Spring Cloud Sleuth Zipkin - (1)
最近在学习spring cloud构建微服务,很多大牛都提供很多入门的例子帮助我们学习,对于我们这种英语不好的码农来说,效率着实提高不少。这两天学习到追踪微服务rest服务调用链路的问题,接触到zipkin,而spring cloud也提供了spring-cloud-sleuth来方便集成zipkin实现。
在网络上找了好多文章,不过发现版本引入的maven依赖包,配置的参数都不完全相同。可能是因为版本更新太快 的原因,部分配置已经取消掉了。光看不动手始终是不够的,于是自己根据其他大神的博客以及github上作者的示例来自己练手试试。
我们准备了三个必要的程序来做测试,分别是
1、zipkin-server
负责数据收集以及信息展示功能。
2、provider
负责微服务的生产者,对外提供 “http://127.0.0.1:10001/add/被加数/加数” 的rest地址来完成一个简单的两整数相加的功能。
3、consumer
负责微服务的调用,对外提供 "http://127.0.0.1:10002/test/add/被加数/加数" 的rest地址,当访问此地址时,使用feign方式调用provider的rest服务地址。得到计算结果后,显示在界面上。
三个程序功能非常简单,接下来我们看看每个程序的具体代码和配置。为了方便我们对三个模块开发,我们在父POM文件中添加了spring-boot和spring-cloud的依赖,避免子模块中需要写版本号
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.1.RELEASE</version>
</parent>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Dalston.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>接下来我们看看三个程序中的相关配置
一、zipkin-server
首先,我们添加maven依赖配置
<dependencies>
<!--使用@EnableZipkinServer注解方式只需要依赖如下两个包-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<scope>runtime</scope>
</dependency>
<!--保存到数据库需要如下依赖-->
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-mysql</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>线下测试环境中,我们可以将数据保存到内存中,但是生产环境还是需要将数据持久化中。原生支持了很多产品,例如ES、数据库等,本例中我们采用持久化到mysql中的方式来演示。
我们写一个启动类ZipkinServer,代码非常简单,如下
@SpringBootApplication
@EnableZipkinServer //启动ZipkinServer段
public class ZipkinServer {
public static void main(String[] args) {
SpringApplication.run(ZipkinServer.class, args);
}
}接下来我们配置application.properties配置文件
server.port=9411
spring.application.name=zipkin-server
#zipkin数据保存到数据库中需要进行如下配置
#表示当前程序不使用sleuth
spring.sleuth.enabled=false
#表示zipkin数据存储方式是mysql
zipkin.storage.type=mysql
#数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素
spring.datasource.schema[0]=classpath:/zipkin.sql
#spring boot数据源配置
spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.datasource.username=root
spring.datasource.password=123456
spring.datasource.driver-class-name=com.mysql.jdbc.Driver
spring.datasource.initialize=true
spring.datasource.continue-on-error=true从以上配置可以看到我们创建了一个 zipkin的数据库,初始化脚本为classpath下的zipkin.sql的sql文件。具体内容见附件。
