Caffe 议事(二):从零开始搭建 ResNet 之 网络的搭建(上)
3.搭建网络:
搭建网络之前,要确保之前编译 caffe 时已经 make pycaffe 了。
步骤1:导入 Caffe
我们首先在 ResNet 文件夹中建立一个 mydemo.py 的文件,本参考资料我们用 spyder 打开。要导入 Caffe 的话直接 import caffe 是不可以的,因为系统找不到 caffe module,这时候要告诉系统 caffe 在哪里可以导入,因此需要添加 caffe 的路径,准确地说是 caffe-master/python 路径。为了以后的方便,我们在 ResNet 中再建立一个 init_path.py,在这个文件中写入以下代码并保存:
import os.path as osp
import sys # 添加路径到系统路径
def add_path(path):
if path not in sys.path:
sys.path.insert(0,path) # 返回当前文件所在目录
this_dir = osp.dirname(__file__)
# 组合成caffe的路径
pycaffe_path = osp.join(this_dir, 'caffe-master', 'python')
# 添加路径
add_path(pycaffe_path)
因为 init_path.py 是在 …/ResNet 下,所以 this_dir 这个返回的就是 …/ResNet 目录,那么 pycaffe_path = …/ResNet/caffe-master/python,这个路径添加进系统路径后,我们在 mydemo.py 中键入如下代码,然后运行,不报错就说明已经导入 Caffe 了。
import init_path
import caffe
import numpy as np
from caffe import layers as L, params as P
Fig 10 成功导入 Caffe
步骤2:创建网络的 prototxt 文件
Caffe 里面跑网络只需要 solver.prototxt 就可以了,solver 里面含有网络的模型(包括训练和测试的网络),模型也是 prototxt 文件。因此我们需要生成 solver 的 prototxt 和网络的 prototxt 文件。我们先生成网络的 prototxt 文件,在 ResNet 文件夹中再新建一个文件夹叫 res_net_model,用来存储网络模型文件。我们补充 mydemo.py 如下:
# -*- coding: utf-8 -*-
import init_path
import caffe
import numpy as np
import os.path as osp
from caffe import layers as L, params as P, to_proto this_dir = osp.dirname(__file__) def ResNet(split):
pass # 生成 ResNet 网络的 prototxt 文件
def make_net(): # 创建 train.prototxt 并将 ResNet 函数返回的值写入 train.prototxt
with open(this_dir + '/res_net_model/train.prototxt', 'w') as f:
f.write(str(ResNet('train'))) # 创建 test.prototxt 并将 ResNet 函数返回的值写入 test.prototxt
with open(this_dir + '/res_net_model/test.prototxt', 'w') as f:
f.write(str(ResNet('test'))) if __name__ == '__main__': make_net()
