Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath
1、快速开始
XPath是一种可以快速在HTML文档中选择并抽取元素、属性和文本的方法。
在Chrome,打开开发者工具,可以使用$x工具函数来使用XPath来选择元素,比如选中所有的超链接。
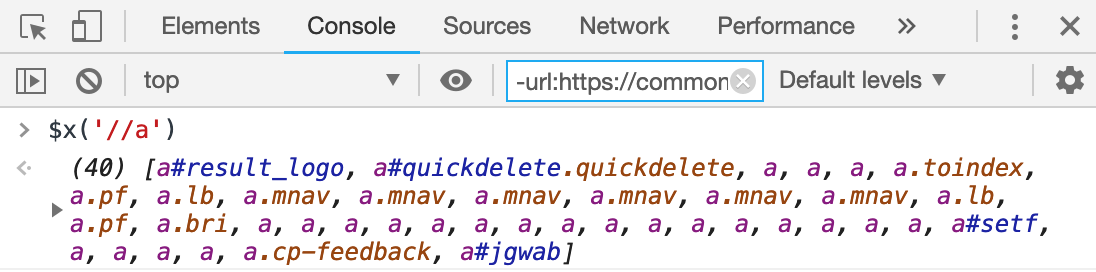
1.1、XPath的基本格式
XPath通过"路径表达式"(Path Expression)来选择节点。
在形式上,"路径表达式"与传统的文件系统非常类似。

比如我们依次获得Html节点(即最根节点)、Html下的Body节点、Html下的Body下的所有Div节点。
单斜杠与双斜杠:
在这里我们使用了单斜杠(/)作为最开始的元素,表示从根节点选取。如果我不想每次都从HTML元素出发,想直接取到Body元素,可以使用双斜杠(//),它表示直接命中待选择元素,而不考虑位置,如//body可以直接取到Body元素。

获取到节点的属性,可以使用@符号
[例1]
//h1/a/@id :获取所有h1元素直接子元素a的id属性。
获取节点的文本,使用text()函数
[例1]
//h1/a/text():获取所有h1元素直接子元素a的文本内容。
1.2、XPath的基本实例
我们以一个简易的类HTML文档,来进行实例分析。
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
[例1]
bookstore :选取 bookstore 元素的所有子节点。
[例2]
/bookstore :选取根节点bookstore,这是绝对路径写法。
[例3]
bookstore/book :选取所有属于 bookstore 的子元素的 book元素,这是相对路径写法。
[例4]
//book :选择所有 book 子元素,而不管它们在文档中的位置。
[例5]
bookstore//book :选择所有属于 bookstore 元素的后代的 book 元素,而不管它们位于 bookstore 之下的什么位置。
[例6]
//@lang :选取所有名为 lang 的属性。
2、XPath的谓语条件
谓语用来在查询的时候设置条件,来达到筛选的效果。
2.1、设置返回的节点数量

