Python语法进阶(2)- 正则表达式
1.初识正则表达式
1.1.什么是正则表达式
正则表达式是一个特殊的字符序列,便于检查一个字符串是否与某种模式匹配;应用于字符串,在字符串中通过复杂的过滤筛选等操作得到我们想要的数据;
正则表达式的特点 :
- 正则表达式的语法太多,可读性差
- 正则表达式通用行很强,能够适用于很多编程语言
1.2.正则表达式的使用场景
在实际开发过程中经常会有查找符合某些复杂规则的字符串的需要,比如:手机号、邮箱、图片地址 等,这时候想匹配或者查找符合某些规则的字符串就可以使用正则表达式了。
1.3.正则表达式模块re的用法
匹配字符串需要的条件:
- 正则表达式模块--re
- 匹配查找的规则
- 被查找的字符串



2.正则表达式的字符匹配
1 # coding:utf-8
2
3 import re
4
5 #将字符串中的数字提取出来
6 def had_number(data):
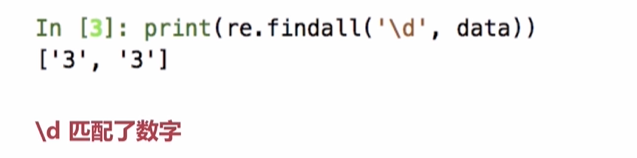
7 result=re.findall('\d',data)
8 print(result) #['3', '3', '1', '7', '5']
9 for i in result:
10 return True
11 return False
12
13 #去掉字符串中的数字
14 def remove_number(data):
15 result=re.findall('\D',data)
16 print(result) #['m', 'y', ' ', 'n', 'a', 'm', 'e', ' ', 'i', 's', ' ', 'z', 'h', 'a', 'n', 'g', 's', 'a', 'n', ',', 'm', 'y', ' ', 'a', 'g', 'e', ' ', ',', 't', 'o', 'p', ' ']
17 return ''.join(result)
18
19 if __name__=='__main__':
20 data='my name is zhangsan,my age 33,top 175'
21 result=had_number(data)
22 print(result) #True
23 result=remove_number(data)
24 print(result) #my name is zhangsan,my age ,top1 # coding:utf-8
2
3 import re
4
5 #判断字符串以什么开头
6 def startswith(sub,data):
7 _sub='\A%s' % sub
8 result=re.findall(_sub,data)
9 for i in result:
10 return True
11 return False
12
13 #判断字符串以什么结尾
14 def endswith(sub,data):
15 _sub='%s\Z' % sub
16 result=re.findall(_sub,data)
17 if len(result) != 0:
18 return True
19 else:
20 return False
21
22 #判断字符串真实的长度
23 def real_len(data):
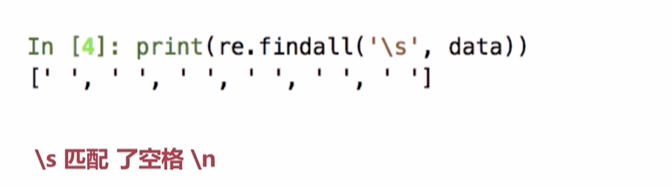
24 result=re.findall('\S',data)
25 print(result) #['m', 'y', 'n', 'a', 'm', 'e', 'i', 's', 'z', 'h', 'a', 'n', 'g', 's', 'a', 'n', ',', 'm', 'y', 'a', 'g', 'e', '3', '3', ',', 't', 'o', 'p', '1', '7', '5']
26 return len(result)
27
28 if __name__=='__main__':
29 data='my name is zhangsan,my age 33,top 175'
30 #startswith
31 result=startswith('my',data)
32 result1=startswith('myw',data)
33 print(result) #True
34 print(result1) #False
35 #endswith
36 result2=endswith('75',data)
37 result3=endswith('000',data)
38 print(result2) #True
39 print(result3) #False
40 #real_len
41 result4=real_len(data)
42 print(len(data)) #37
43 print(result4) #31







3.正则表达式的量词












4.正则的综合练习
1 # coding:utf-8
2 import re
3
4 #网址匹配