每次执行 mydemo.py 时,首先运行 make_net(),然后在 make_net 函数中创建 prototxt 文件,将 ResNet 返回的内容写入 prototxt,那么最关键的就是在 ResNet 返回的值。我们先给出在 ResNet 数据层的例子:
def ResNet(split):
# 写入数据的路径
train_file = this_dir + '/caffe-master/examples/cifar10/cifar10_train_lmdb'
test_file = this_dir + '/caffe-master/examples/cifar10/cifar10_test_lmdb'
mean_file = this_dir + '/caffe-master/examples/cifar10/mean.binaryproto'
# source: 导入的训练数据路径;
# backend: 训练数据的格式;
# ntop: 有多少个输出,这里是 2 个,分别是 n.data 和 n.labels,即训练数据和标签数据,
# 对于 caffe 来说 bottom 是输入,top 是输出
# mirror: 定义是否水平翻转,这里选是
# 如果写是训练网络的 prototext 文件
if split == 'train':
data, labels = L.Data(source = train_file, backend = P.Data.LMDB,
batch_size = 128, ntop = 2,
transform_param = dict(mean_file = mean_file,
crop_size =28,
mirror = True))
# 如果写的是测试网络的 prototext 文件
# 测试数据不需要水平翻转,你仅仅是用来测试
else:
data, labels = L.Data(source = test_file, backend = P.Data.LMDB,
batch_size = 128, ntop = 2,
transform_param = dict(mean_file = mean_file,
crop_size =28))
有人或许有疑问,为什么会有 L.data?L.Data 里面有这么多参数怎么来的?在 spyder 上面即使打了 L. 也不会提示 L 有哪些具体的函数(只显示系统固有函数),那么如何知道的呢?在 caffe-master/src/caffe/proto/caffe.proto 里面有这些函数的介绍,这是个混合编译的文件,当然读里面的内容并不难。下面是我们详细来说明:

Fig 11 caffe.proto 数据层截图
在 caffe.proto 搜索 DataParameter,我们就能找到这些参数,那么数据层的名字叫什么呢?很简单,把 Paramter 去掉就是了,也就是 L.Data,数据层有哪些参数,参数的类型都是什么,上面写得都很清楚,我们的例子用到了 source 和 batch_size(这 2 个必须指定),其他的参数都有default 选项,source 类型是 string,我们就知道是字符串类型,那就是存数据的路径了;batch_size 是 uint32,就是数字了;backend 有点特别,是 DB 类型的,我们看上面 DB 里面有 LEVELDB 和 LMDB,那么我们写的时候这样写 backend = P.Data.LMDB 或者 P.Data.LEVELDB,因为这里 default 是 LEVELDB 格式,而我们是数据类型是 LMDB,所以要赋值 backend,其他的依次类推了。