2.2、根据节点的属性或属性值来返回节点
[例1]
//div[@class] :选择文档中的所有拥有class属性的div节点。
[例2]
//div[@class='postTitle']:选择文档中的所有拥有class属性且值为postTitle的div节点。
2.3、根据节点是否有特点子元素来返回节点
[例1]
//div[a] :选择文档中的所有拥有a子元素的div节点。
3、XPath的通配符
"*"表示匹配任何元素节点。"@*"表示匹配任何属性值。node()表示匹配任何类型的节点。
[例1]
//* :选择文档中的所有元素节点。
[例2]
/*/* :表示选择所有第二层的元素节点。
[例3]
/HTML/* :表示选择HTML的所有元素子节点。
[例4]
//title[@*] :表示选择所有带有属性的title元素。
[例5]
//book/title | //book/price :表示同时选择book元素的title子元素和price子元素。
Scrapy:学习笔记(1)——XPath的更多相关文章
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- XML学习笔记6——XPath语言
在上一篇笔记的结尾,我们接触到了两个用于选择XML文档中特定范围的元素<selector>和<field>,这两个元素的取值都是XPath表达式,那么,什么是XPath呢?简单 ...
- scrapy学习笔记(1)
初探scrapy,发现很多入门教程对应的网址都失效或者改变布局了,走了很多弯路.于是自己摸索做一个笔记. 环境是win10 python3.6(anaconda). 安装 pip install sc ...
- Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识 class scrapy.spiders.CrawlSpider 这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够 ...
- scrapy 学习笔记2
本章学习爬虫的 回调和跟踪链接 使用参数 回调和跟踪链接 上一篇的另一个爬虫,这次是为了抓取作者信息 # -*- coding: utf-8 -*- import scrapy class Myspi ...
- scrapy学习笔记一
以前写爬虫都是直接手写获取response然后用正则匹配,被大佬鄙视之后现在决定开始学习scrapy 一.安装 pip install scrapy 二.创建项目 scrapy startprojec ...
- Scrapy 学习笔记(一)数据提取
Scrapy 中常用的数据提取方式有三种:Css 选择器.XPath.正则表达式. Css 选择器 Web 中的 Css 选择器,本来是用于实现在特定 DOM 元素上应用花括号内的样式这样一个功能的. ...
- scrapy 学习笔记
1.scrapy 配合 selenium.phantomJS 抓取动态页面, 单纯的selemium 加 Firefox浏览器就可以抓取动态页面了, 但开启窗口太耗资源,而且一般服务器的linux 没 ...
随机推荐
- MySql阶段案例
MySql阶段案例 案例一 涉及的知识点:数据库和表的基本操作,添加数据,多表操作 题目 使用sql语句请按照要求完成如下操作: (1)创建一个名称为test的数据库. (2)在test数据库中创建两 ...
- python2.0_day19_后台数据库设计思路
from django.db import models # Create your models here. from django.contrib.auth.models import User ...
- mongoDB在windows64上安装
1.下载64位:mongodb-win32-x86_64-enterprise-windows-64-2.6.4-signed.msi 2.安装目录:将应用安装到此目录下面:C:\MongoDB\ 3 ...
- UITextView 实现placeholder的方法
本文转载至 http://www.cnblogs.com/easonoutlook/archive/2012/12/28/2837665.html 在UITextField中自带placeholder ...
- PyQt4工具栏
工具栏 菜单对程序中的所有命令进行分组防治,而工具栏则提供了快速执行最常用命令的方法. #!/usr/bin/python # -*- coding:utf-8 -*- import sys from ...
- poj_1442 Treap
Treap是一种动态平衡二叉树结构,具有期望的O(log2n)的复杂度.适用于动态区间数据的查询.更改.维护等操作. 题目大意 一组数从前向后插入队列中,插入的过程中会有查询,查询当前队列中的第k小的 ...
- 关于线上js报错问题的思考
1.有没有可能对线上报错进行实时监控,只要线上报错出现就会以邮件的形式发出来. 2.有没有可能将每个模块和开发者联系起来,只要报错就直接报给开发者
- Linux数据链路层的包解析
仅以此文作为学习笔记,初学者,如有错误欢迎批评指正,但求轻喷.一般而言,Linux系统截获数据包后,会通过协议栈,按照TCP/IP层次进行解析,那我们如何直接获得更为底层的数据报文呢,这里用到一个类型 ...
- 【BZOJ1040】[ZJOI2008]骑士 树形DP
[BZOJ1040][ZJOI2008]骑士 Description Z国的骑士团是一个很有势力的组织,帮会中汇聚了来自各地的精英.他们劫富济贫,惩恶扬善,受到社会各界的赞扬.最近发生了一件可怕的事情 ...
- angularJS的过滤器!
angularJS过滤器: filter currency date filter json limitTo lowercase number orderBy uppercase ...... Fil ...