文本相似度-BM25算法
BM25 is a bag-of-words retrieval function that ranks a set of documents based on the query terms appearing in each document, regardless of the inter-relationship between the query terms within a document (e.g., their relative proximity). It is not a single function, but actually a whole family of scoring functions, with slightly different components and parameters. One of the most prominent instantiations of the function is as follows.
BM25算法,通常用来作搜索相关性平分。一句话概况其主要思想:对Query进行语素解析,生成语素qi;然后,对于每个搜索结果D,计算每个语素qi与D的相关性得分,最后,将qi相对于D的相关性得分进行加权求和,从而得到Query与D的相关性得分。
BM25算法的一般性公式如下:
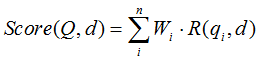
其中,Q表示Query,qi表示Q解析之后的一个语素(对中文而言,我们可以把对Query的分词作为语素分析,每个词看成语素qi。);d表示一个搜索结果文档;Wi表示语素qi的权重;R(qi,d)表示语素qi与文档d的相关性得分。
下面我们来看如何定义Wi。判断一个词与一个文档的相关性的权重,方法有多种,较常用的是IDF。这里以IDF为例,公式如下:
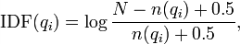
其中,N为索引中的全部文档数,n(qi)为包含了qi的文档数。
根据IDF的定义可以看出,对于给定的文档集合,包含了qi的文档数越多,qi的权重则越低。也就是说,当很多文档都包含了qi时,qi的区分度就不高,因此使用qi来判断相关性时的重要度就较低。
我们再来看语素qi与文档d的相关性得分R(qi,d)。首先来看BM25中相关性得分的一般形式:
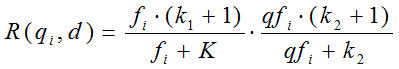
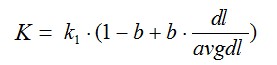
其中,k1,k2,b为调节因子,通常根据经验设置,一般k1=2,b=0.75;fi为qi在d中的出现频率,qfi为qi在Query中的出现频率。dl为文档d的长度,avgdl为所有文档的平均长度。由于绝大部分情况下,qi在Query中只会出现一次,即qfi=1,因此公式可以简化为:
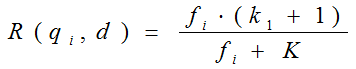
从K的定义中可以看到,参数b的作用是调整文档长度对相关性影响的大小。b越大,文档长度的对相关性得分的影响越大,反之越小。而文档的相对长度越长,K值将越大,则相关性得分会越小。这可以理解为,当文档较长时,包含qi的机会越大,因此,同等fi的情况下,长文档与qi的相关性应该比短文档与qi的相关性弱。
综上,BM25算法的相关性得分公式可总结为:
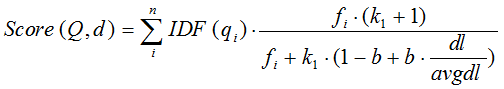
从BM25的公式可以看到,通过使用不同的语素分析方法、语素权重判定方法,以及语素与文档的相关性判定方法,我们可以衍生出不同的搜索相关性得分计算方法,这就为我们设计算法提供了较大的灵活性。
原文地址:http://ipie.blogbus.com/logs/104136815.html
文本相似度-BM25算法的更多相关文章
- 从0到1,了解NLP中的文本相似度
本文由云+社区发表 作者:netkiddy 导语 AI在2018年应该是互联网界最火的名词,没有之一.时间来到了9102年,也是项目相关,涉及到了一些AI写作相关的功能,为客户生成一些素材文章.但是, ...
- 【NLP】Python实例:基于文本相似度对申报项目进行查重设计
Python实例:申报项目查重系统设计与实现 作者:白宁超 2017年5月18日17:51:37 摘要:关于查重系统很多人并不陌生,无论本科还是硕博毕业都不可避免涉及论文查重问题,这也对学术不正之风起 ...
- 文本相似度 — TF-IDF和BM25算法
1,$TF-IDF$算法 $TF$是指归一化后的词频,$IDF$是指逆文档频率.给定一个文档集合$D$,有$d_1, d_2, d_3, ......, d_n \in D$.文档集合总共包含$m$个 ...
