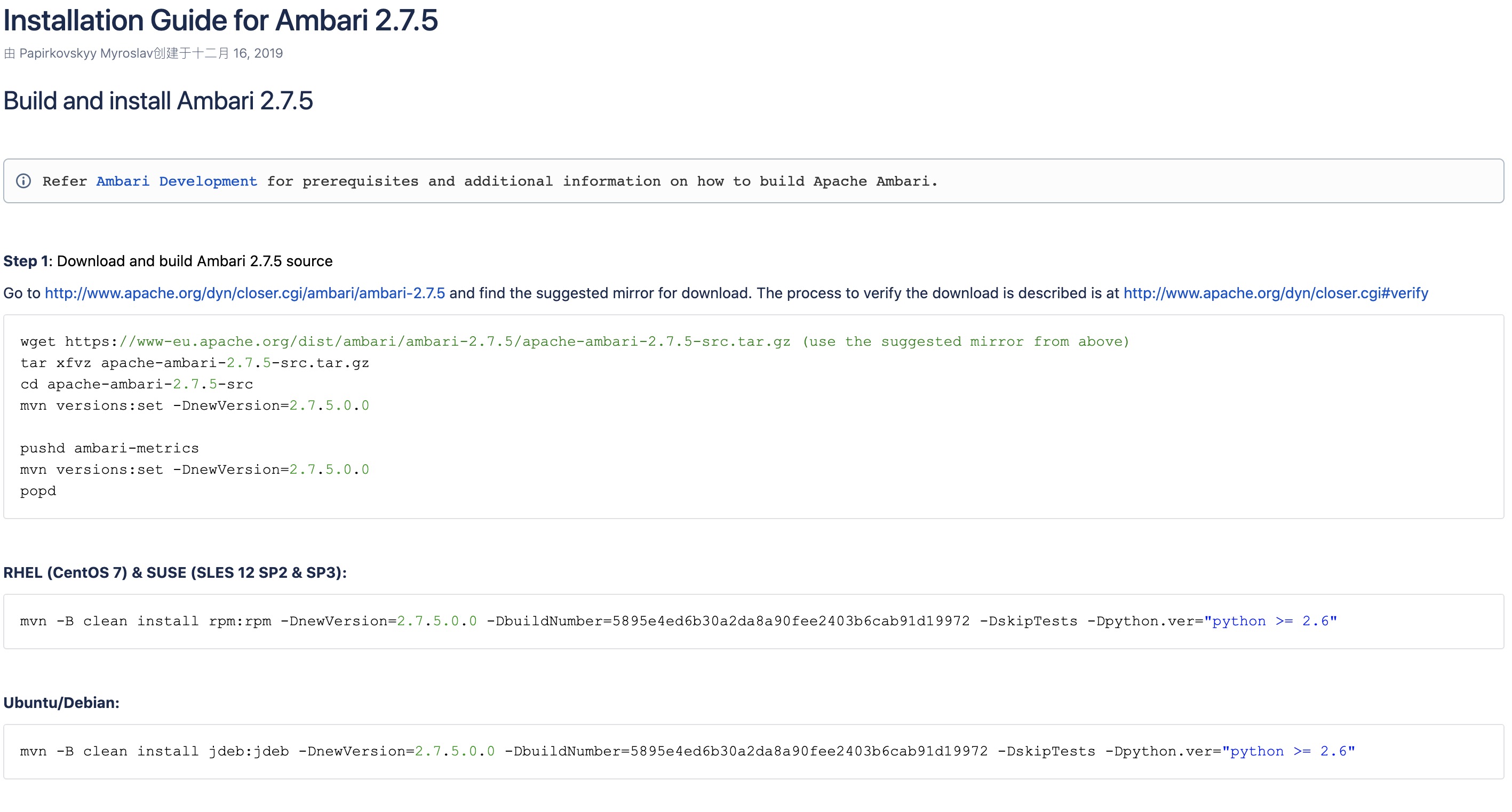
我的服务器系统是Centos,所以从官网给出的命令来看,我要做的就是将源码编译成rpm软件包,安装在服务器即可。
在实际操作中,我对编译命令进行了两处修改,一是通过nohup和&进行后台编译,二是通过设置-Drat.skip来绕过文件许可。
nohup mvn -B clean install rpm:rpm -DnewVersion=2.7.5.0.0 -DbuildNumber=5895e4ed6b30a2da8a90fee2403b6cab91d19972 -DskipTests -Dpython.ver="python >= 2.6" -Drat.skip=true &
编译后的源码包大小也从80M变成了8G:

编译成功之后,每个子模块的target目录下都会出现rpm安装包。

Step2:安装Ambari服务

如Step1最后一张图所示,执行install安装sever即可。
Step3:设置启动Ambari服务
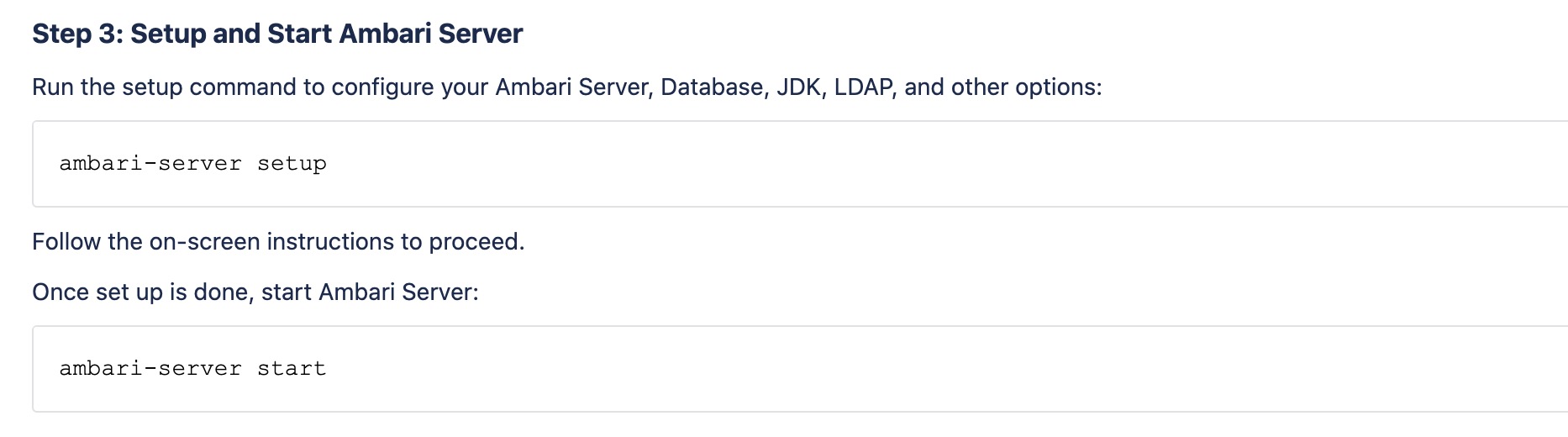
执行setup之后,进入设置页面,主要是对数据库的设置。