5 def check_url(url):
6 result=re.findall('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+',url)
7 if len(result) !=0 :
8 return True
9 else:
10 return False
11 #获取网址,通过组()获取我们过滤出来的信息
12 def get_url(url):
13 result = re.findall('http[a-zA-Z]*://(\w*\.*\w+\.\w+)', url)
14 if len(result) !=0:
15 return result[0]
16 else:
17 return ''
18
19 #检验邮箱是否正确
20 def get_email(data):
21 result=re.findall('.+@.+\.[a-zA-Z]+',data)
22 return result
23
24 #获取网页style属性信息
25 def get_html_data(data):
26 result=re.findall('style="(.*?)"',data) #?的作用:例子中筛选规则结尾的双引号找到一次就结束,而不是贪婪的找到最后一个双引号
27 return result
28
29 #获取网页所有属性的值
30 def get_all_data_html(data):
31 result=re.findall('="(.+?)"',data)
32 return result
33
34 if __name__=='__main__':
35 url = 'http://www.baidu.com'
36 emails='zhangsan@qq.com'
37 html = ('<div class="s-top-nav" style="display:none;">'
38 '</div><div class="s-center-box"></div>')
39 print(check_url(url)) #True
40 print(get_url(url)) #www.baidu.com
41 print(get_email(emails)) #['zhangsan@qq.com']
42 print(get_html_data(html)) #['display:none;']
43 print(get_all_data_html(html)) #['s-top-nav', 'display:none;', 's-center-box']
5.正则表达式的re模块
5.1.findall()的使用
5.2.search()的使用
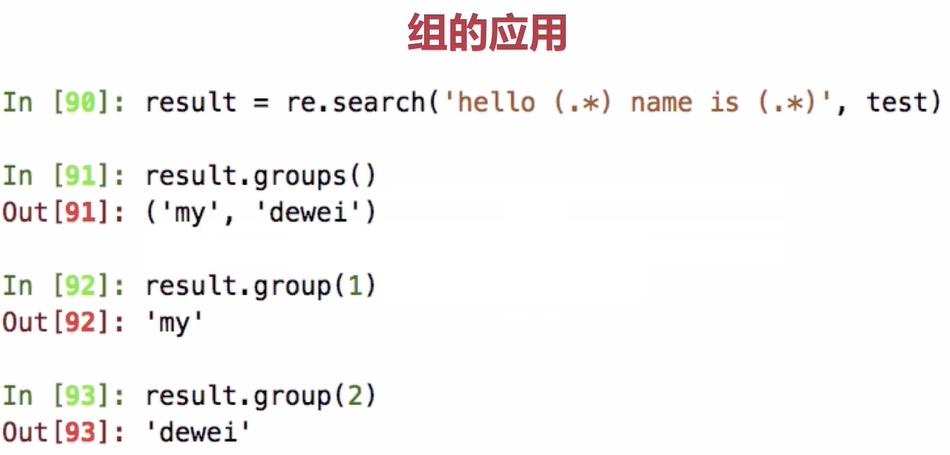
5.3.group()与groups()的使用
跟search()配合使用,search返回匹配对象;group/groups读取组的序列是从1开始
5.4.split()正则替换
根据正则规则对字符串进行切割
\W字符数字以外的字符,相当于根据图示字符串中的空格作为匹配规则,进行切割
5.5.compile的使用
5.6.match的使用
match只会匹配字符串从头开始的信息,match返回的匹配对象也可以通过group进行调用
5.7.re的额外匹配要求
1 # coding:utf-8
2
3 import re
4
5 def check_url(url):
6 re_g = re.compile('[a-zA-Z]{4,5}://\w*\.*\w+\.\w+')
7 print(re_g) #re.compile('[a-zA-Z]{4,5}://\\w*\\.*\\w+\\.\\w+')
8 result = re_g.findall(url)
9 if len(result) != 0:
10 return True
11 else:
12 return False
13
14 def get_url(url):
15 re_g = re.compile('[https://|http://](\w*\.*\w+\.\w+)')
16 result = re_g.findall(url)
17 if len(result) != 0:
18 return result[0]
19 else:
20 return ''
21
22
23 def get_email(data):
24 re_g = re.compile('.+@.+\.[a-zA-Z]+')
25 result = re_g.findall(data)
26 return result
27
28
29 html = ('<div class="s-top-nav" style="display:none;">'
30 '</div><div class="s-center-box"></div>')
31
32
33 def get_html_data(data):
34 re_g = re.compile('style="(.*?)"')