因为 caffe 里面训练基本都是用 SGD(随机梯度下降)的方法,因此都要取样本块,一次迭代只拿一个 batch 来训练,这里 batch_size 我们就设置为 128 (当然你也可以是 100 或者其他什么,不过建议不要太大)。为什么要设置 mean_file 路径?设置这个路径是为了让数据减去它的均值,这样网络收敛会更快,效果也往往会更好,相当于一个简单的 preprocessing 的过程。为什么要设置 crop_size?设置 crop_size 为 28 意味着将原来的 3 X 32 X 32 大小的图像随机剪裁成 3 X 28 X 28 大小的图像块作为输入数据,虽然论文中作者是在原来 3 X 32 X 32 大小的图像的上下左右加上 4 层 pad,pad 的值均为 0,变成了 3 X 40 X 40 的图像,然后在这个图像上随机剪裁成 3 X 32 X 32 大小图像作为输入数据,但这里为了快速实现 ResNet 因此采用了一个折中的办法,由于输入数据大小变成了 3 X 28 X 28,所以测试数据要进行剪裁成同样大小,这种剪裁的方法是 data augmentation的一种,可以增加样本的多样性。为什么要设置 mirror?mirror 设置为 True 意味将剪裁后的图像进行随机水平翻转,既要么翻转要么不翻转。跟上面的 data augmentation 一样,也是一种增加样本多样性的方法,我们认为图像经过水平翻转之后里面的物体仍然是那个物体。
数据层我们定义好了以后,接下来我们定义 ResNet Block,因为 ResNet Block 是有规律的,所有我们再额外写一些函数,补充代码如下:
def conv_BN_scale_relu(split, bottom, nout, ks, stride, pad):
conv = L.Convolution(bottom, kernel_size = ks, stride = stride,
num_output = nout, pad = pad, bias_term = True,
weight_filler = dict(type = 'xvaier'),
bias_filler = dict(type = 'constant'),
param = [dict(lr_mult = 1, decay_mult = 1),
dict(lr_mult = 2, decay_mult = 0)])
if split == 'train':
# 训练的时候我们对 BN 的参数取滑动平均
BN = L.BatchNorm(
conv, batch_norm_param = dict(use_global_stats = False),
in_place = True, param = [dict(lr_mult = 0, decay_mult = 0),
dict(lr_mult = 0, decay_mult = 0),
dict(lr_mult = 0, decay_mult = 0)])
else:
# 测试的时候我们直接是有输入的参数,BN 的学习率惩罚设置为 0,由 scale 学习
BN = L.BatchNorm(
conv, batch_norm_param = dict(use_global_stats = True),
in_place = True, param = [dict(lr_mult = 0, decay_mult = 0),
dict(lr_mult = 0, decay_mult = 0),
dict(lr_mult = 0, decay_mult = 0)])
scale = L.Scale(BN, scale_param = dict(bias_term = True, in_place = True))
relu = L.ReLu(scale, in_place = True)
return scale, relu
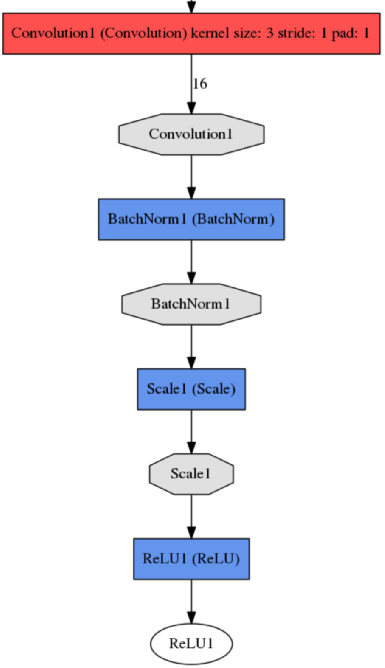
Fig 12 conv_BN_scale_relu 函数输入到输出结构