设置完成之后,使用start命令启动。

我这里使用了restart重启,监听的端口为8000(默认为8080)。
Step4:安装Ambari Agent
Agent是部署在集群的主机上,用来监控服务状态。这里我打算用docker作为集群节点,所以说这一步在后面的集群搭建中,会随着docker的创建和分配来同步操作。
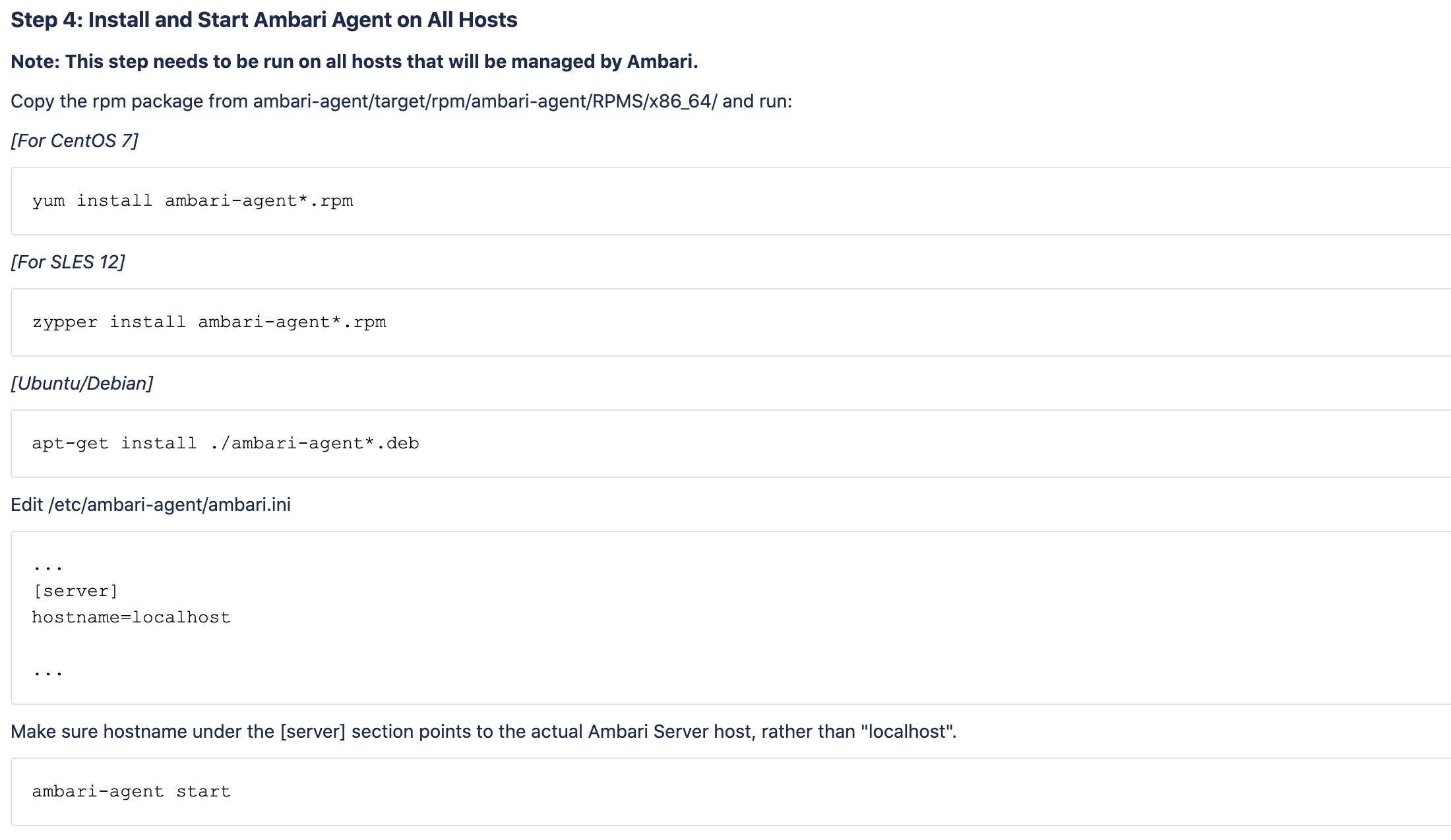
Step5:访问服务

8080端口即可访问到Amabri服务,默认账号密码admin/admin。

结语
Ambari的编译如果能一次通过最好,我在编译的时候遇到了问题,有的甚至还百度不到,只能自己想办法,所以编译的时候耐心一些。
后期会整理关于编译中遇到的一些问题,之前编译的好多问题都没有做一个完整的记录,正在努力复盘中。