35 result = re_g.findall(data)
36 return result
37
38 def get_all_data_html(data):
39 re_g = re.compile('="(.+?)"')
40 result = re_g.findall(data)
41 return result
42
43
44 if __name__ == '__main__':
45 result = check_url('http://www.baidu.com/')
46 print(result) #True
47 result = get_url('https://www.baidu.com/')
48 print(result, 'get_url') #www.baidu.com get_url
49 result = get_email('dewei@123.net')
50 print(result) #['dewei@123.net']
51 result = get_html_data(html)
52 print(result) #['display:none;']
53 result = get_all_data_html(html)
54 print(result) #['s-top-nav', 'display:none;', 's-center-box']
55 re_g = re.compile(('<div class="(.*?)" style="(.*?)">'
56 '</div><div class="(.*?)"></div>'))
57 result = re_g.search(html)
58 print(result.groups()) #('s-top-nav', 'display:none;', 's-center-box')
59 print(result.group(1)) #s-top-nav
60 print(result.group(2)) #display:none;
61 print(result.group(3)) #s-center-box
62 # print(result.group(4))
63 re_g = re.compile('\s')
64 result = re_g.split(html)
65 print(result) #['<div', 'class="s-top-nav"', 'style="display:none;"></div><div', 'class="s-center-box"></div>']
66
67 re_g = re.compile('<div class="(.*?)"')
68 result = re_g.match(html)
69 print(result.span()) #正则对象.span()返回对象的序列范围,(0, 22)
70 print(html[: 22]) #<div class="s-top-nav"











6.Python常见匹配案例
6.1.匹配1-100之间的数
1 import re
2
3 s = '100' # 1-100内的任意数字
4 ret = re.match(r'(100|[1-9]\d{0,1})$', s)
5 print(ret.group())
6 # 运行结果:
7 # 100
6.2.匹配座机号码
1 import re
2
3 s = "010-12345678"
4 ret = re.search(r'^\d{3,4}-\d{7,8}$', s)
5 print(ret.group())
6 # 运行结果:
7 # 010-12345678
6.3.匹配5-10位纯数字组成的qq号码,且不能以0开头
1 import re
2
3 s = "11010"
4 ret = re.match(r'[1-9]\d{4,9}$', s)
5 if ret != None:
6 print(ret.group())
7 else:
8 print('匹配失败!')
9 # 运行结果:
10 # 11010
6.4.取出字符串中的所有字母
1 import re
2
3 s = "43arwer32656fafa6546jjuy#H"
4 res = re.compile(r'[a-zA-Z]+')
5 ret = res.findall(s)
6 print(ret)
7 # 运行结果:
8 # ['arwer', 'fafa', 'jjuy', 'H']
6.5.找出以字母y结尾的单词,忽略大小写
1 import re
2
3 s = 'study hard and make progress every day'
4 res = re.compile(r'\w+y\b', re.I) # \b为边界
5 ret = res.findall(s)
6 print(ret)
7 # 运行结果:
8 # ['study', 'every', 'day']
6.6.将多个重复的字母替换成&
1 import re
2
3 s = "PythondddJavauuuHTMLFFPHP"
4 res = re.compile(r'([a-zA-Z])\1+')
5 ret = res.sub('&', s)
6 print(ret)
7 # 运行结果:
8 # Python&Java&HTML&PHP
6.7.将字符串变成 '我要学Python编程
1 import re
2
3 s = "我我...我我...我要..要要...要要...学学学...学学..Python...编编编..编程..程.程...程...程"
4 res = re.sub(r'\W+', '', s)
5 ret = re.sub(r'(.)\1+', r'\1', res)
6 print(ret)
7 # 运行结果:
8 # 我要学Python编程
Python语法进阶(2)- 正则表达式的更多相关文章
- Python语法进阶
1.变量进阶 2.局部变量.全局变量 3.函数进阶 4.函数进阶
- Python语法进阶(1)- 进程与线程编程
1.进程与多进程 1.1.什么是进程 进程就是程序执行的载体 什么叫多任务? 多任务就是操作系统可以同时运行多个任务.比如你一边在用浏览器学习,还一边在听音乐,,这就是多任务,至少同时有3个任务正在运 ...