对 conv_BN_scale_relu 函数的解释:输入的数据为 bottom,nout 是卷积核的个数,也等于输出数据的通道数,ks 是卷积核的大小,3 的意思是 3 X 3 大小的卷积核,stride 意思是步长,pad 的意思是在输入数据上下左右补多少层 0,卷积之后我们还对数据进行 BN(BatchNormalization)操作,为什么要进行 BN,《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》这篇论文讲到过会加速网络的训练速度,具体这里就不讲了,然而 caffe 中 BN 层并不能学习到 α 和 β 参数,因此要加上 scale 层学习,这是作者在 ResNet code主页上 https://github.com/KaimingHe/deep-residual-networks 提到的:

经过scale层之后,我们再经过一个激活函数ReLU,我们返回的值是scale层的输出和ReLU的输出,这样可以供我们选择。下面讲解另外的一个函数:
def ResNet_block(split, bottom, nout, ks, stride, projection_stride, pad):
# 1 代表不需要 1 X 1 的映射
if projection_stride == 1:
scale0 = bottom
# 否则经过 1 X 1,stride = 2 的映射
else:
scale0, relu0 = conv_BN_scale_relu(split, bottom, nout, 1,
projection_stride, 0)
scale1, relu1 = conv_BN_scale_relu(split, bottom, nout, ks,
projection_stride, pad)
scale2, relu2 = conv_BN_scale_relu(split, bottom, nout, ks, stride, pad)
wise = L.Eltwise(scale2, scale0, operation = P.Eltwise.SUM)
wise_relu = L.ReLu(wise, in_place = True)
return wise_relu
我们在 ResNe t结构介绍部分中提到了网络的结构,发现输入数据经过 2 次卷积操作后再与输入数据相加即为 ResNet 的基本结构,因此这个 ResNet_block 就定义了这个部分。
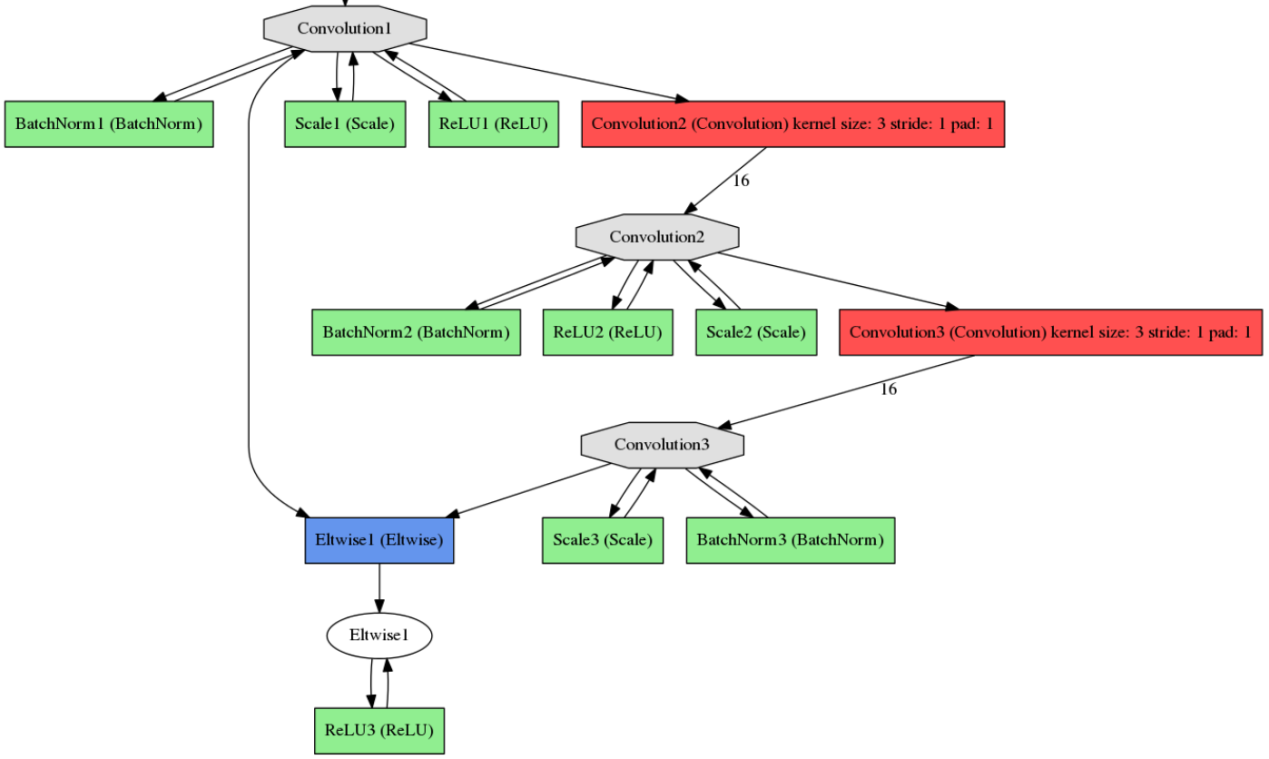
Fig 13 ResNet_bloc k函数输入到输出的结构
Caffe 议事(二):从零开始搭建 ResNet 之 网络的搭建(上)的更多相关文章
- Caffe 议事(三):从零开始搭建 ResNet 之 网络的搭建(中)
上面2个函数定义好了,那么剩下的编写网络就比较容易了,我们在ResNet结构介绍中有一个表,再贴出来: Layer_name Output_size 20-layer ResNet Conv1 32 ...
- NASNet学习笔记—— 核心一:延续NAS论文的核心机制使得能够自动产生网络结构; 核心二:采用resnet和Inception重复使用block结构思想; 核心三:利用迁移学习将生成的网络迁移到大数据集上提出一个new search space。
from:https://blog.csdn.net/xjz18298268521/article/details/79079008 NASNet总结 论文:<Learning Transfer ...
- iOS开发网络篇—搭建本地服务器
iOS开发网络篇—搭建本地服务器 一.简单说明 说明:提前下载好相关软件,且安装目录最好安装在全英文路径下.如果路径有中文名,那么可能会出现一些莫名其妙的问题. 提示:提前准备好的软件 apache- ...
- 使用arm开发板搭建无线mesh网络(一)
由于项目的需要,老板让我使用arm开发板(友善之臂的tiny6410)搭建无线mesh网络.一般而言,无线自组织网络的网络设备都是由用户的终端设备来充当,这些终端设备既要处理用户的应用数据,比如娱乐, ...