Centos下Ambari2.7.5的编译和安装的更多相关文章
- centos下 Apache、php、mysql默认安装路径
centos下 Apache.php.mysql默认安装路径 http://blog.sina.com.cn/s/blog_4b8481f70100ujtp.html apache: 如果采用RPM包 ...
- 配置 Windows 下的 nodejs C++ 模块编译环境 安装 node-gyp
配置 Windows 下的 nodejs C++ 模块编译环境 根据 node-gyp 指示的 Windows 编译环境说明, 简单一句话就是 "Python + VC++ 编译环境&quo ...
- CentOS下Storm 1.0.0集群安装具体解释
本文环境例如以下: 操作系统:CentOS 6 32位 ZooKeeper版本号:3.4.8 Storm版本号:1.0.0 JDK版本号:1.8.0_77 32位 python版本号:2.6.6 集群 ...
- CentOS下MySQL 5.7.9编译安装
MySQL 5.7 GA版本的发布,也就是说从现在开始5.7已经可以在生产环境中使用,有任何问题官方都将立刻修复. MySQL 5.7主要特性: 更好的性能:对于多核CPU.固态硬盘.锁有着更好的优化 ...
- Centos下Sphinx的下载与编译安装
官方下载地址 http://sphinxsearch.com/downloads/release/ 百度云下载地址 https://pan.baidu.com/s/1gfmPbd5 wget ...
- centos下美团sql优化工具SQLAdvisor的安装
1.克隆代码 cd /usr/local/src/git clone https://github.com/Meituan-Dianping/SQLAdvisor.git 2.安装依赖(ubuntu下 ...
- Centos 下 Apache 原生 Hbase + Phoenix 集群安装(转载)
前置条件 各软件版本:hadoop-2.7.7.hbase-2.1.5 .jdk1.8.0_211.zookeeper-3.4.10.apache-phoenix-5.0.0-HBase-2.0-bi ...
- Centos下zabbix部署(二)agent安装并设置监控
1.配置zabbix源 rpm -ivh http://repo.zabbix.com/zabbix/3.0/rhel/7/x86_64/zabbix-release-3.0-1.el7.noarch ...
- linux 下 SpiderMonkey 1.7.0 编译和安装
wget http://ftp.mozilla.org/pub/mozilla.org/js/js-1.7.0.tar.gz tar xf js-1.7.0.tar.gz cd js/src make ...
随机推荐
- 记一次 WinDbg 分析 .NET 某工厂MES系统 内存泄漏分析
一:背景 1. 讲故事 上个月有位朋友加微信求助,说他的程序跑着跑着就内存爆掉了,寻求如何解决,截图如下: 从聊天内容看,这位朋友压力还是蛮大的,话说这貌似是我分析的第三个 MES 系统了,看样子 . ...
- [流畅的Python]第一章数据模型
这些来自同一家出版社的动物书 像是计算机科学界一盏盏指路明灯 余幼时 初试读 学浅 以为之晦涩难懂 像是老学究咬文嚼字 现在看起来还有些有趣 其实理工男大多都很有趣 这一章介绍了 怎么样去视线一个带有 ...
- Easticsearch概述(ES、Lucene、Solr)一
ES是在Lucene的基础上实现的 1.Lucene全文检索 lucene是一个全文搜索框架,而不是应用产品.因此它并不像http://www.baidu.com/或goolge Destop 那么拿 ...
- 【Java】包装类
文章目录 包装类 什么是包装类 基本数据类型-->包装类 包装类-->基本数据类型 自动装箱与自动拆箱 基本数据类型.包装类与String的转换 基础数据类型.包装类-->Strin ...
- Solon 开发,八、注入依赖与初始化
Solon 开发 一.注入或手动获取配置 二.注入或手动获取Bean 三.构建一个Bean的三种方式 四.Bean 扫描的三种方式 五.切面与环绕拦截 六.提取Bean的函数进行定制开发 七.自定义注 ...
- Configmap-K8s容器的配置文件
传递配置给容器化应用程序有几种方式: 嵌入应用本身: 通过命令行传递参数: 通过环境变量传递参数: 在k8s中无论你有没有使用configmap,以下方法均可以配置应用程序: 向容器传递命令行参数:c ...
- entity framework无法写入数据库.SaveChanges()失败
参考https://stackoverflow.com/questions/26745184/ef-cant-savechanges-to-db/28256645 https://www.codepr ...
- springMvc 启动过程
转载自https://www.jianshu.com/p/dc64d02e49ac 这里给出一个简洁的文字描述版SpringMVC启动过程: tomcat web容器启动时会去读取web.xml这样的 ...
- Autofac实现拦截器和切面编程
Autofac.Annotation框架是我用.netcore写的一个注解式DI框架,基于Autofac参考 Spring注解方式所有容器的注册和装配,切面,拦截器等都是依赖标签来完成. 开源地址:h ...
- QMainWindow(二)
mainwindow.h: #ifndef MAINWINDOW_H #define MAINWINDOW_H #include <QMainWindow> class MainWindo ...