Scrapy:学习笔记(1)——XPath
Scrapy:学习笔记(1)——XPath
1、快速开始
XPath是一种可以快速在HTML文档中选择并抽取元素、属性和文本的方法。
在Chrome,打开开发者工具,可以使用$x工具函数来使用XPath来选择元素,比如选中所有的超链接。
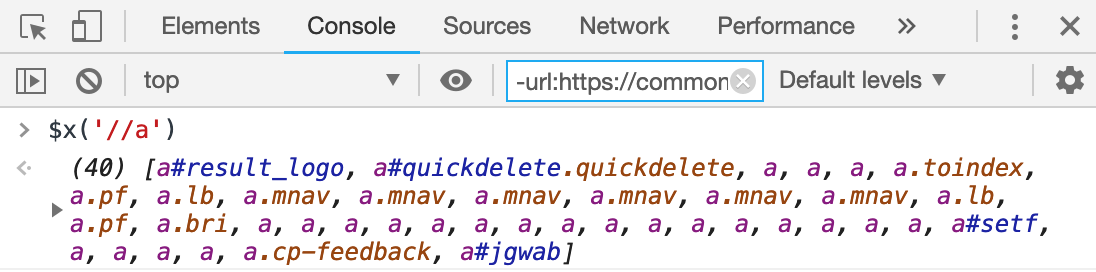
1.1、XPath的基本格式
XPath通过"路径表达式"(Path Expression)来选择节点。
在形式上,"路径表达式"与传统的文件系统非常类似。

比如我们依次获得Html节点(即最根节点)、Html下的Body节点、Html下的Body下的所有Div节点。
单斜杠与双斜杠:
在这里我们使用了单斜杠(/)作为最开始的元素,表示从根节点选取。如果我不想每次都从HTML元素出发,想直接取到Body元素,可以使用双斜杠(//),它表示直接命中待选择元素,而不考虑位置,如//body可以直接取到Body元素。

获取到节点的属性,可以使用@符号
[例1]
//h1/a/@id :获取所有h1元素直接子元素a的id属性。
获取节点的文本,使用text()函数
[例1]
//h1/a/text():获取所有h1元素直接子元素a的文本内容。
1.2、XPath的基本实例
我们以一个简易的类HTML文档,来进行实例分析。
<bookstore>
<book>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book>
<title lang="eng">Learning XML</title>
<price>39.95</price>
</book>
</bookstore>
[例1]
bookstore :选取 bookstore 元素的所有子节点。
[例2]
/bookstore :选取根节点bookstore,这是绝对路径写法。
[例3]
bookstore/book :选取所有属于 bookstore 的子元素的 book元素,这是相对路径写法。
[例4]
//book :选择所有 book 子元素,而不管它们在文档中的位置。
[例5]
bookstore//book :选择所有属于 bookstore 元素的后代的 book 元素,而不管它们位于 bookstore 之下的什么位置。
[例6]
//@lang :选取所有名为 lang 的属性。
2、XPath的谓语条件
谓语用来在查询的时候设置条件,来达到筛选的效果。
2.1、设置返回的节点数量