- python进阶11 正则表达式
python进阶11 正则表达式 一.概念 #正则表达式主要解决什么问题? #1.判断一个字符串是否匹配给定的格式,判断用户提交的又想的格式是否正确 #2.从一个字符串中按指定格式提取信息,抓取页面中 ...
- python进阶(20) 正则表达式的超详细使用
正则表达式 正则表达式(Regular Expression,在代码中常简写为regex. regexp.RE 或re)是预先定义好的一个"规则字符率",通过这个"规 ...
- [.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门
[.net 面向对象程序设计进阶] (2) 正则表达式 (一) 快速入门 1. 什么是正则表达式? 1.1 正则表达式概念 正则表达式,又称正则表示法,英文名:Regular Expression(简 ...
- [.net 面向对象程序设计进阶] (3) 正则表达式 (二) 高级应用
[.net 面向对象程序设计进阶] (2) 正则表达式 (二) 高级应用 上一节我们说到了C#使用正则表达式的几种方法(Replace,Match,Matches,IsMatch,Split等),还 ...
- Python标准库01 正则表达式(re包)
python正则表达式基础 简单介绍 正则表达式并不是python的一部分.正则表达式是用于处理字符串的强大工具,拥有自己独特的语法及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大 ...
- python 优雅的使用正则表达式 ~ 2
使用正则表达式 那些基础的理论也说了不少了现在就开始 实操 ( 不知道为啥特别喜欢这个词... ) 吧 . 上一节课说过 正则表达式也是一门语言 , 他被集成到了python当中 , 并且用 re 模 ...
- Python之re模块 —— 正则表达式操作
这个模块提供了与 Perl 相似l的正则表达式匹配操作.Unicode字符串也同样适用. 正则表达式使用反斜杠" \ "来代表特殊形式或用作转义字符,这里跟Python的语法冲突, ...
随机推荐
- 如何查看mysql的用户权限
查询语句:select * from mysql.user where user='root'\G;user是用户名 <privileges>是一个用逗号分隔的你想要赋予的MySQL用户权 ...
- 复盘报告:心跳数据丢失,从发现到解决历经一年多的bug
时间线 大约在2020年10月,内网测试服服务端更新,发现进程A重启后,与其他进程之间的心跳协议不通,不能正常的提供服务.重启后,就正常了. 这个情况持续了很长时间.只在重启时才会出现,且发生概率很低 ...
- 【刷题-LeetCode】223. Rectangle Area
Rectangle Area Find the total area covered by two rectilinear rectangles in a 2D plane. Each rectang ...
- 巅峰对决之Swarm、Kubernetes、Mesos
另外一篇 https://www.sohu.com/a/157185937_287582 Docker Docker是一个主流容器管理工具,它是第一个基于Linux容器(LXC)的[2],但是现在被r ...
- 集合框架-工具类-Collection-toArray方法
1 package cn.itcast.p3.toolclass.arrays.demo; 2 3 import java.util.ArrayList; 4 import java.util.Arr ...
- URL Rewrite(四种重定向策略)
目录 一:Rewrite基本概述 1.Rewrite简介 2.Rewrite基本概述 3.Rewrite作用 4.什么是URL? 二:rewrite语法 三:Rewrite标记Flag 1.last和 ...
- 使用 electron 和 electron-forge 加载 本地磁盘资源 img 的问题
最近在学习使用 electron 进行桌面开发一款图片压缩的软件.遇到了加载本地磁盘文件的问题.记录一下其解决方案. 使用 electron 加载本地磁盘文件 第一种方法 设置webPreferenc ...
- 一劳永逸,解决.NET发布云服务器的时区问题
国内大多数开发者使用的电脑,都是使用的北京时间,日常开发的过程中其实并没有什么不便:不过,等遇到了阿里云等云服务器,系统默认使用的时间大多为UTC时间,这个时候,时区和时间的问题,就是不容忽视的大问题 ...
- PyTorch 介绍 | DATSETS & DATALOADERS
用于处理数据样本的代码可能会变得凌乱且难以维护:理想情况下,我们希望数据集代码和模型训练代码解耦(分离),以获得更好的可读性和模块性.PyTorch提供了两个data primitives:torch ...
- java中的继承 和多态。
package com.aaa.zxf.ajax.test; /** *一. java 中的继承和多态. * * 继承的特性? * 1.实现继承的方式 * A 如何建立继承关系(一个类继承于 另一个类 ...