启动后 无异常输出,这样我们的zipkin-server程序就OK了

二、provider和consumer
provider和consumer两个程序,与其他基础代码我们就不多讲了(相信学些到这一步的童鞋,都已经对spring cloud创建微服务以上手了),两个程序在spring-cloud-sleuth相关的配置都是一样。
首先,我们要在二者的POM文件中添加依赖,引入zipkin客户端自动配置相关依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>其次,在配置文件application中,我们加入zipkin-server收集信息的地址
#配置zipKin Server的地址
spring.zipkin.base-url=http://127.0.0.1:9411这样我们的两个微服务就配置好了(注意这里我们并不会再说明如何写rest接口和使用feign调用rest接口)
三、测试
启动我们的三个程序。然后访问zipkin-server程序的UI界面地址http://127.0.0.1:9411,可以看到如下的效果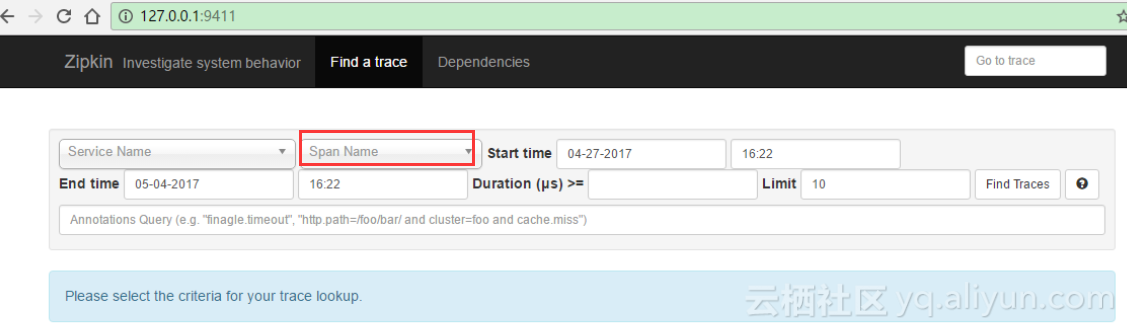
其中Span Name选项为灰色不可选,说明目前没有数据,我们查看数据库也可以看到没有任何数据信息。接下来我们访问consumer提供的访问地址 “http://127.0.0.1:10001/add/被加数/加数” 刷新几次之后,我们再次刷新我们的zipkin界面,可以看到Span Name已经可以选择了。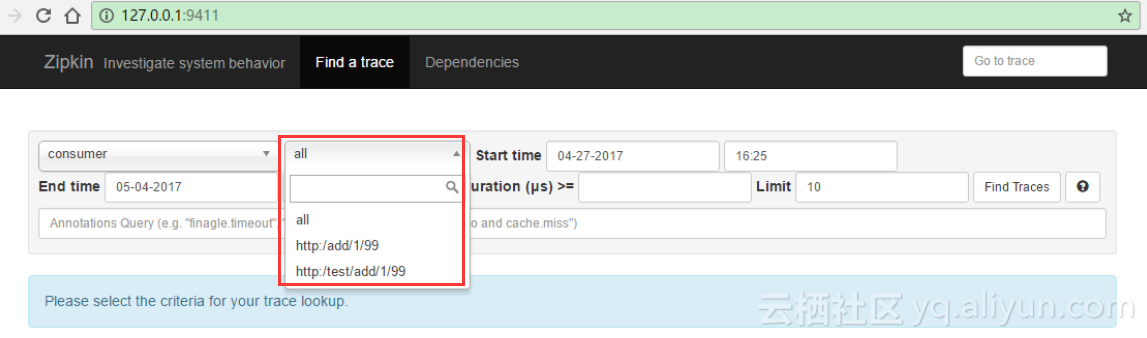
点击Find Traces按钮,我们可以看到调用的链路和耗时情况,点击Dependencies,我们可以看到provider和consumer的调用图
OK,我们的简单实用spring-cloud-sleuth+zipkin的例子就完成了。
注意:
测试时请将consumer访问地址中的“被加数”和“加数”替换为两个整数。
四、拓展
在测试的过程中我们会发现,有时候,程序刚刚启动后,刷新几次,并不能看到任何数据,原因就是我们的spring-cloud-sleuth收集信息是有一定的比率的,默认的采样率是0.1,配置此值的方式在配置文件中增加spring.sleuth.sampler.percentage参数配置(如果不配置默认0.1),如果我们调大此值为1,可以看到信息收集就更及时。但是当这样调整后,我们会发现我们的rest接口调用速度比0.1的情况下慢了很多,即时在0.1的采样率下,我们多次刷新consumer的接口,也会出现如下情况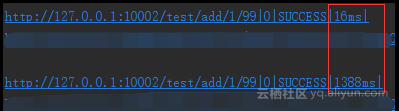
红色框中上下两个数据是两次耗时信息,可以看到相差非常大,如果取消spring-cloud-sleuth后我们再测试,会发现并没有这种情况,可以看到这种方式追踪服务调用链路会给我们业务程序性能带来一定的影响。
其实,我们仔细想想也可以总结出这种方式的几种缺陷
缺陷1:zipkin客户端向zipkin-server程序发送数据使用的是http的方式通信,每次发送的时候涉及到连接和发送过程。
缺陷2:当我们的zipkin-server程序关闭或者重启过程中,因为客户端收集信息的发送采用http的方式会被丢失。
针对以上两个明显的缺陷,改进的办法是
1、通信采用socket或者其他效率更高的通信方式。
2、客户端数据的发送尽量减少业务线程的时间消耗,采用异步等方式发送收集信息。
3、客户端与zipkin-server之间增加缓存类的中间件,例如redis、MQ等,在zipkin-server程序挂掉或重启过程中,客户端依旧可以正常的发送自己收集的信息。
相信采用以上三种方式会很大的提高我们的效率和可靠性。其实spring-cloud以及为我们提供采用MQ或redis等其他的采用socket方式通信,利用消息中间件或数据库缓存的实现方式。下一次我们再来测试spring-cloud-sleuth-zipkin-stream方式的实现。
参考文档:
https://github.com/spring-cloud/spring-cloud-sleuth
菜鸟学文,望大侠指正。
另外附上sql脚本:
Spring Cloud Sleuth Zipkin - (1)的更多相关文章
- Spring Cloud Alibaba学习笔记(23) - 调用链监控工具Spring Cloud Sleuth + Zipkin
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求陷入性能瓶颈或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何 ...