2.2、根据节点的属性或属性值来返回节点
[例1]
//div[@class] :选择文档中的所有拥有class属性的div节点。
[例2]
//div[@class='postTitle']:选择文档中的所有拥有class属性且值为postTitle的div节点。
2.3、根据节点是否有特点子元素来返回节点
[例1]
//div[a] :选择文档中的所有拥有a子元素的div节点。
3、XPath的通配符
"*"表示匹配任何元素节点。"@*"表示匹配任何属性值。node()表示匹配任何类型的节点。
[例1]
//* :选择文档中的所有元素节点。
[例2]
/*/* :表示选择所有第二层的元素节点。
[例3]
/HTML/* :表示选择HTML的所有元素子节点。
[例4]
//title[@*] :表示选择所有带有属性的title元素。
[例5]
//book/title | //book/price :表示同时选择book元素的title子元素和price子元素。
Scrapy:学习笔记(1)——XPath的更多相关文章
- Scrapy:学习笔记(2)——Scrapy项目
Scrapy:学习笔记(2)——Scrapy项目 1.创建项目 创建一个Scrapy项目,并将其命名为“demo” scrapy startproject demo cd demo 稍等片刻后,Scr ...
- scrapy 学习笔记1
最近一段时间开始研究爬虫,后续陆续更新学习笔记 爬虫,说白了就是获取一个网页的html页面,然后从里面获取你想要的东西,复杂一点的还有: 反爬技术(人家网页不让你爬,爬虫对服务器负载很大) 爬虫框架( ...
- XML学习笔记6——XPath语言
在上一篇笔记的结尾,我们接触到了两个用于选择XML文档中特定范围的元素<selector>和<field>,这两个元素的取值都是XPath表达式,那么,什么是XPath呢?简单 ...
- scrapy学习笔记(1)
初探scrapy,发现很多入门教程对应的网址都失效或者改变布局了,走了很多弯路.于是自己摸索做一个笔记. 环境是win10 python3.6(anaconda). 安装 pip install sc ...
- Scrapy学习笔记(5)-CrawlSpider+sqlalchemy实战
基础知识 class scrapy.spiders.CrawlSpider 这是抓取一般网页最常用的类,除了从Spider继承过来的属性外,其提供了一个新的属性rules,它提供了一种简单的机制,能够 ...
- scrapy 学习笔记2
本章学习爬虫的 回调和跟踪链接 使用参数 回调和跟踪链接 上一篇的另一个爬虫,这次是为了抓取作者信息 # -*- coding: utf-8 -*- import scrapy class Myspi ...
- scrapy学习笔记一
以前写爬虫都是直接手写获取response然后用正则匹配,被大佬鄙视之后现在决定开始学习scrapy 一.安装 pip install scrapy 二.创建项目 scrapy startprojec ...
- Scrapy 学习笔记(一)数据提取
Scrapy 中常用的数据提取方式有三种:Css 选择器.XPath.正则表达式. Css 选择器 Web 中的 Css 选择器,本来是用于实现在特定 DOM 元素上应用花括号内的样式这样一个功能的. ...
- scrapy 学习笔记
1.scrapy 配合 selenium.phantomJS 抓取动态页面, 单纯的selemium 加 Firefox浏览器就可以抓取动态页面了, 但开启窗口太耗资源,而且一般服务器的linux 没 ...
随机推荐
- C51中遇到一个有关data与xdata的问题,已解决
环境: 我在某个C文件定义了一个结构体变量,然后该变量仅仅是在本文件内被一个函数使用,然后又在中断中调用了该函数,目的是改变一个IO口的输出状态,结果运行时怎么也达不到要的效果. struct BE ...
- Python 中文乱码
1.首行添加 # -*- coding:gb2312 -*- # -*- coding:utf-8 -*- 2.PyCharm设置 在File->setting->File Encodin ...
- Effective C++ —— 设计与声明(四)
条款18 : 让接口容易被正确使用,不易被误用 欲开发一个“容易被正确使用,不容易被误用”的接口,首先必须考虑客户可能做出什么样的错误操作. 1. 明智而审慎地导入新类型对预防“接口被误用”有神奇疗 ...
- js里面函数的内部属性
1.arguments用來存放传输参数的集合,可以被调用多次,每次数組都不一样,增强了函数的强壮性 实例: function calc() { var sum = 0; /*参数为一个时候*/ if ...
- Oracle 11G Client 客户端安装步骤(图文详解)
http://www.cnblogs.com/jiguixin/archive/2011/09/09/2172672.html 下载地址: http://download.oracle.com/otn ...
- qq邮箱发送,mail from address must be same as authorization user
由于邮箱发送的邮箱账号更换,所以重新测试.结果一直出错,要不就是请求超时,要不就是未授权. 用smtp 开始的时候,端口使用495,结果是请求超时. 后来改成25,结果是未授权. 再后来听人说,有一个 ...
- WinForm软件开机自动启动详细方法
现在正在制作一个物资公司的管理软件,把自己掌握的学到的一点点细细的讲给喜欢C#的同仁们,互相交流. 想要给你制作的应用程序做一个开机启动,很方便,你可以让用户选择,在你的工具栏中的某个下拉菜单里添加一 ...
- stringstream读入每行数据
做了下阿里的编程测试题,就30分钟,不是正常的输入输入,直接给一个数组作为输入. 于是带想题和处理数据花了20分钟,最后10分钟搞一个dij模版, 竟然只过了66%,应该是我数组开小了. 题目数据量没 ...
- Shell脚步之监控iostat数据
在性能测试中,进行iostat监控数据显示太不美观,看起来很痛苦,如下图 为了显示美观,写个shell脚本进行改造,如下: #! /bin/bash interval= ]; then interva ...
- 国外DNS服务器总结
国外12个免费的DNS DNS(即Domain Name System,域名系统),是因特网上作为域名和IP地址相互映射的一个分布式数据库,能够让用户更方便的访问互联网,而不用去记住能够被机器直接读取 ...