- 搭建企业级NFS网络文件共享服务说明[一]
1.1.0. 概述: 共享/NFS目录给整个192.168.25.0/24网段主机读写 man nfs 可以查看mount的信息 rpc端口111 nfs主端口2049 1.1.1. 搭建NFS环境 ...
- 微信小程序从零开始开发步骤(一)搭建开发环境
从零到有写一个小程序系列专题,很早以前就想写来分享,但由于项目一直在进展,没有过多的时间研究技术,现在可以继续分享了. 1:注册 用没有注册过微信公众平台的邮箱注册一个微信公众号, 申请帐号 ,网址: ...
- 陈云pytorch学习笔记_用50行代码搭建ResNet
import torch as t import torch.nn as nn import torch.nn.functional as F from torchvision import mode ...
- 十分钟一起学会ResNet残差网络
作者 | 荔枝boy 目录 深层次网络训练瓶颈:梯度消失,网络退化 ResNet简介 ResNet解决深度网络瓶颈的魔力 ResNet使用的小技巧 总结 深层次网络训练瓶颈:梯度消失,网络退化 深度卷 ...
- Retrofit2.0+RxJava+Dragger2实现不一样的Android网络架构搭建
Tamic :csdn http://blog.csdn.net/sk719887916 众所周知,手机APP的核心就在于调用后台接口,展示相关信息,方便我们在手机上就能和外界交互.所以APP中网络框 ...
随机推荐
- JavaScript decodeURI()与decodeURIComponent() 使用与区别
decodeURI()定义和用法:decodeURI()函数可对encodeURI()函数编码过的URI进行解码.语法:decodeURI(URIstring)参数描述:URIstring必需,一个字 ...
- 开始SDK之旅-入门2-集成流程图、轨迹图到系统
http://bbs.ccflow.org/showtopic-2562.aspx 经测试,基本可用,还需增加 WF/Admin/pub.ascx 首先你得先理解流程图的数据的获取方式,其他的就很容易 ...
- git连接报错:Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password)
在Linux上已经安装过git(自己搭建)了,本机(windows)想连接过去,通过git bash敲了下clone命令提示没权限: $ git clone git@111.11.111.11:cod ...
- PHP代码实现 1
$PHP-SRC/run-test.php 因为如果在同一个进程中执行, 测试就会停止,后面的测试也将无法执行,php中有很多将脚本隔离的方法比如: system(),exec()等函数,这样可以使用 ...
- Makefile编写 一 *****
编译:把高级语言书写的代码转换为机器可识别的机器指令.编译高级语言后生成的指令虽然可被机器识别,但是还不能被执行.编译时,编译器检查高级语言的语法.函数与变量的声明是否正确.只有所有的语法正确.相关变 ...
- Android Studio使用JDBC远程连接mysql的注意事项(附示例)
JDBC为java程序访问各种类型的关系型数据库提供了统一的接口,用户不必针对不同数据库写出不同的代码,但是使用JDBC必须得下载相应的驱动,比如我这里是要连接mysql,于是就到mysql官网去下载 ...
- charles 小米手机安装Charles证书
1.手机Wi-Fi设置手动代理,添加IP和端口号 此处是:192.168.63.143:8888, 2.保存证书,PC端访问 chls.pro/ssl 下载pem证书,发送到手机 adb push c ...
- 关于&&和||
从alert(1&&2)输出为2谈起 一.先来说说||(逻辑或),从字面上来说,只有前后都是false的时候才返回false,否则返回true. alert(true||false); ...
- 「小程序JAVA实战」小程序的留言和评价功能(70)
转自:https://idig8.com/2018/10/28/xiaochengxujavashizhanxiaochengxudeliuyanhepingjiagongneng69/ 目前小程序这 ...
- Spring Boot实践——统一异常处理
注解说明 @ControllerAdvice,是Spring3.2提供的新注解,从名字上可以看出大体意思是控制器增强.让我们先看看@ControllerAdvice的实现: /** * Special ...