- 分布式链路追踪之Spring Cloud Sleuth+Zipkin最全教程!
大家好,我是不才陈某~ 这是<Spring Cloud 进阶>第九篇文章,往期文章如下: 五十五张图告诉你微服务的灵魂摆渡者Nacos究竟有多强? openFeign夺命连环9问,这谁受得 ...
- Spring Cloud 微服务六:调用链跟踪Spring cloud sleuth +zipkin
前言:随着微服务系统的增加,服务之间的调用关系变得会非常复杂,这给运维以及排查问题带来了很大的麻烦,这时服务调用监控就显得非常重要了.spring cloud sleuth实现了对分布式服务的监控解决 ...
- Spring Cloud Sleuth+ZipKin+ELK服务链路追踪(七)
序言 sleuth是spring cloud的分布式跟踪工具,主要记录链路调用数据,本身只支持内存存储,在业务量大的场景下,为拉提升系统性能也可通过http传输数据,也可换做rabbit或者kafka ...
- Spring Cloud Sleuth + Zipkin 链路监控
原文:https://blog.csdn.net/hubo_88/article/details/80878632 在微服务系统中,随着业务的发展,系统会变得越来越大,那么各个服务之间的调用关系也就变 ...
- 全链路spring cloud sleuth+zipkin
http://blog.csdn.net/qq_15138455/article/details/72956232 版权声明:@入江之鲸 一.About ZipKin please google 二. ...
- Spring Cloud Sleuth Zipkin - (2)
在上一节<spring-cloud-sleuth+zipkin追踪服务实现(一)>中,我们使用zipkin-server.provider.consumer三个程序实现了使用http方式进 ...
- springcloud --- spring cloud sleuth和zipkin日志管理(spring boot 2.18)
前言 在spring cloud分布式架构中,系统被拆分成了许多个服务单元,业务复杂性提高.如果出现了异常情况,很难定位到错误位置,所以需要实现分布式链路追踪,跟进一个请求有哪些服务参与,参与的顺序如 ...
- spring boot 2.0.3+spring cloud (Finchley)7、服务链路追踪Spring Cloud Sleuth
参考:Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] Spring Cloud Sleuth 是Spring Cloud的一个组件,主要功能是 ...
随机推荐
- MongoDB联合查询 -摘自网络
1.简单手工关联 首先将结果查询出来放到一个变量里面,然后再查询 u = db.user.findOne({author:"wangwenlong"}); for(var p = ...
- Oozie介绍
1. Hadoop常见调度框架: (1)Linux Crontab:Linux自带的任务调度计划,在任务比较少的情况下,可以使用这种方式,直接执行脚本,例如添加一个执行计划: 0 12 * hive ...
- Unity GPU Instancing的使用尝试
似乎是在Unity5.4中开始支持GPU Instacing,但如果要比较好的使用推荐用unity5.6版本,因为这几个版本一直在改. 这里测试也是使用unity5.6.2进行测试 在5.6的版本里, ...
- Win7下使用无线网卡共享上网的4种方式
我尝试了第一种直接上网了 一.Win7自带无线承载网络功能 1.查看网卡是否支持承载网络功能运行“命令提示符” 输入命令:netsh wlan show drivers图中红框“支持的承载 ...
- 使用 nw-builder 构建跨平台桌面应用程序
NW.js 是一个使用 Web 技术创建本地应用的框架,如 HTML.JavaScript 和 CSS.简单地说,当你在使用普通的流程开发一个 Web 应用时,开发完成后,运行一个生成器,将所有东西编 ...
- CSS中字体响应式的设置
在进行页面响应式设计中,往往需要根据屏幕分辨率来显示不同大小的字体.通常的做法是通过media queries给不同的分辨率指定不同的字体样式,例如: body { font-size: 22px; ...
- ExtJs--05--给window组件加入功能条以及子组件获取上级或下级组件的属性和方法
Ext.onReady(function(){ /** 1-- 给容器组件加入控制条 及 控制项 控制条 不同的方向有多种 tbar lbar rbar bbar fbar 2-- 依据组件本身拿到上 ...
- spring cloud 项目相关集成简介
Spring Cloud Config 配置管理工具包,让你可以把配置放到远程服务器,集中化管理集群配置,目前支持本地存储.Git以及Subversion. Spring Cloud Bus 事件.消 ...
- CCShatteredTiles3D
CCSprite* pImgBg = CCSprite::create("1.png"); pImgBg->setPosition(ccp(CCDirector::share ...
- VS生成后事件对文件的copy以及更换扩展名
在VC++2012的项目里,属性内有生成事件. 可以用后期生成事件命令行做一些生成之后的事情,比如对编译出的.dll,.lib,.pdb等文件进行copy或者更改扩展名. 我用到的就是将和项目同名的. ...