- 文本相似度算法——空间向量模型的余弦算法和TF-IDF
1.信息检索中的重要发明TF-IDF TF-IDF是一种统计方法,TF-IDF的主要思想是,如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分 ...
- 4. 文本相似度计算-CNN-DSSM算法
1. 文本相似度计算-文本向量化 2. 文本相似度计算-距离的度量 3. 文本相似度计算-DSSM算法 4. 文本相似度计算-CNN-DSSM算法 1. 前言 之前介绍了DSSM算法,它主要是用了DN ...
- 3. 文本相似度计算-DSSM算法
1. 文本相似度计算-文本向量化 2. 文本相似度计算-距离的度量 3. 文本相似度计算-DSSM算法 4. 文本相似度计算-CNN-DSSM算法 1. 前言 最近在学习文本相似度的计算,前面两篇文章 ...
- 文本相似度 余弦值相似度算法 VS L氏编辑距离(动态规划)
设置n为字符串s的长度.("我是个小仙女") 设置m为字符串t的长度.("我不是个小仙女") 如果n等于0,返回m并退出.如果m等于0,返回n并退出.构造两个向 ...
- DSSM算法-计算文本相似度
转载请注明出处: http://blog.csdn.net/u013074302/article/details/76422551 导语 在NLP领域,语义相似度的计算一直是个难题:搜索场景下quer ...
- Finding Similar Items 文本相似度计算的算法——机器学习、词向量空间cosine、NLTK、diff、Levenshtein距离
http://infolab.stanford.edu/~ullman/mmds/ch3.pdf 汇总于此 还有这本书 http://www-nlp.stanford.edu/IR-book/ 里面有 ...
随机推荐
- 【原】Spring整合Redis(第三篇)—盘点SDR搭建中易出现的错误
易错点01:Spring版本过低导致的错误[环境参数]Redis版本:redis-2.4.5-win32-win64Spring原来的版本:4.1.7.RELEASESpring修改后的版本:4.2. ...
- MongoDB的Java驱动使用整理 (转)
MongoDB Java Driver 简单操作 一.Java驱动一致性 MongoDB的Java驱动是线程安全的,对于一般的应用,只要一个Mongo实例即可,Mongo有个内置的连接池(池大小默认为 ...
- STM32 microcontroller system memory boot mode
The bootloader is stored in the internal boot ROM memory (system memory) of STM32 devices. It is pro ...
- 北大 ACM 分类 汇总
1.搜索 //回溯 2.DP(动态规划) 3.贪心 北大ACM题分类2009-01-27 1 4.图论 //Dijkstra.最小生成树.网络流 5.数论 //解模线性方程 6.计算几何 //凸壳.同 ...
- [C# 基础知识系列]专题八: 深入理解泛型(二)
引言: 本专题主要是承接上一个专题要继续介绍泛型的其他内容,这里就不多说了,就直接进入本专题的内容的. 一.类型推断 在我们写泛型代码的时候经常有大量的"<"和"& ...
- AngularJS一个由于未声明对象而报的错
实现这样的一个需求:点击某个按钮,然后显示或隐藏某块区域. 先注册一个AngularJS的一个module: var myApp = angular.module("myApp", ...
- Unity3D实践系列01,创建项目
下载并安装Unity5软件客户端. 打开软件,注册Unity帐号,并用注册帐号登录. 点击"创建Project"按钮. 把项目命名为"My First Unity Pro ...
- mariadb设置初始密码
mariadb设置初始密码 CENTOS7 自带MARIADB数据库.安装的时候可以勾选安装. 当然也可以以后在CENTOS7里面添加安装. MARIADB安装后,默认是没有密码的. 我们需要给ROO ...
- MyBatis-Generator最佳实践
引用地址:http://arccode.net/2015/02/07/MyBatis-Generator%E6%9C%80%E4%BD%B3%E5%AE%9E%E8%B7%B5/ 最近使用MyBati ...
- WordPress主题开发:WP_Query使用分页实例
functions.php加入 <?php function lingfeng_custom_pagenavi( $custom_query,$range = 4 ) { global $pag ...